一 机器学习概览
- 机器学习的广义概念是:机器学习是让计算机具有学习的能力,无需进行明确编程.
- 机器学习的工程性概念是:计算机程序利用经验E学习任务T,性能是P,如果针对任务T的性能P随着经验E不断增长,则为机器学习.
- 使用机器学习挖掘大量数据,发现不显著的规律,称为数据挖掘.
- 根据训练时监督的量和类型分为:
- 监督学习:训练数据包含了标签,如分类,回归.
- 非监督学习:训练数据没有标签.如聚类,降维,可视化.
- 半监督学习:大量不带标签数据加上小部分带标签数据.如深度信念网络.
- 强化学习:系统执行动作,获得奖励,然后学习策略.如AlphaGo.
- 根据是否从导入的数据流进行持续学习分为:
- 批量学习(离线学习):不能进行持续学习,如果想学习新数据就要重新训练并更换系统.
- 在线学习:可以使用小批量持续地训练.缺点是坏数据会导致性能下滑.
- 根据如何进行归纳推广分为:
- 基于实例学习:先用记忆学习案例,然后用相似度测量推广到新的例子.
- 基于模型学习:建立这些样本的模型,然后使用模型进行预测.
- 机器学习的主要挑战:
- 数据量不足
- 没有代表性的训练数据
- 低质量数据
- 不相关的特征
- 过拟合
- 欠拟合
- 使用训练集训练模型参数,验证集选取超参数,测试集预估误差率.为了避免浪费训练数据在验证集上,一般使用交叉验证.
二 一个完整的机器学习项目
- 本章的目标是建立一个房价预测系统,这是一个回归问题.主要步骤为:项目概述-获取数据-发现并可视化数据,发现规律-为机器学习算法准备数据-选择模型,进行训练-微调模型-给出解决方案-部署,监控,维护系统.
- 均方根误差(RMSE)是回归问题的典型指标.
 .
. - 平均绝对误差(MAE)也是一种选择
 .
. - 在类似RMSE和MAE这样的范数中,范数的指数越高,就越关注大的值而忽略小的值.
- 利用pd.read_csv()读取数据后,可以用head(),info(),value_counts()和describe()方法大致了解数据.
- 在对测试集采样时,需要保证数据集中的每个分层都要用足够的实例位于测试集中.可以将最重要的一类特征进行离散处理,然后使用sklearn的StratifiedShuffleSplit类来分层采样.
- 使用corr(),和pd.tools.plotting.scatter_matrix()方法可以探索特征之间的相关性.
- 特征之间相互组合产生的新特征也很重要.
- 大多数机器学习算法不能处理缺失的特征.可以:
- dropna()去除对应行
- drop()去掉对应属性
- fillna()赋值
- 使用sklearn的Imputer类来处理
- 对于文本和类别属性,可以用sklearn的OneHotEncoder来处理.
- 特征缩放是最重要的数据转换之一.可以用线性函数归一化(Normalization,减去最小值,除以最大值与最小值的差值,sklearn中的MinMaxScaler)和标准化(Standardization,减去平均值,除以方差,sklearn中的StandardScaler)来实现.
- sklearn提供了Pipeline类来实现流水线.
- sklearn的GridSearchCV可以用于网格搜索最佳的超参数组合.适用于搜索空间不大的情况.
- sklearn的RandomizedSearchCV可以用于随机搜索最佳的超参数组合.适用于搜索空间很大的情况.
三 分类
- 二分类问题的准度一般采用准确率(Precision),召回率(Recall)和F1值(2*P*R/(P+R)).ROC曲线也是一个常用的工具,它是真正例率对假正例率的曲线.ROC曲线下的面积称为AUC,AUC越接近1分类器的效果就越好.
- SVM或线性分类器是严格的二分类器,可以通过OvA(一对所有)或OvO(一对一)策略让它们执行多类分类.Sklearn会自动执行OvA或OvO(对SVM).
- 多标签分类是指分类器给一个样例输出多个类别.
- 多输出-多类分类是指分类器的输出是多标签的,并且每个标签有多个值.例如图像去噪.
四 训练模型
- 介绍了批量梯度下降,随机梯度下降和小批量梯度下降,不再赘述.
- 如果添加特征的高阶组合作为新特征,线性回归也能拟合非线性关系.
- 一个模型的泛化误差是由偏差(高偏差意味着欠拟合),方差(高方差意味着过拟合),不可约误差组成的.
- 训练中的损失函数应该易于求导,测试过程中的评价函数应该接近最后的客观表现.
- 在正则化前对数据进行放缩是非常重要的.
- 岭(Ridge)回归是在线性回归的损失函数直接加上一个L2正则项
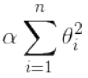
- Lasso回归是在线性回归的损失函数直接加上一个L1正则项
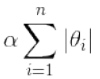 .它倾向于完全消除最不重要的特征的权重.
.它倾向于完全消除最不重要的特征的权重. - 弹性网络(ElasticNet)介于Ridge回归和Lasso回归之间,它的正则项是两者正则项的简单混合.
- 早停(early stop)也是一种正则化方法.一旦验证集误差停止下降,就提早停止训练.
- Logistic回归是一种分类算法.它计算输入特征的加权和,然后将结果输入logistic函数
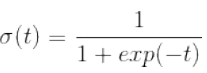 后输出.并根据输出值与阈值的比较决定分类结果.它的损失函数是对数损失
后输出.并根据输出值与阈值的比较决定分类结果.它的损失函数是对数损失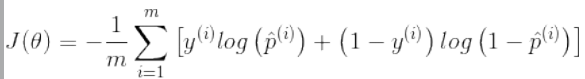 ,可以使用梯度下降求解.
,可以使用梯度下降求解. -
Softmax回归用参数向量计算每个类的得分
 ,然后将得分传入softmax函数作为概率
,然后将得分传入softmax函数作为概率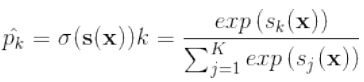 传出.使用的损失函数是交叉熵
传出.使用的损失函数是交叉熵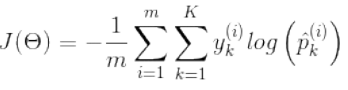 ,用于衡量待测类别与目标类别的匹配程度.
,用于衡量待测类别与目标类别的匹配程度.
五 支持向量机
-
SVM能做线性或非线性的分类,回归,适合复杂但中小规模数据集的分类问题.SVM的最大间隔分类是由线性平面边缘的支持向量决定的.SVM对特征缩放很敏感.
- SVM的核技巧可以使得不添加高次数的多项式特征或相似特征就产生同样的效果.常用的核函数是linear,poly和RBF,以及一些针对特定数据结构的核函数.