
1. 使用现有数据集进行分类
图像数据为Oxford-IIIT Pet Dataset(12类猫和25类狗,共37类),这里仅使用原始图片集images.tar.gz
数据准备
import numpy as np
from fastai.vision import *
from fastai.metrics import error_rate
path_img = 'data/pets/images'
bs = 64 #batch size
fnames = get_image_files(path_img) #get filenames(absolute path) from path_img
pat = re.compile(r'/([^/]+)_d+.jpg$') #get labels from filenames(e.g., 'american_bulldog' from 'data/pets/images/american_bulldog_20.jpg')
### ImageDataBunch
### 使用正则表达式pat从图像文件名fnames中提取标签,并和图像对应起来
### ds_tfms: 图像转换(翻转、旋转、裁剪、放大等),用于图像数据增强(data augmentation)
### size: 最终图像尺寸, bs: batch size, valid_pct: train/valid split
### normalize: 使用提供的均值和标准差(每个通道对应一个均值和标准差)对图像数据进行归一化
np.random.seed(2)
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs, valid_pct=0.2).normalize(imagenet_stats)
data.show_batch(rows=3, figsize=(7,6)) #grab a batch and display 3x3 images
模型搭建和训练
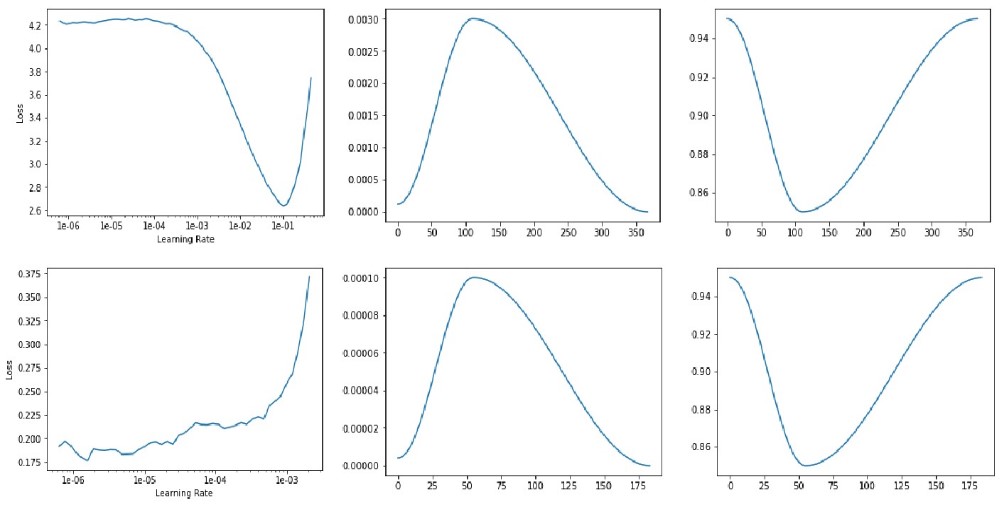
使用Resnet34进行迁移学习,首先通过lr_find确定最大学习率,再通过fit_one_cycle(1-Cycle style)进行训练
lr_find: 在前面几次的迭代中将学习率从一个很小的值逐渐增加,选择损失函数(train loss)处于下降趋势之中并且距离损失停止下降的拐点有一定距离的点做为模型的最大学习率max_lr
fit_one_cycle: 共分为两个阶段,在第一阶段学习率从max_lr/div_factor线性增长到max_lr,momentum线性地从moms[0]降到moms[1];第二阶段学习率以余弦形式从max_lr降为0,momentum也同样按余弦形式从moms[1]增长到moms[0]。第一阶段的迭代次数占总迭代次数的比例为pct_start
学习率和momentum: , , , 其中是要更新的参数,G为梯度, 为学习率, 为momentum
### Use Resnet34 to classify images
learn = create_cnn(data, models.resnet34, metrics=error_rate)
print(learn.model) #model summary
learn.lr_find()
learn.recorder.plot() #由左上图可以看出max_lr可选择函数fit_one_cycle的默认值0.003
learn.fit_one_cycle(4, max_lr=slice(0.003), div_factor=25.0, moms=(0.95, 0.85), pct_start=0.3) #4 epochs
learn.recorder.plot_lr(show_moms=True) #中上图(学习率)和右上图(momentum), x轴表示迭代次数
learn.save('stage-1') #save model
### Unfreeze all the model layers and keep training
learn.unfreeze()
learn.lr_find()
learn.recorder.plot() #左下图
### 由左下图可以看出max_lr可选择1e-6, 但是模型的不同层可以设置不同的学习率加速训练
### 模型的前面几层的学习率设置为max_lr, 后面几层的学习率可以适当增加(例如可以设置成比上一个fit_one_cycle的学习率小一个量级)
### slice(1e-6,1e-4)表示模型每层的学习率由1e-6逐渐增加过渡到1e-4
learn.fit_one_cycle(2, max_lr=slice(1e-6,1e-4), div_factor=25.0, moms=(0.95, 0.85), pct_start=0.3) #2 epochs
learn.recorder.plot_lr(show_moms=True) #中下图(模型最后一层的学习率)和右下图(momentum)
可视化
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix(figsize=(12,12), dpi=60) #confusion matrix
print(interp.most_confused(min_val=2)) #从大到小列出混淆矩阵中非对角线的最大的几个元素
2. 从谷歌图片下载数据并进行分类
获得图片链接
打开谷歌图片,输入想要下载的图像类别,页面上出现的图片即为可下载的图片
打开JavaScript Console(Windows/Linux:Ctrl+Shift+J, Mac:Cmd+Opt+J),运行下面的命令获取图片链接
大专栏 使用fastai完成图像分类 class="nx">urls = Array.from(document.querySelectorAll('.rg_di .rg_meta')).map(el=>JSON.parse(el.textContent).ou);
window.open('data:text/csv;charset=utf-8,' + escape(urls.join('n')));
分别搜索teddy bears、 black bears、 grizzly bears, 将下载的保存链接的文件分别命名为urls_teddys.txt、 urls_black.txt、 urls_grizzly.txt
下载图片
import numpy as np
from fastai.vision import *
from fastai.metrics import error_rate
### 建立目录并下载图片
path = Path('data/bears')
folders = ['teddys', 'black', 'grizzly']
files = 'urls_teddys.txt', 'urls_black.txt', 'urls_grizzly.txt'
for i,folder in enumerate(folders):
dest = path/folder
dest.mkdir(parents=True, exist_ok=True)
download_images(files[i], dest, max_pics=200)
print(path.ls())
### 删除不能被打开的图片
for folder in folders:
verify_images(path/folder, delete=True, max_size=500)
训练模型
np.random.seed(42)
data = ImageDataBunch.from_folder(path, train=".", valid_pct=0.2, ds_tfms=get_transforms(), size=224, bs=64, num_workers=4).normalize(imagenet_stats)
print(data.classes)
learn = create_cnn(data, models.resnet34, metrics=error_rate)
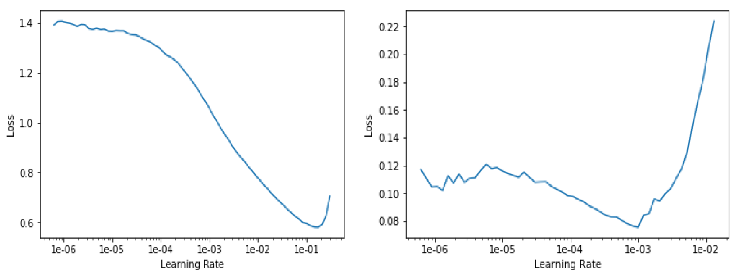
learn.lr_find()
learn.recorder.plot() #左图
learn.fit_one_cycle(4)
learn.save('stage-1')
learn.unfreeze()
learn.lr_find()
learn.recorder.plot() #右图
learn.fit_one_cycle(2, max_lr=slice(3e-5,3e-4)) #若数据量较小,该步不一定有正效果
learn.save('stage-2')
learn.load('stage-1') #选择stage-1
interp = ClassificationInterpretation.from_learner(learn)
interp.plot_confusion_matrix()
根据训练好的模型去除错误图片
模型预测效果不好不一定是因为模型本身的问题,还可能是由于图片自身的问题(例如下载了错误的图片,图片标签有误),需要进行检查和处理
from fastai.widgets import *
### ds: 训练图片集, idxs: 具有最大损失的训练图片索引
ds, idxs = DatasetFormatter().from_toplosses(learn, n_imgs=200) #选出前200个具有最大损失的训练图片
ImageCleaner(ds, idxs, path) #手动处理,处理好的文件被存入path/cleaned.csv(该文件仅包含经过处理后的训练图片集,不包含验证图片)
可根据具体情况对处理之后的数据重新进行训练
保存模型并预测
learn.export() #将模型存入learn.path/export.pkl
learn = load_learner(path) #从path中读取模型
img = open_image(path/'black'/'00000021.jpg') #以训练集中的一个图片为例
pred_class,pred_idx,outputs = learn.predict(img) #预测图片
print(pred_class) #输出类别
print(outputs) #输出每个类的概率