N-gram模型是一种语言模型(Language Model,LM),语言模型是一个基于概率的判别模型,它的输入是一句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。

N-gram本身也指一个由N个单词组成的集合,考虑单词的先后顺序,且不要求单词之间互不相同。常用的有 Bi-gram (N=2N=2N=2) 和 Tri-gram (N=3N=3N=3),一般已经够用了。例如在上面这句话里,我可以分解的 Bi-gram 和 Tri-gram :
Bi-gram : {I, love}, {love, deep}, {love, deep}, {deep, learning}
Tri-gram : {I, love, deep}, {love, deep, learning}N-gram中的概率计算

联合概率的简单推导过程:A,B,C三个有顺序的句子。
由于
P(C/(A,B))=P(A,B,C)/P(A,B)
P(B/A) = P(A,B)/P(B)
所以
P(C/(A,B))=P(A,B,C)/(P(B/A) *P(B))
P(A,B,C) = P(C/(A,B))*P(B/A) *P(B)
所以我们可以很容易的得到上面的多个单词的联合概率,但是由于存在参数空间过大等问题,我们可以仅仅考虑之前的一个或者几个词的前提条件的联合概率,可以降低时间复杂度,减少计算量。

然后通过极大似然函数求解上面的概率值
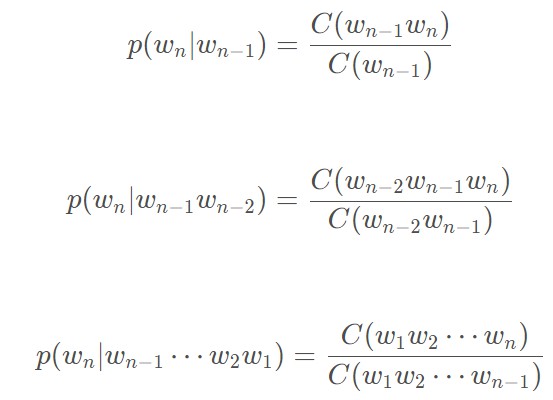
是从整个数据库中去计算上述的概率值,而不是一整句话。
1、可以用于词性标注,类似成多分类的情况:
例如:我爱中国!
判断爱的词性可以通过P(词性i/(名词我出现,爱字出现))=P(名词我出现,爱字不同的词性)/P(名词的我出现,爱字所有出现的次数)
2、可以用于垃圾短信分类:

- 步骤一:给短信的每个句子断句。
- 步骤二:用N-gram判断每个句子是否垃圾短信中的敏感句子。
- 步骤三:若敏感句子个数超过一定阈值,认为整个邮件是垃圾短信。
3、用于分词作用
在NLP中,分词的效果很大程度上影响着模型的性能,因此分词甚至可以说是最重要的工程。用N-gram可以实现一个简单的分词器(Tokenizer)。同样地,将分词理解为多分类问题:X表示有待分词的句子,Yi表示该句子的分词方案:
X="我爱深度学习"
Y1={"我","爱深","度学习"}
Y2={"我爱","深","度学","习"}
Y3={"我","爱","深度学习"}
p(Y1)=p(我)p(爱深∣我)p(度学习∣爱深)
p(Y2)=p(我爱)p(深∣我爱)p(度学∣深)p(习∣度学)
p(Y3)=p(我)p(爱∣我)p(深度学