class ():
'''fliter类 n
传入敏感词文件 n
获取用户输入,根据敏感词文件对输入进行过滤
'''
def __init__(self, fileName):
dirty_dict = self.get_dirty(file)
self.fliteredString = self.fliterMaster(dirty_dict)
def get_dirty(self, fileName=''):
'''解析文件获取敏感词,返回一个敏感词列表
'''
with open (fileName, 'r', encoding='utf-8') as f:
re = f.readlines()
for i in range(len(re)):
return(re)
def fliterMaster(self, dirty_dict):
'''过滤主函数 n
获取用户输入,获取待屏蔽词典 n
遍历屏蔽词 ,进行过滤n
返回屏蔽后字符串
'''
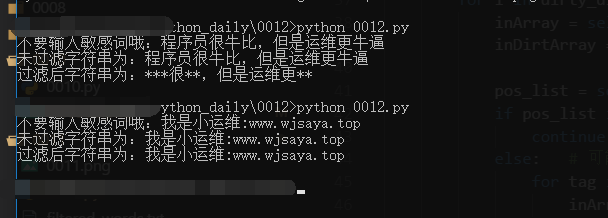
instr = input("不要输入敏感词哦:")
self.originString = instr
for i in dirty_dict:
inArray = self.str2array(instr)
inDirtArray = self.str2array(i)
pos_list = self.get_pos(inArray, inDirtArray[0])
if pos_list is None:
continue
else:
for tag in pos_list:
inArray = self.fliterWorker(tag, inArray, inDirtArray)
instr = ''.join(inArray)
return instr
def str2array(self, instr):
'''字符串单个拆分为数组
'''
redict = []
for i in instr:
redict.append(i)
return redict
def get_pos(self, instr, word):
'''传入句子,传入词 n
找出此词在居中的所有位置
'''
try:
re = instr.index(word)
resp = []
resp.append(re)
while(1):
try:
re = instr.index(word, re+1, len(instr))
resp.append(re)
except Exception as e:
break
return resp
except Exception as e:
return None
def fliterWorker(self, tag, inArray, inDirtArray):
'''IN:字符数组;屏蔽词数组;可能存在屏蔽词的位置 n
OUT:替换完毕之后的字符数组
'''
resp = ""
resp_temp = ""
for i in range(tag):
resp += inArray[i]
for i in range(len(inDirtArray)):
if inArray[tag+i] == inDirtArray[i]:
resp_temp += "*"
else:
resp_temp = ''
break
if resp_temp == '':
return inArray
else:
resp += resp_temp
for i in range(tag+len(inDirtArray), len(inArray)):
resp += inArray[i]
return resp
if __name__ == '__main__':
file = 'filtered_words.txt'
fliter1 = fliter(file)
print("未过滤字符串为:" + fliter1.originString)
print("过滤后字符串为:" + fliter1.fliteredString)