爬静态网站主要分为两部分:
- 爬静态网站的文字
- 爬静态网站的图片
[TOC]
爬文字
思路
- 用
requests模块得到网站的HTML
- 用
BeautifulSoup模块得到HTML的正则文本
- 用
find或者find_all函数从正则文本中得到自己想要的
- 用
repalce去除不需要的字符
源代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
req = requests.get ('http://www.hbrchina.org/2019-02-18/7150.html')
req.encoding = req.apparent_encoding
html = req.text
bf = BeautifulSoup(html,'html.parser')
body = bf.body
texts = body.find_all ('div',{'class':'article-content'})
print(texts[0].text.replace('xa0'*8,'nn'))
|
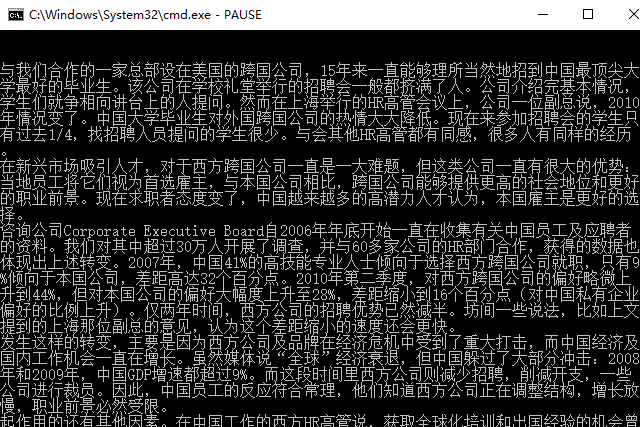
可以看到的结果
爬图片
思路
- 用requests模块得到网站的HTML
- 用BeautifulSoup得到HTML的正则文本
- 用find函数从正则文本中得到自己想要的,比如关键词img
- 利用urllib模块下载
- 利用for语句下载所有图片
源代码
1
2
3
4
5
6
7
8
9
10
11
12
13
大专栏 爬虫-怎么爬静态网站">14
15
16
17
18
19
20
21
|
import requests,urllib
from bs4 import BeautifulSoup
if __name__ == '__main__':
rep = requests.get('https://darerd.github.io/2019/03/21/%E9%9A%8F%E6%83%B3-%E6%96%B0%E9%9B%B6%E5%94%AE%E4%BC%81%E4%B8%9A%E2%80%9C%E2%80%9C%E6%99%BA%E8%83%9C%E2%80%9D%E6%9C%AA%E6%9D%A5/')
rep.encoding = rep.apparent_encoding
html = rep.text
bs = BeautifulSoup(html,'html.parser')
img = bs.find_all('img')
x=1
for i in img :
imgsrc = i.get('src')
urllib.request.urlretrieve(imgsrc,'./%s.jpg' %x)
x=x+1
print ('正在下载: %d '%x)
|
爬虫时必须会用网页源代码
以爬图片为例:
这是我们要爬的网站:[https://darerd.github.io/2019/03/21/随想-新零售企业““智胜”未来/]
打开网站后(我用的Chrome浏览器),键盘快捷键F12,即可打开网站的调试模式,效果如下:
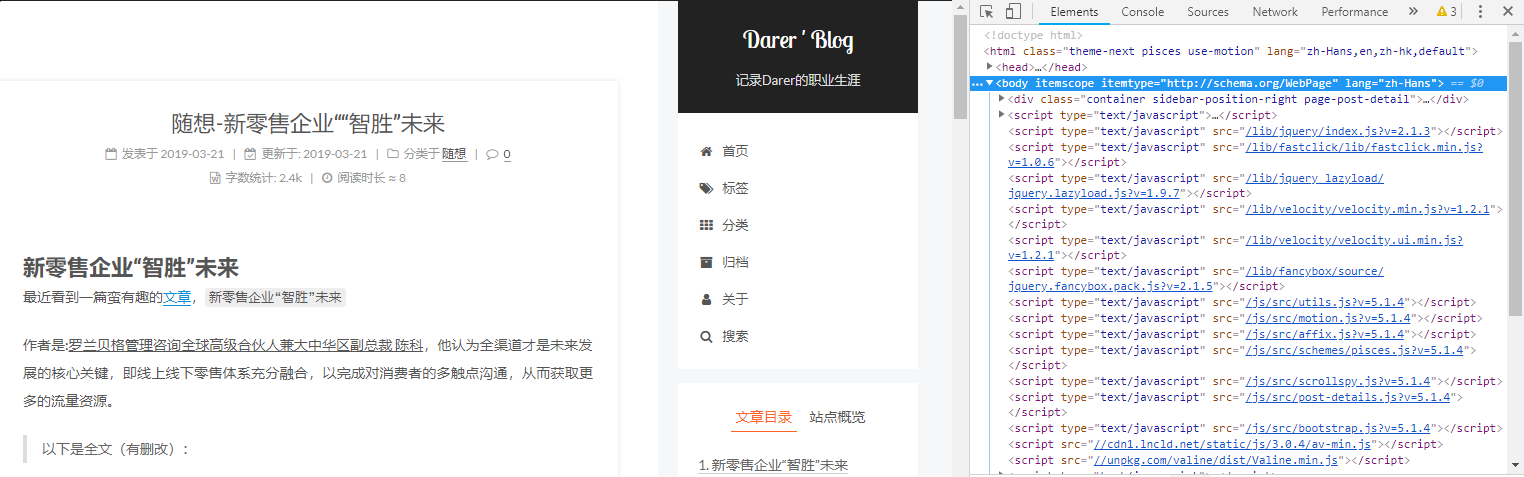
右侧就是网站的源代码,可以用来爬
如果需要快速定位到某一部分的代码所在位置,我们可以鼠标右键,选择检查,如下图所示:

如果我们要快速定位某图片所在的代码位置,演示如下:
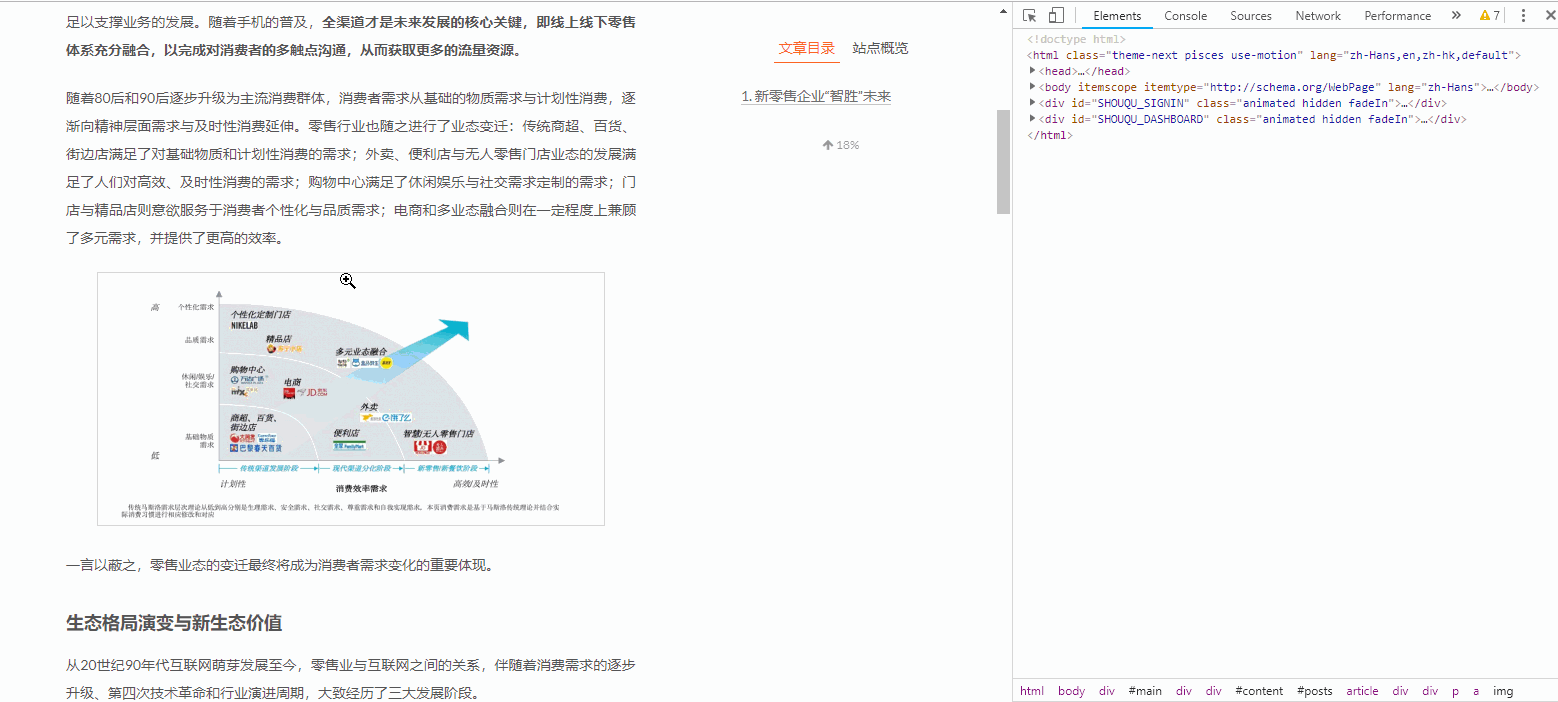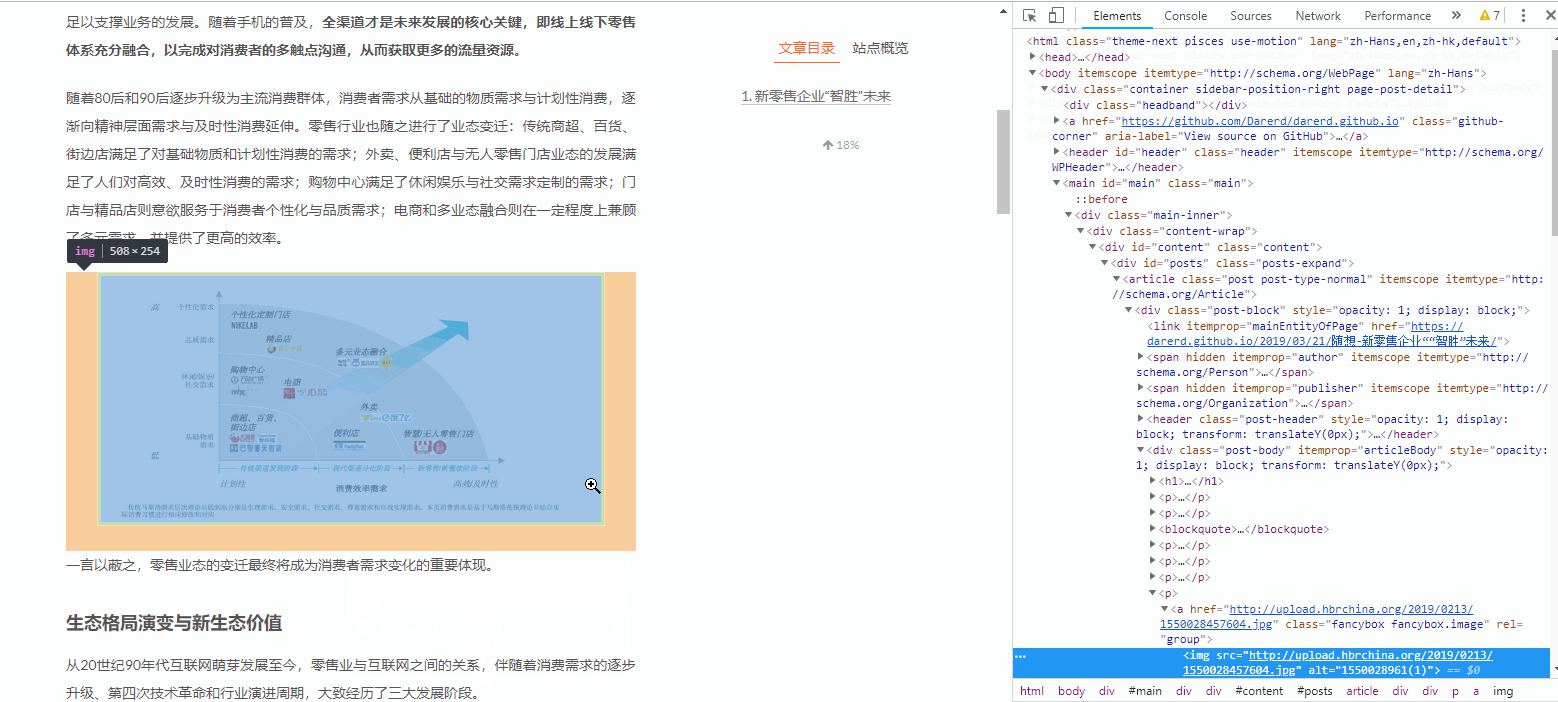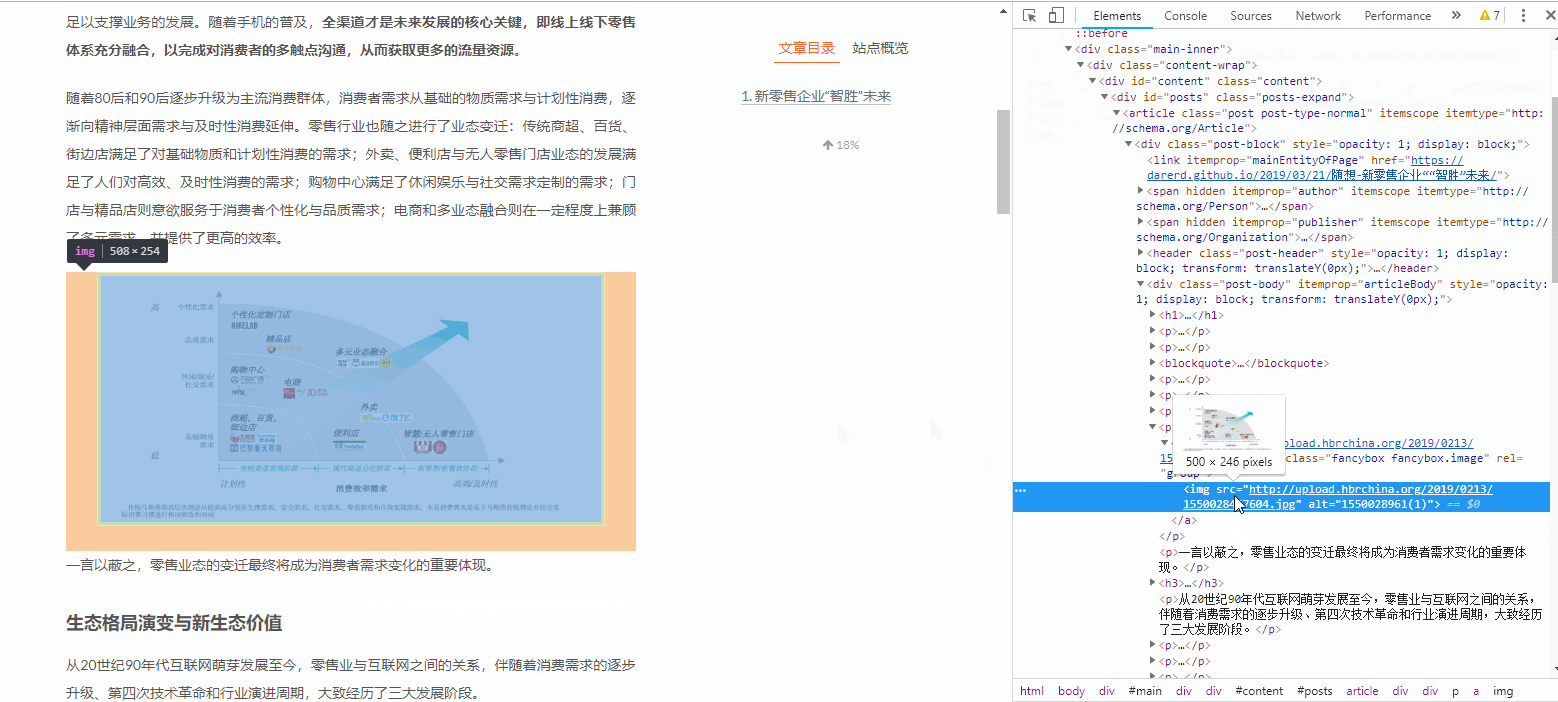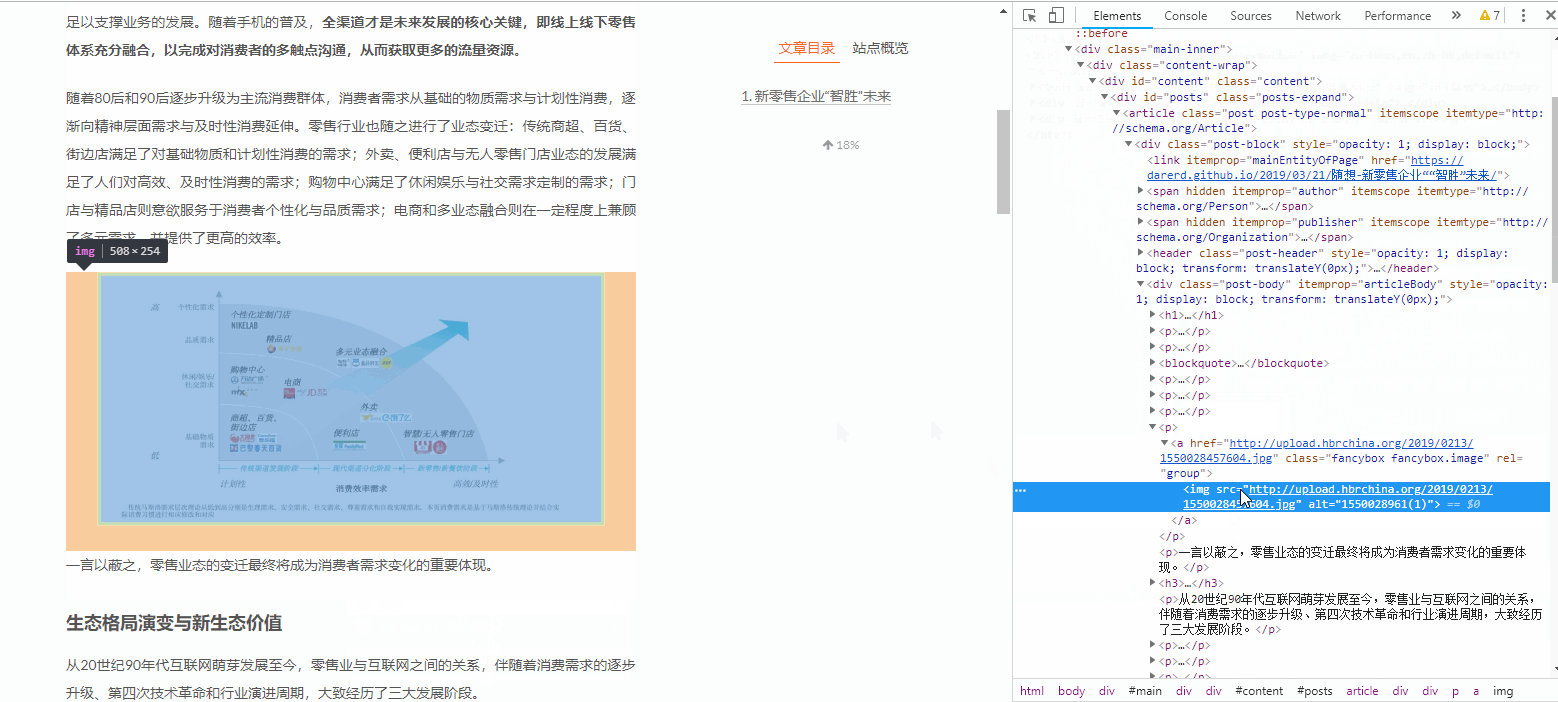
用这种方法观察每一张图片的源码:
它们的写法都是非常类似的,如下:
1
| <img src="http://upload.hbrchina.org/2019/0213/1550028457604.jpg" alt="1550028961(1)">
|
src是图片的下载地址,alt是图片的便签,每一张图片都在img语句中
所以我们只要得到所有的img语句,然后从img语句中得到所有的src链接,就可以下载图片了。
每一种爬虫程序都类似,找到要爬部分的特点,然后调用相应的模块。
对于小白,难度就在于怎么样找到要爬部分的特点
以上