1.并发数
在理解并发数之前,先提出3个常见的概念,分别是系统用户数、在线用户数和并发用户数。小白发现很多人都会把这3个概念混淆,其实是不一样的。以BestTest的论坛作为例子,对应的解释分别如下。
系统用户数:简单地说就是该系统的注册用户数。例如,BestTest论坛里存在6666个注册用户,他们可以是活跃的,也可以是僵尸的。
在线用户数:即登录系统的用户。例如,其中有666个用户的状态为在线,但在线用户并不一定都会对服务器产生压力,因为有的用户登录后什么都不干。
并发用户数:是对服务器产生压力的用户。例如,可能在线的666个用户中,只有20%的用户对服务器产生了压力,这20%的用户数就是并发用户数。
那为什么要关注并发用户数而不是其他用户数呢?上面已经提到过,最直接的原因就是只有并发用户数才对系统产生真正的压力。就好像一个人提1斤的东西不觉得重,但是提150斤的东西,那可就难以提动了。
在实际应用中,并发数可以通过分析服务器日志得以确定,这种方式更加准确。一般常用的日志分析工具有AWStats、Webalizer、Analog、Deep Log Analyzer等。也可以通过业界的一些计算模型得到,后续章节中会学习。
这里再延伸一下并发的概念。一般有两种理解方式:一种为所有用户在同一时刻做同一种操作,主要是为了验证程序或数据库对并发的处理能力;另一种为多个用户对被测系统发起了多个请求,这些请求可以是同一种操作,也可以是不同的操作,类似于混合场景的概念。
2.响应时间
小白通过查找资料发现,大部分资料都是说“响应时间=网络响应时间+应用程序响应时间”诸如此类的解释。小白一时间有点摸不着头脑。于是,静下心来开始认真分析、研究。
我们可以换个角度去看待这个概念。首先从大的方向上可以把一个系统分为前端与后端,而响应时间也可以按照这个划分来理解。让我们先看图1-1再来理解。
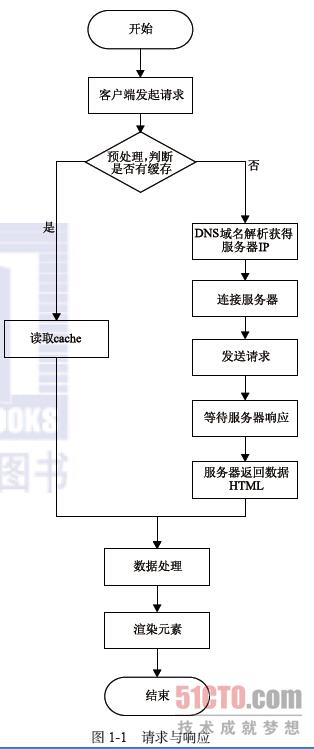
通过图1-1可以清楚地看出在没有缓存的情况下,一个请求发出去后,需要经过网络传输、DNS解析等步骤才能到达服务器,服务器处理完后,经由网络传输返回给客户端,而客户端接收到以后,要进行解析渲染展示给用户。这里需要注意,网络时间包括请求传输的时间和响应传输的时间,而服务器也可能是多层处理。
这下逻辑就非常清楚了,可以总结为:响应时间=网络传输(请求)时间+服务器处理(一层或多层)时间+网络传输(响应)时间+页面前端解析渲染时间。小白终于明白响应时间背后的来龙去脉了。
在实际应用过程中,需要明白响应时间的长短取决于用户的实际需求,而不是盲目设定该指标。毕竟在BestTest论坛查找一个帖子和在数据统计系统中查找一个月的数据汇总与明细统计是完全不同的,它们的业务有各自独有的特点,不能简单地一概而论。
前端页面的解析展示时间一般在做非前端性能测试中不太会关注,因为每个浏览器解析页面的方式不一样,时间也会不一样。
3. 每秒通过事务数
TPS是指每秒通过事务数,是直接反映系统性能的指标,该值大时,系统性能会比较好,当然每个系统都有它的上限,不可能无限大。将它与平均事务响应时间进行对比,可以分析事务数量对响应时间的影响。
例如,当压力加大时,TPS曲线如果变化缓慢或者有平坦的趋势,很有可能是服务器开始出现瓶颈了。如果环境没有发生大的变化,对于同一系统会存在一个最大处理事务能力,它并不随着并发用户的多少而改变。就好像传说中的北京五道口地铁检票机一样,只有两台进站检票的机器,一次一台机器只能通过一个人,不论是来10个人,还是100个人。
4.每秒点击数
每秒点击数代表用户每秒向Web服务器提交的HTTP请求数。但这里需要注意的是提交一个登录请求,对于用户来说感觉是一个请求,但对于后端服务器来说也许是多个请求,所以点击一次不代表就是一个请求。例如,点击一个链接,该操作返回的页面上有6张图片,因为下载每张图片都需要一个HTTP请求,所以这个页面下载完成之后的点击数应该是7。
每秒点击数从侧面可以反映客户端的状况,每秒点击数不正常,一般可能是网络问题或者脚本问题导致,需要进一步具体分析。
5.吞吐量
经常在网上看到“吞吐量”与“吞吐率”的概念,也有不少人把两者混淆。吞吐量是指单位时间内系统处理的请求数量,能直接反映服务器承受的压力,是需要重点关注的指标。而吞吐率一般指用户在给定的一秒内从服务器获得的数据量,简而言之就是服务器返回的数据量。
例如,一个食品厂的生产效率很高,一天能生产很多食品,但是工厂只有两辆三轮车在运输,不难想象会出现什么样的可怕场景。这个时候工厂运输食品的能力就成为了瓶颈,也就是它的吞吐量/吞吐率出现了瓶颈。
6.思考时间
思考时间可以从两个宏观的角度来理解。
1)思考时间就是用户进行操作时,每个请求或者操作之间的间隔时间,是为了更加真实地模拟用户的操作场景。因为在实际使用中不太可能会出现不断地发送请求,一般都是一个请求后,等待一段时间,然后发送下一个请求,恶意攻击除外。
2)小白发现在BestTest论坛连续发帖时会提示“两次发帖时间间隔不能小于15秒钟”,这时如果要满足业务的特定需求就需要加上思考时间15s了。这下小白对思考时间有了进一步的认识,很是高兴。
另外,小白经常在网上看到关于0思考时间的讨论,自己也有点疑惑,于是请教了经理。经理告诉他,如果想了解系统的最大承受能力或者极端情况下系统的性能表现,则可以设置为0思考时间。但如果是预估系统的性能,就应该最大可能地模拟真实思考时间。一般都会加上思考时间,只是在分析时要去掉思考时间。
7.资源利用率
小白通过查找资料发现,关于资源利用率的资料太多也太杂,根本无法梳理,而且会越看越乱,无奈之下向经理求助,经理告诉他虽然指标很多,但很多时候每个指标间都是有关联的,而且重点的就是那么几个,只要把这几个理解透彻就行了。小白按照经理的指导开始学习、理解重点的几个指标。
CPU:它就像是人的大脑,主要是进行判断和处理,能反映出系统的繁忙程度,一般分为系统CPU与用户CPU,其中系统CPU是处理系统本身所占用的资源,用户CPU则是处理程序所占用的资源,对象不同。
Load Average:指一段时间内CPU正在处理和等待CPU处理的任务,也就是CPU使用队列的长度的统计信息。这里的Load Average值就好像地铁里等待进站上车的乘客,越多则Load Average值也越大。
Memory:它就像是人大脑的记忆区域,将各种信息收集起来存放。数据从内存中读取要比从磁盘上读取速度快,而内存经常发生内存泄露或内存溢出的现象,是需要重点留意的。不过这里需要注意,短时间的可用内存越来越少,不代表一定有内存泄露或溢出。
队列:可以理解成地铁进站的排队现象,队列长,说明处理能力可能达到了极限或者遇到了阻塞。
IO:与磁盘的交互,重点关注交换频率和磁盘队列长度。
网络:重点关注网络的流量,看是否存在网络带宽的瓶颈。