为什么要分表
当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。
方案1:
mysql proxy:amoeba
做mysql集群,利用amoeba。
从上层的java程序来讲,不需要知道主服务器和从服务器的来源,即主从数据库服务器对于上层来讲是透明的。可以通过amoeba来配置。
方案2:
在设计初期,对大数据量并且访问频繁的表,将其分为若干个表
比如对于某网站平台的数据库表-公司表,数据量很大,这种能预估出来的大数据量表,我们就事先分出个N个表,这个N是多少,根据实际情况而定。
某网站现在的数据量至多是5000万条,可以设计每张表容纳的数据量是500万条,也就是拆分成10张表
那么如何判断某张表的数据是否容量已满呢?可以在程序段对于要新增数据的表,在插入前先做统计表记录数量的操作,当<500万条数据,就直接插入,当已经到达阀值,可以在程序段新创建数据库表(或者已经事先创建好),再执行插入操作。
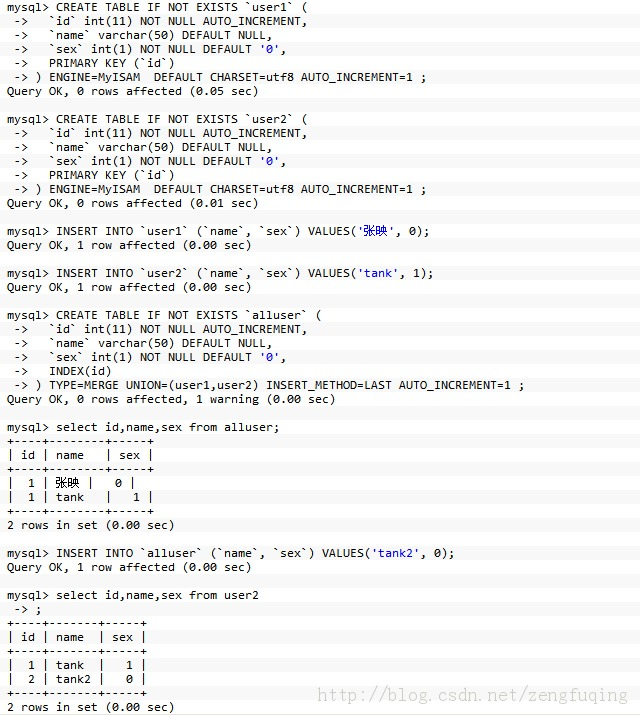
方案3:
利用merge存储引擎来实现分表
如果要把已有的大数据量表分开比较痛苦,最痛苦的事就是改代码,因为程序里面的sql语句已经写好了。用merge存储引擎来实现分表, 这种方法比较适合.
转载自: https://my.oschina.net/ydsakyclguozi/blog/199498