前言:最近一段时间比较忙,也是比较懒了吧,好长时间没写博客了,新的一年到来,给自己一个小目标,博客坚持写下去,分享一下这历程!废话不多说,开始正题咯(希望大家喜欢!)
首先这算是一个scala程序的入门程序,但是并不是针对零基础的,需要了解一定的scala基础,如果有Java基础的同学看起来估计会好一点。如果有必要的话,后面补一篇比较 详细的适合新手的零基础scala“教程”吧!
首先说明一下,Scala Actor是scala 2.10.x版本及以前版本的Actor。Scala在2.11.x版本中将Akka加入其中,作为其默认的Actor,老版本的Actor已经废弃,虽然已经废弃了,但是还是可以作为扩展去了解一下的。
这里普及一下java并发编程与Scala Actor编程的区别:
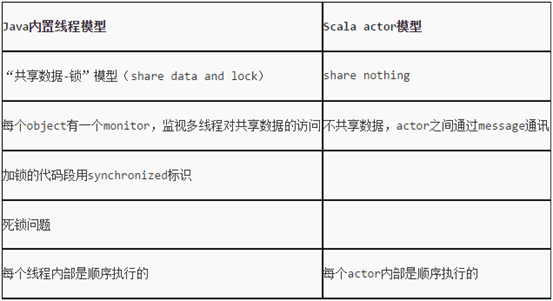
对于Java,我们都知道它的多线程实现需要对共享资源(变量、对象等)使用synchronized 关键字进行代码块同步、对象锁互斥等等。而且,常常一大块的try…catch语句块中加上wait方法、notify方法、notifyAll方法是让人很头疼的。原因就在于Java中多数使用的是可变状态的对象资源,对这些资源进行共享来实现多线程编程的话,控制好资源竞争与防止对象状态被意外修改是非常重要的,而对象状态的不变性也是较难以保证的。
与Java的基于共享数据和锁的线程模型不同,scala的actor包则提供了另外一种不共享任何数据、依赖消息传递的模型,从而进行并发编程。
Actor的执行顺序
1、首先调用start()方法启动Actor
2、调用start()方法后其act()方法会被执行
3、向Actor发送消息
4、act方法执行完成之后,程序会调用exit方法
发送消息的方式
|
! |
发送异步消息,没有返回值。 |
|
!? |
发送同步消息,等待返回值。 |
|
!! |
发送异步消息,返回值是 Future[Any]。 |
注意:Future 表示一个异步操作的结果状态,可能还没有实际完成的异步任务的结果
Any 是所有类的超类,Future[Any]的泛型是异步操作结果的类型。
正式进入正题,对!前面还是做了一些基本的介绍,方便大家的回忆!
我们的目标:用actor并发编程写一个单机版的WorldCount,将多个文件作为输入,计算完成后将多个任务汇总,得到最终的结果
大致思想步骤:
1、通过loop +react 方式去不断的接受消息(注意这里的消息就是我们当前的文件名称)
2、利用case class样例类去匹配对应的操作
3、其中scala中提供了文件读取的接口Source,通过 调用其fromFile方法去获取文件内容
4、将每个文件的单词数量进行局部汇总,存放在一个ListBuffer中
5、最后将ListBuffer中的结果进行全局汇总。
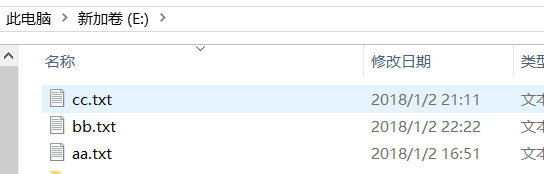
准备工作:在E盘放入三个文件,aa.txt、bb.txt、cc.txt随便写一些单词进去。



接下来就是写一个我们的WordCountScala.scala类了:
1 package com.yida.scala 2 3 import scala.actors.{Actor, Future} 4 import scala.collection.mutable 5 import scala.collection.mutable.ListBuffer 6 import scala.io.Source 7 8 //todo:利用scala中的并发编程,多个文件作为输入,首先进行局部汇总,最终再进行全部汇总 9 10 //todo:定义样例类 11 case class SubmitTask(fileName:String)//提交任务的样例类 12 case class ResultTask(result:Map[String,Int])//todo:封装每个单词出现的次数 13 14 class WordCountScala extends Actor{ 15 override def act(): Unit = { 16 loop{ 17 react{ 18 case SubmitTask(fileName) => { 19 //todo:2、读取文件数据,利用scala中的scala.io.Source的fromFile方法读取数据 20 val lines: String = Source.fromFile(fileName).mkString 21 //todo:3、按照换行符进行读取,window下的换行符是 Linux是 22 val linesArray: Array[String] = lines.split(" ") 23 println(linesArray.toBuffer) 24 //todo:4、按照空格进行切分并且压平 25 val words: Array[String] = linesArray.flatMap(_.split(" ")) 26 println(words.toBuffer) 27 //todo:5、每个单词记为1 28 //words.map((_,1)) 29 val wordAndOne: Array[(String, Int)] = words.map(x=>(x,1)) 30 println(wordAndOne.toBuffer) 31 //todo:6、按照单词进行分组 32 val wordGroup: Map[String, Array[(String, Int)]] = wordAndOne.groupBy(_._1) 33 println(wordGroup.toBuffer) 34 //todo:7、通过mapValues方法拿到map所有key对应的value 35 val result: Map[String, Int] = wordGroup.mapValues(_.length) 36 println(result.toBuffer) 37 //todo:8、把结果返回给发送方 38 sender ! ResultTask(result) 39 } 40 } 41 } 42 } 43 } 44 45 object WordCountScala{ 46 def main(args: Array[String]): Unit = { 47 //todo:定义一个set集合 ,用于存放每次异步的结果 48 val hashSet = new mutable.HashSet[Future[Any]]() 49 //todo:定义一个list集合,用于存放真正的结果数据 50 val taskList = new ListBuffer[ResultTask] 51 /* 52 val task = new WordCountScala 53 task.start() 54 task !! SubmitTask("E:\aa.txt")*/ 55 56 //todo:1、准备数据文件 57 val files = Array("E:\aa.txt","E:\bb.txt","E:\cc.txt") 58 //todo:2、遍历数据文件,发送消息 59 for(fileName <- files){ 60 //todo:3、针对每一个文件,创建一个actor实例 61 val task = new WordCountScala 62 task.start() 63 //向actor提交任务 64 val result: Future[Any] = task !! SubmitTask(fileName) 65 //todo:4、存放异步返回结果到set集合中 66 hashSet += result 67 } 68 //todo:5、处理hashSet中的数据 69 while(hashSet.size>0){ 70 //todo:6、判断对应真正完成任务的结果 71 val completedTask: mutable.HashSet[Future[Any]] = hashSet.filter(_.isSet) 72 for(c <- completedTask){ 73 //todo:7、获取future中的数据 74 val data: Any = c.apply() 75 val task: ResultTask = data.asInstanceOf[ResultTask] 76 //todo:8、将真正的结果保存到list集合中 77 taskList += task 78 //todo:9、将处理完成的数据删除 79 hashSet -= c 80 } 81 } 82 //todo:10、对taskList结果进行操作 83 println(taskList.map(_.result).flatten.groupBy(_._1).mapValues(x=>x.foldLeft(0)(_+_._2))) 84 85 } 86 }
欣赏一下跑完后的结果:代码 注释还有 不懂的地方 欢迎提出来,我看到了会解答的哈!
