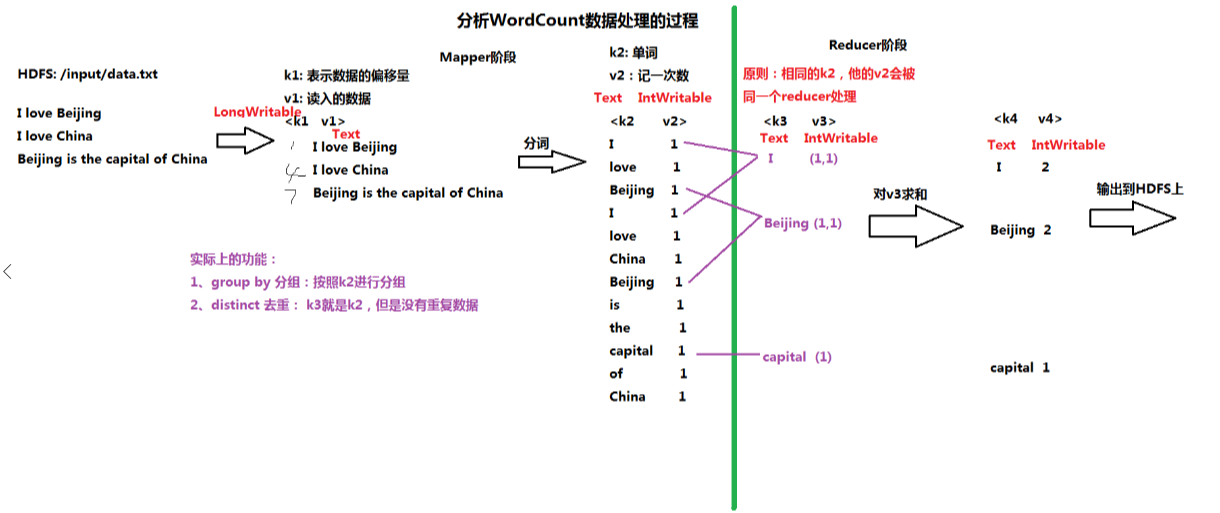
一.分析Mapreduce程序开发的流程
1.图示过程
输入:HDFS文件 /input/data.txt
Mapper阶段:
K1:数据偏移量(以单词记)V1:行数据
K2:单词 V2:记一次数
Reducer阶段 :
K3:单词(=K2) V3:V2计数的集合
K4:单词 V4:V3集合中元素累加和
输出:HDFS
2.开发WordCount程序需要的jar
/root/training/hadoop-2.7.3/share/hadoop/common
/root/training/hadoop-2.7.3/share/hadoop/common/lib
/root/training/hadoop-2.7.3/share/hadoop/mapreduce
/root/training/hadoop-2.7.3/share/hadoop/mapreduce/lib
3.WordCountMapper.java
package demo.wc; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException { //Context代表Mapper的上下文 上文:HDFS 下文:Mapper //取出数据: I love beijing String data = v1.toString(); //分词 String[] words = data.split(" "); //输出K2 V2 for (String w : words) { context.write(new Text(w), new LongWritable(1)); } } }
4.WordCountReducer.java
package demo.wc; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ @Override protected void reduce(Text k3, Iterable<LongWritable> v3, Context context) throws IOException, InterruptedException { //context 代表Reduce的上下文 上文:Mapper 下文:HDFS long total = 0; for (LongWritable l : v3) { //对v3求和 total = total + l.get(); } //输出K4 V4 context.write(k3, new LongWritable(total)); } }
5.WordCountMain.java
package demo.wc; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCountMain { public static void main(String[] args) throws Exception { //创建一个job = mapper + reducer Job job = Job.getInstance(new Configuration()); //ָ指定任务的入口 job.setJarByClass(WordCountMain.class); //ָ指定任务的mapper和输出的数据类型 job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class);//指定k2 job.setMapOutputValueClass(LongWritable.class);//指定v2 //ָ指定任务的reducer和输出的数据类型 job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); //ָ指定输入的路径(map)、输出的路径(reduce) FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); //ִ执行任务 job.waitForCompletion(true); } }
打包,传到HDFS上:

运行任务:
hadoop jar wc.jar /input/data.txt /output/day0228/wc
日志信息:
18/03/01 00:14:00 INFO client.RMProxy: Connecting to ResourceManager at bigdata11/192.168.153.11:8032
18/03/01 00:14:01 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/03/01 00:14:01 INFO input.FileInputFormat: Total input paths to process : 1
18/03/01 00:14:01 INFO mapreduce.JobSubmitter: number of splits:1
18/03/01 00:14:02 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1519833888534_0001
18/03/01 00:14:02 INFO impl.YarnClientImpl: Submitted application application_1519833888534_0001
18/03/01 00:14:02 INFO mapreduce.Job: The url to track the job: http://bigdata11:8088/proxy/application_1519833888534_0001/
18/03/01 00:14:02 INFO mapreduce.Job: Running job: job_1519833888534_0001
18/03/01 00:14:16 INFO mapreduce.Job: Job job_1519833888534_0001 running in uber mode : false
18/03/01 00:14:16 INFO mapreduce.Job: map 0% reduce 0%
18/03/01 00:14:24 INFO mapreduce.Job: map 100% reduce 0%
18/03/01 00:14:31 INFO mapreduce.Job: map 100% reduce 100%
查看结果:
hdfs dfs -ls /output/day0228/wc

hdfs dfs -cat /output/day0228/wc/part-r-00000

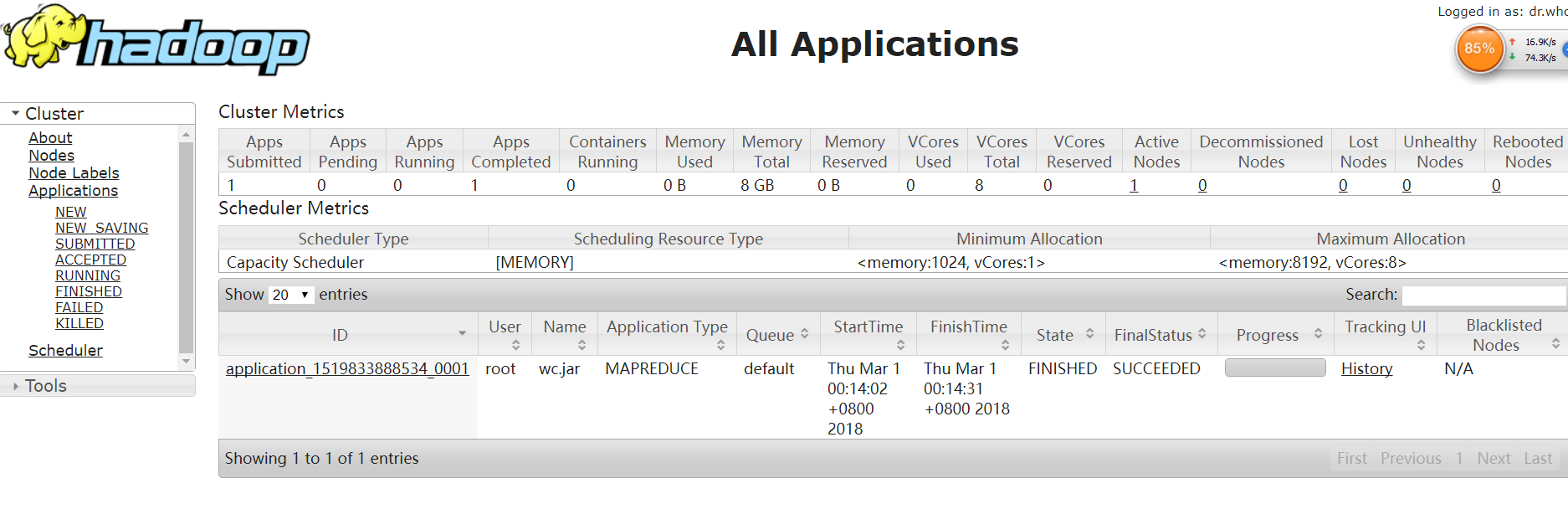
Web Console通过8088端口查看: