Jiaming Liu——【2019】Detecting Text in the Wild with Deep Character Embedding Network
论文
Jiaming Liu——【2019】Detecting Text in the Wild with Deep Character Embedding Network
作者

亮点
- 通过将文字的字符合并问题转成字符embedding问题,利用一个网络来学习字符间的连接关系
方法概述
针对任意文字检测(水平、倾斜、曲文),采用从字符到文本行的自底向上的pipeline:
- 先用一个网络CENet学习两个任务,包括单个字符的检测,以及一个字符对的embedding向量(表示两个字符是否可以构成一个pair)。
- 然后再用一个字符分类阈值提取检测到的字符,和一个合并阈值提取group的字符对。
- 最后利用WordSup中的文本线形成算法(图模型+一阶线性模型)得到文本行。
实际test时步骤:
- 运行CENet,得到字符候选集合+字符对候选集合
- 利用分数阈值s过滤非字符噪声
- 对每个字符运用r-KNN,查找local的character pairs(参数d、k)
- 使用piecewise linear model(分段线性拟合)来得到character group的最外接任意多边形
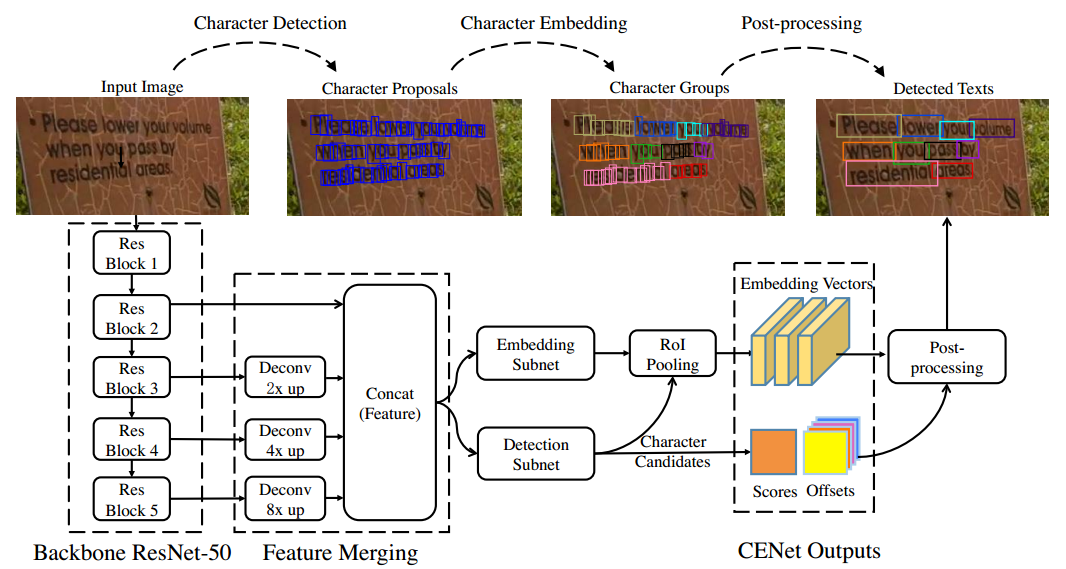
Fig. 2. Overall process of the model. Blue bounding boxes in character proposals" are character candidates with high confidence scores. Character Clusters" is the character clusters in embedding space, where candidates in the same cluster use the same color. The final detected words represented in quadrangles are shown in Detected text". Better view in color.
方法细节
- 网络损失函数 = 字符分类损失 + 字符回归损失 + 字符embedding损失
- 字符分类损失:hinge-loss损失
- 字符回归损失:Iou损失(对框大小比L2损失更不敏感)
- 字符embedding损失:contrastive loss(对比损失,专门用于pair对相似性的损失)
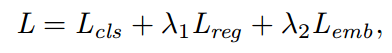
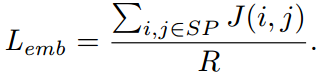
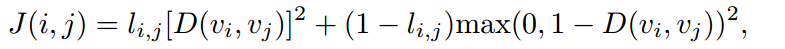
D(vi, vj)表示欧氏距离。l_ij表示vi和vj是否match。如果相似,D越大,J越大。如果不相似,D越大,J越小。
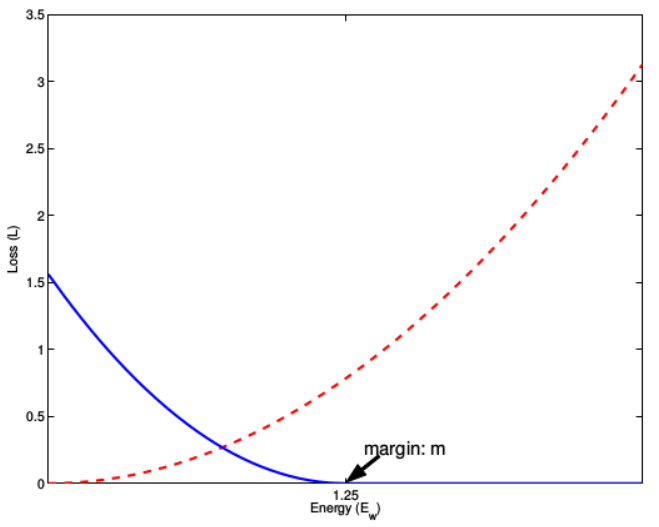
上图表示的就是contrastive损失函数值与样本特征的欧式距离之间的关系,其中红色虚线表示的是相似样本的损失值,蓝色实线表示的不相似样本的损失值。
-
字符弱监督学习(利用单词级/文本线级的annotation学习字符级的prediction)
-
Step1:沿长边均匀切分,得到coarse-char,如Fig3中a的蓝色框
-
Step2:查找和每个coarse-char匹配的pred-char,如Fig3中的b的橘色框
- 匹配原则:分数高且IOU大
-

- Step3:利用coarse-char和matched pred-char得到fine-char,如Fig3中的c的绿色框
- 原则
- 水平框:fine_h = coarse_h,fine_w = pred_w
- 竖直框:fine_w = coarse_w,fine_h = pred_h
- 原则

Fig. 3. Learning character detector from word-level annotation. (a) are some coarsechar boxes (blue) with the polygon annotation (red), (b) are some pred-char boxes, and (c) are the fine-char boxes whose height is the same as (a).
-
r-KNN算法(查找pair对条件)
-
前k个最近的框
-
box的大小相似
-
距离<d
-
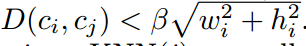
-
文章实验中实际用的小技巧
- mix batch trick:一半用VGG-50k的合成字符标注数据,另一个半用ICDAR15、MSAR这些文本行标注数据训练(还是用了额外的字符标注数据...)
- reweighting:考略正pair对的冗余性,把负pari加权
- the positive pairs are redundant. The minimum requisite for error-less positive pairs is that at least one chain connects all characters in a text unit. Positive pairs with large embedding distances do not contribute any text level error as long as the minimum requisite is satisfied. However, a negative pair with small embedding distance will certainly mis-connect two text units and generate text level error. Meanwhile, we found there are about 3/4 of local character pairs are positive. According to the above analysis, we assume the negative pairs should be weighted more than the positive pairs in training.
- short word removal:在ICDAR15上把小于2个字符的去掉

问题和疑问
- 文章没有说速度,KNN去算embedding,框多的情况下,速度肯定慢
- 网络部分文章没说清楚两个Embedding Subnet和Detection Subnet的具体结构
- 在构成pair对的地方并没有说清楚在哪里用了similar box size这一点
Another useful heuristic rule is that a character is more likely to be connected with characters with similar box size. Therefore, only characters within radius were kept.
实验结果
-
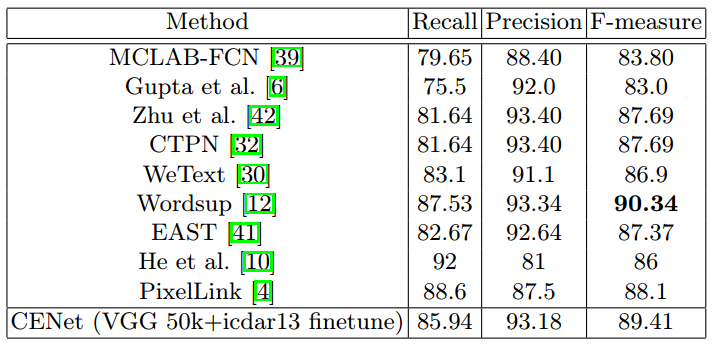
ICDAR13
-
ICDAR15

-
MSRA-TD500

- Total-Text

收获点与问题
- 用embedding来学习字符间的关系还是比较新的一个出发点。整个方法还是传统方法字底向上的思路,多步骤而且速度应该比较慢。整体感觉偏engineering,实验上标明也是一些比较工程上的trick对实验结果提升较明显