词法分析程序(Lexical Analyzer)要求:
- 从左至右扫描构成源程序的字符流
- 识别出有词法意义的单词(Lexemes)
- 返回单词记录(单词类别,单词本身)
- 滤掉空格
- 跳过注释
- 发现词法错误
程序结构:
输入:字符流(什么输入方式,什么数据结构保存)
处理:
–遍历(什么遍历方式)
–词法规则
输出:单词流(什么输出形式)
–二元组
单词类别:
1.标识符(10)
2.无符号数(11)
3.保留字(一词一码)
4.运算符(一词一码)
5.界符(一词一码)
|
单词符号 |
种别码 |
单词符号 |
种别码 |
|
begin |
1 |
: |
17 |
|
if |
2 |
:= |
18 |
|
then |
3 |
< |
20 |
|
while |
4 |
<= |
21 |
|
do |
5 |
<> |
22 |
|
end |
6 |
> |
23 |
|
l(l|d)* |
10 |
>= |
24 |
|
dd* |
11 |
= |
25 |
|
+ |
13 |
; |
26 |
|
- |
14 |
( |
27 |
|
* |
15 |
) |
28 |
|
/ |
16 |
# |
0 |
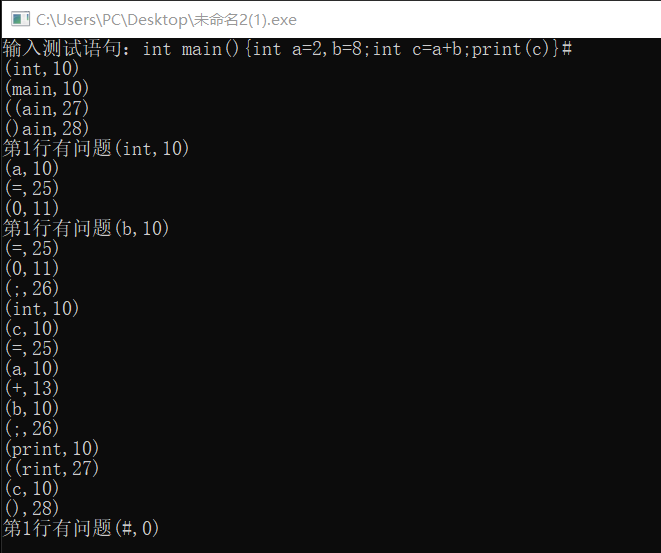
1 #include<stdio.h> 2 #include<string.h> 3 #include<stdlib.h> 4 char savearray[100],outarray[100]; 5 char ch; 6 int row,arrays,count,m,i,p;//count为计数器 p为指针 7 char *wordsymbol[6] = {"if", "begin", "then", "while", "do", "end"}; 8 void getarrays(){ 9 for(i = 0; i < 8; i++){ 10 outarray[i] == NULL; 11 } 12 ch = savearray[p++]; 13 while(ch == ' '){ 14 ch = savearray[p]; 15 p++; 16 } 17 18 if((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <='Z')){ 19 m = 0; 20 while((ch <= '9' && ch>= '0') || (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')){ 21 outarray[m++] = ch; 22 ch = savearray[p++]; 23 } 24 outarray[m++] = '�'; 25 p--; 26 arrays = 10; 27 for(i = 0; i < 6; i++){ 28 if(strcmp(wordsymbol[i],outarray) == 0){ 29 arrays =1 + i; 30 break; 31 } 32 33 } 34 }else if(ch <= '9' && ch>= '0'){ 35 count = 0; 36 while(ch >= '0' && ch <='9'){ 37 count *= 10 + (ch - '0'); 38 ch = savearray[p++]; 39 } 40 p--; 41 arrays = 11; 42 } else switch(ch){ 43 case '+': 44 outarray[0] = ch; 45 arrays = 13; 46 return; 47 case '-': 48 outarray[0] = ch; 49 arrays = 14; 50 return; 51 case '*': 52 outarray[0] = ch; 53 arrays = 15; 54 break; 55 case '/': 56 outarray[0] = ch; 57 arrays = 16; 58 break; 59 case ':': 60 i = 0; 61 outarray[i++] = ch; 62 ch = savearray[p++]; 63 if(ch == '='){ 64 outarray[i++] = ch; 65 arrays = 18; 66 }else{ 67 arrays = 17; 68 p--; 69 } 70 return; 71 72 case '<': 73 i = 0; 74 outarray[i++] = ch; 75 ch = savearray[p++]; 76 if(ch == '='){ 77 outarray[i++] = ch; 78 arrays = 21; 79 80 }else if(ch == '='){ 81 outarray[i++] = ch; 82 arrays = 22; 83 }else{ 84 arrays = 20; 85 p--; 86 } 87 return; 88 case '>': 89 i = 0; 90 outarray[i++] = ch; 91 ch = savearray[p++]; 92 if(ch == '='){ 93 outarray[i++] = ch; 94 arrays = 24; 95 }else{ 96 arrays = 23; 97 p--; 98 } 99 return; 100 case '=': 101 outarray[0] = ch; 102 arrays = 25; 103 break; 104 case ';': 105 outarray[0] = ch; 106 arrays = 26; 107 break; 108 case '(': 109 outarray[0] = ch; 110 arrays = 27; 111 break; 112 case ')': 113 outarray[0] = ch; 114 arrays = 28; 115 break; 116 case '#': 117 outarray[0] = ch; 118 arrays = 0; 119 break; 120 case ' ': 121 arrays = 100; 122 break; 123 default: 124 arrays = -1; 125 } 126 } 127 int main(){ 128 int p = 0, 129 row = 1; 130 printf("输入测试语句:"); 131 do{ 132 ch = getchar(); 133 savearray[p++] = ch; 134 }while(ch != '#'); 135 136 p = 0; 137 do{ 138 getarrays(); 139 switch(arrays){ 140 case -1: 141 printf("第%d行有问题",row); 142 break; 143 case 100: 144 row += 1; 145 break; 146 case 11: 147 printf("(%d,%d) ", count,arrays); 148 break; 149 default: 150 printf("(%s,%d) ",outarray,arrays); 151 } 152 }while(arrays != 0); 153 } 154 155 156