Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Hive与HBase的整合功能的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive_hbase-handler.jar工具类.
Hive和Hbase有各自不同的特征:hive是高延迟、结构化和面向分析的,hbase是低延迟、非结构化和面向编程的。Hive数据仓库在 hadoop上是高延迟的。Hive集成Hbase就是为了使用hbase的一些特性。如下是hive和hbase的集成架构:

图1 hive和hbase架构图
Hive集成HBase可以有效利用HBase数据库的存储特性,如行更新和列索引等。在集成的过程中注意维持HBase jar包的一致性。Hive集成HBase需要在Hive表和HBase表之间建立映射关系,也就是Hive表的列(columns)和列类型 (column types)与HBase表的列族(column families)及列限定词(column qualifiers)建立关联。每一个在Hive表中的域都存在于HBase中,而在Hive表中不需要包含所有HBase中的列。HBase中的 RowKey对应到Hive中为选择一个域使用:key来对应,列族(cf:)映射到Hive中的其它所有域,列为(cf:cq)。例如下图2为Hive 表映射到HBase表:
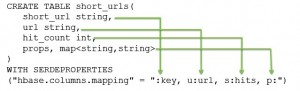
图2 Hive表映射HBase表
PreCondition:
1. 首先将hbase-0.94.12/ 目录下的 hbase-0.94.12.jar 和 hbase-0.94.12/lib下的 zookeeper-3.4.5.jar复制到hive/lib目录下;
注意:如果hive/lib下已经存在这两个文件的其他版本(例如zookeeper-3.3.3.jar),建议删除后使用hbase下的相关版本.
2. 在hive/conf下hive-site.xml文件中添加如下的内容:
如果hive/conf 目录下没有hive-site.xml 则把此目录下的hive-default.xml.template拷贝一份并命名为hive-site.xml;
<property> <name>hbase.zookeeper.quorum</name> <value>Master,Slave1,Slave2</value> </property> <property> <name>hive.aux.jars.path</name> <value>file:///home/landen/UntarFile/hive-0.10.0/lib/LoadJsonData.jar, file:///home/landen/UntarFile/hive-0.10.0/lib/hbase-0.94.12.jar, file:///home/landen/UntarFile/hive-0.10.0/lib/hbase-0.94.12-tests.jar, file:///home/landen/UntarFile/hive-0.10.0/lib/hive-hbase-handler-0.10.0.jar, file:///home/landen/UntarFile/hive-0.10.0/lib/zookeeper-3.4.5.jar, file:///home/landen/UntarFile/hive-0.10.0/lib/protobuf-java-2.4.0a.jar </value>
3. 拷贝hbase-0.94.12.jar到所有hadoop节点(包括master)的/home/landen/UntarFile/hadoop-1.0.4/lib下;
4. 拷贝hbase/conf下的hbase-site.xml文件到所有hadoop节点(包括master)的/home/landen/UntarFile/hadoop-1.0.4/conf下.
具体操作如下:
1> 在HBase中创建一张StuChooseCourse表
hbase(main):002:0> create 'StuChooseCourse'(表名),'StuBasicInfo(列簇)','ChooseCourseInfo(列簇)'
0 row(s) in 3.4070 seconds
hbase(main):003:0> list
TABLE
StuChooseCourse
1 row(s) in 0.0280 seconds
hbase(main):004:0> (插入数据)put 'StuChooseCourse'(表名),'1202000317'(行健),'StuBasicInfo:Name'(列簇:列名标识),'Kelvin'(对应列名标识值)
0 row(s) in 0.1400 seconds
hbase(main):005:0> (查看表信息)scan 'StuChooseCourse'
ROW COLUMN+CELL
1202000317 column=StuBasicInfo:Name, timestamp=1386225265583, value=Kelvin
1 row(s) in 0.0630 seconds
hbase(main):006:0> put 'StuChooseCourse','1202000317','StuBasicInfo:Age','25'
0 row(s) in 0.0670 seconds
hbase(main):007:0> put 'StuChooseCourse','1202000317','StuBasicInfo:Sex','Male'
0 row(s) in 0.0120 seconds
hbase(main):008:0> scan 'StuChooseCourse'
ROW COLUMN+CELL
1202000317 column=StuBasicInfo:Age, timestamp=1386225309188, value=25
1202000317 column=StuBasicInfo:Name, timestamp=1386225265583, value=Kelvin
1202000317 column=StuBasicInfo:Sex, timestamp=1386225341381, value=Male
1 row(s) in 0.0500 seconds
hbase(main):009:0> put 'StuChooseCourse','1202000317','ChooseCourseInfo:Math0001','90'
0 row(s) in 0.1130 seconds
hbase(main):010:0> put 'StuChooseCourse','1202000317','ChooseCourseInfo:Math0002','92'
0 row(s) in 0.0260 seconds
hbase(main):011:0> put 'StuChooseCourse','1202000317','ChooseCourseInfo:Computer0001','95'
0 row(s) in 0.0070 seconds
hbase(main):012:0> put 'StuChooseCourse','1202000317','ChooseCourseInfo:Computer0002','93'
0 row(s) in 0.0080 seconds
hbase(main):013:0> scan 'StuChooseCourse'
ROW COLUMN+CELL
1202000317 column=ChooseCourseInfo:Computer0001, timestamp=1386225449689, value=95
1202000317 column=ChooseCourseInfo:Computer0002, timestamp=1386225457761, value=93
1202000317 column=ChooseCourseInfo:Math0001, timestamp=1386225418849, value=90
1202000317 column=ChooseCourseInfo:Math0002, timestamp=1386225433125, value=92
1202000317 column=StuBasicInfo:Age, timestamp=1386225309188, value=25
1202000317 column=StuBasicInfo:Name, timestamp=1386225265583, value=Kelvin
1202000317 column=StuBasicInfo:Sex, timestamp=1386225341381, value=Male
1 row(s) in 0.0180 seconds
hbase(main):014:0> (获取对应行健值)get 'StuChooseCourse'(表名),'1202000317'(对应行健)
COLUMN CELL
ChooseCourseInfo:Computer0001 timestamp=1386225449689, value=95
ChooseCourseInfo:Computer0002 timestamp=1386225457761, value=93
ChooseCourseInfo:Math0001 timestamp=1386225418849, value=90
ChooseCourseInfo:Math0002 timestamp=1386225433125, value=92
StuBasicInfo:Age timestamp=1386225309188, value=25
StuBasicInfo:Name timestamp=1386225265583, value=Kelvin
StuBasicInfo:Sex timestamp=1386225341381, value=Male
7 row(s) in 0.0350 seconds
hbase(main):015:0>
2> 在Hive中创建一张对应HBase的映射表hbase_stu_course
Note: 此时这个映射表hbase_stu_course实际上是一个虚拟表, 实际的数据还在HBase中。 下面需要在Hive中另建一个结构一样的空表, 再把数据导出来
hive (stuchoosecourse)> create external table hbase_stu_course(
> Stu_num(对应HBase的行健) string comment 'Student number',
> stu_basicinfo map<string,string>(对应HBase中的某一列簇) comment 'include name,age,sex',
> stu_courseInfo map<string,float> comment 'include all choosing course information')
> stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> with serdeproperties ("hbase.columns.mapping" = ":key(对应Stu_num作为行健),StuBasicInfo:(整个列簇),ChooseCourseInfo:")
> tblproperties("hbase.table.name" = "StuChooseCourse(对应HBase表)");
OK
Time taken: 1.865 seconds
hive (stuchoosecourse)> show tables;
OK
tab_name
hbase_stu_course
Time taken: 0.108 seconds
hive (stuchoosecourse)> describe hbase_stu_course;
OK
col_name data_type comment
stu_num string from deserializer
stu_basicinfo map<string,string> from deserializer
stu_courseinfo map<string,float> from deserializer
Time taken: 0.219 seconds
hive (stuchoosecourse)> select * from hbase_stu_course;
OK
stu_num stu_basicinfo stu_courseinfo
1202000317(对应行健) {"Age":"25","Name":"Kelvin","Sex":"Male"} (对应列簇StuBasicInfo) {"Computer0001":95.0,"Computer0002":93.0,"Math0001":90.0,"Math0002":92.0}(对应列簇ChooseCourseInfo)
Time taken: 0.84 seconds
Note:
当我们用HBase 存储实时数据的时候, 如果要做一些数据分析方面的操作, 就比较困难了, 要写MapReduce Job. Hive 主要是用来做数据分析的数据仓库,支持标准SQL 查询, 做数据分析很是方便,于是便很自然地想到用Hive来载入HBase的数据做分析. 故先打通Hive对HBase指定表的全表访问(eg:映射表hbase_stu_course), 而此时这个映射表hbase_stu_course实际上是一个虚拟表, 实际的数据还在HBase中。 故需要在Hive中另建一个结构一样的空表, 再把数据导出来。Namely, 再建立一个新的空表, 把查询出来的数据全部导入到新表当中, 以后的所有数据分析操作在新表中完成