概述
zhparser 是一个支持中文全文检索的 extension,基于Simple Chinese Word Segmentation(SCWS) 上开发的
SCWS安装
下载文件:http://www.xunsearch.com/scws/down/scws-1.2.2.tar.bz2
解压安装:
tar xvf scws-1.2.2.tar.bz2
cd scws-1.2.2
./configure
make install
zhparser安装
准备:
设置环境变量
PG_HOME=/opt/PostgreSQL/9.6
PG_BIN=/opt/PostgreSQL/9.6/bin
PATH=$PATH:$PG_BIN
下载zhparser:https://github.com/amutu/zhparser/archive/master.zip
解压并进入解压目录,执行命令:
SCWS_HOME=/usr/local make && make install
检查安装结果:
进入目录/opt/PostgreSQL/9.6/share/postgresql/extension,查看文件列表

中文分词测试
1、创建extension:create extension zhparser;
2、CREATE TEXT SEARCH CONFIGURATION testzhcfg (PARSER = zhparser);
3、ALTER TEXT SEARCH CONFIGURATION testzhcfg ADD MAPPING FOR n,v,a,i,e,l WITH simple;
4、select to_tsvector('testzhcfg','南京市长江大桥');
结果:

创建GIN索引
create index idx_gin_tbl_store_name on poi using gin(to_tsvector('testzhcfg',name_zh));
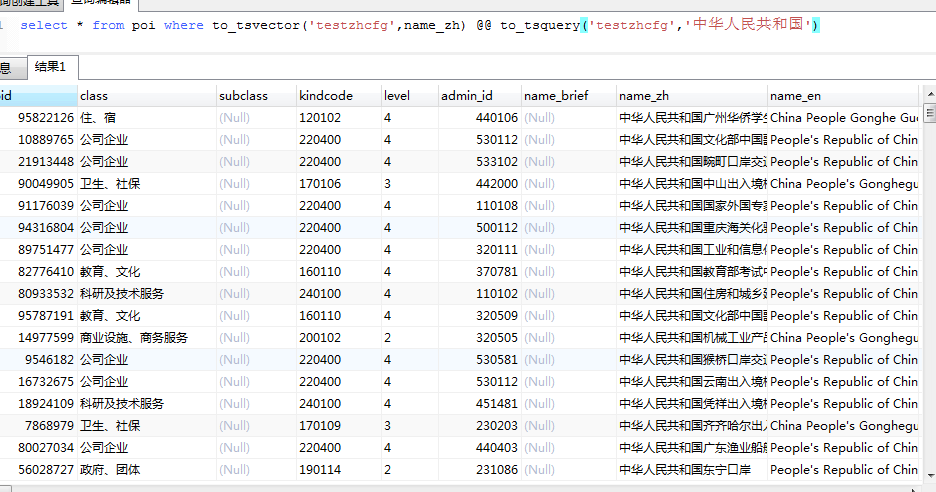
执行查询:
select * from poi where to_tsvector('testzhcfg',name_zh) @@ to_tsquery('testzhcfg','中华人民共和国')
查询结果:
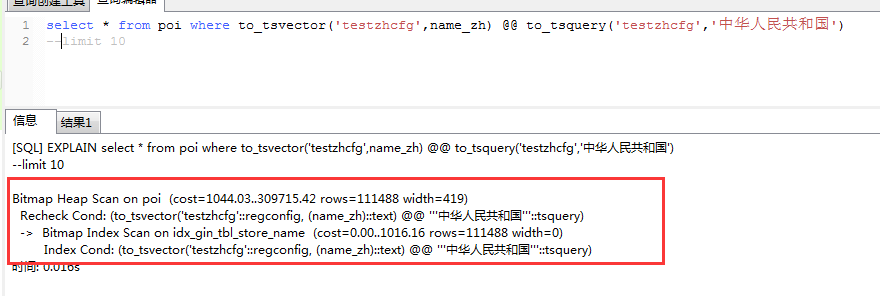
注意点:不要随意加limit,不加limit的执行计划为:
加上limit的执行计划为:
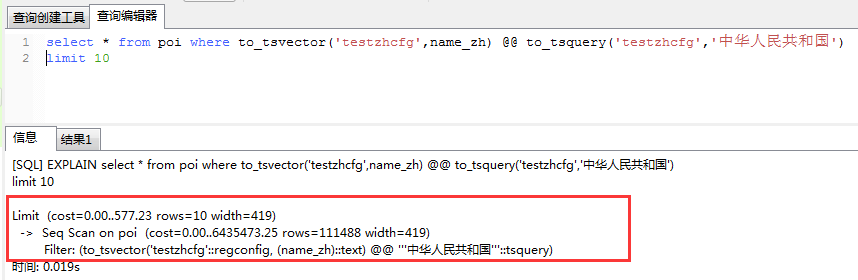
也就是没有走索引
扩展词库
除了zhparser自带的词典,用户可以增加自定义词典,自定义词典的优先级高于自带的词典。自定义词典的文件必须放在share/postgresql/tsearch_data目录中,zhparser根据文件扩展名确定词典的格式类型,.txt扩展名表示词典是文本格式,.xdb扩展名表示这个词典是xdb格式,多个文件使用逗号分隔,词典的分词优先级由低到高,如:
zhparser.extra_dicts = 'dict_extra.txt,mydict.xdb'
TXT 词库的写法 (TXT词库目前已兼容 cli/scws_gen_dict 所用的文本词库) **
-
每行一条记录,以 # 或 分号开头的相当于注释,忽略跳过
-
每行由4个字段组成,依次为“词语"(由中文字或3个以下的字母合成), "TF", "IDF", "词性",字段使用空格或制表符分开,数量不限,可自行对齐以美化
-
除“词语”外,其它字段可忽略不写。若忽略,TF和IDF默认值为 1.0 而 词性为 "@"
-
由于 TXT 库动态加载(内部监测文件修改时间自动转换成 xdb 存于系统临时目录),故建议TXT词库不要过大
-
删除词做法,请将词性设为“!“,则表示该词设为无效,即使在其它核心库中存在该词也视为无效
更改之后,需要重新启动数据库: bin/pg_ctl -D /data/lilei/postgresql/data/ restart
附加创建xdb导入、导出工具:http://www.xunsearch.com/scws/download.php、http://www.xunsearch.com/scws/down/phptool_for_scws_xdb.zip