1、集群规划
1.1、主机配置环境
172.16.0.11 node60
172.16.0.13 node89
172.16.0.8 node145
1.2、安装后启动的进程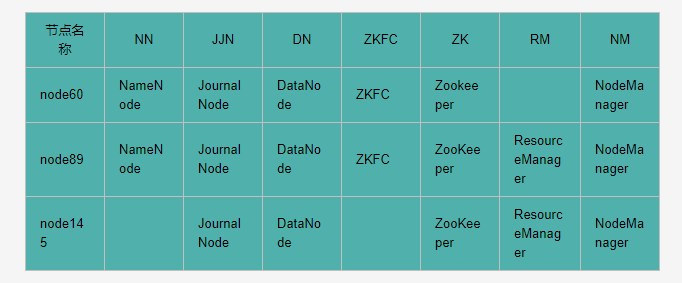
2、修改host文件
希望三个主机之间都能够使用主机名称的方式相互访问而不是IP,我们需要在hosts中配置其他主机的host。因此我们在主机的/etc/hosts下均进行如下配置:
$ vim /etc/hosts
172.16.0.11 node60
172.16.0.13 node89
172.16.0.8 node145
将配置发送到其他主机,同时在其他主机上均如上配置。
$ ping node60
PING node60 (172.16.0.11) 56(84) bytes of data.
64 bytes from node60 (172.16.0.11): icmp_seq=1 ttl=64 time=0.313 ms
64 bytes from node60 (172.16.0.11): icmp_seq=2 ttl=64 time=0.275 ms
$ ping node89
PING node89 (172.16.0.13) 56(84) bytes of data.
64 bytes from instance-2nfzkw5m-1 (172.16.0.13): icmp_seq=1 ttl=64 time=0.038 ms
64 bytes from instance-2nfzkw5m-1 (172.16.0.13): icmp_seq=2 ttl=64 time=0.054 ms
$ ping node145
64 bytes from node145 (172.16.0.8): icmp_seq=1 ttl=64 time=0.288 ms
64 bytes from node145 (172.16.0.8): icmp_seq=2 ttl=64 time=0.278 ms
3、添加用户账号
在所有的主机下均建立一个账号admin用来运行hadoop ,并将其添加至sudoers中
#添加用户通过手动输入修改密码
$ useradd admin
#更改用户 admin 的密码
$ passwd admin
设置admin用户具有root权限 修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示:
$ visudo
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
admin ALL=(ALL) ALL
修改完毕 :wq! 保存退出,现在可以用admin帐号登录,然后用命令 su - ,切换用户即可获得root权限进行操作。
4、/opt目录下创建文件夹
4.1、在root用户下创建module、software文件夹
[root@89 ~]# cd /opt/
[root@89 opt]# mkdir module
[root@89 opt]# mkdir software
4.2、修改module、software文件夹的所有者
[root@89 opt]# chown admin:admin module
[root@89 opt]# chown admin:admin software
4.3、查看module、software文件夹的所有者
[root@89 opt]# ll
drwxr-xr-x 2 admin admin 4096 Mar 8 19:25 module
drwxr-xr-x 2 admin admin 4096 Mar 8 19:25 software
5、安装配置jdk1.8
本机root用户已安装配置jdk,admin用户不用重新安装,直接使用即可。
如果未安装可采用如下命令安装:
$ sudo yum install -y java-1.8.0-openjdk*
$ vim /etc/profile(root用户安装) 或 vim /home/admin/.bash_profile(admin用户安装),内容如下:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar
export PATH=$PATH:$JAVA_HOME/bin
6、设置SSH免密钥
关于ssh免密码的设置,要求每两台主机之间设置免密码,自己的主机与自己的主机之间也要求设置免密码。 这项操作可以在admin用户下执行,执行完毕公钥在/home/admin/.ssh/id_rsa.pub。
在CentOS下会存在非root用户配置免密不能登陆的问题。
root用户按照正常操作配置SSH无密码登录服务器,一切顺利,但是到非root用户的时候,就会出现各种各样的问题,这里,就统一解决一下这些出现的问题,这里以admin用户作为例子说明。
主机node60,node89,node145都需要执行以下步骤,如果之前做过免密,后来改密码了,最好把原来的.ssh目录删掉:
$ rm -rf /home/admin/.ssh (三台都需要删掉,删掉以后在执行以下语句)
$ ssh-keygen -t rsa
$ cat /home/admin/.ssh/id_rsa.pub >> /home/admin/.ssh/authorized_keys
$ chmod 700 /home/admin/
$ chmod 700 /home/admin/.ssh
$ chmod 644 /home/admin/.ssh/authorized_keys
$ chmod 600 /home/admin/.ssh/id_rsa
如上命令在主机node60,node89,node145上执行成功,下面就来配置这三台主机的免密设置。
a、配置node60免密设置
把主机node89,node145对应的/home/admin/.ssh/id_rsa.pub内容拷贝到/home/admin/.ssh/authorized_keys(该文件在node60主机上)
b、配置node89免密设置
把主机node60,node145对应的/home/admin/.ssh/id_rsa.pub内容拷贝到/home/admin/.ssh/authorized_keys(该文件在node89主机上)
c、配置node145免密设置
把主机node60,node89对应的/home/admin/.ssh/id_rsa.pub内容拷贝到/home/admin/.ssh/authorized_keys(该文件在node145主机上)
d、验证免密是否设置成功
[admin@60 ~]$ ssh node89
Last login: Sun Mar 8 20:52:20 2020 from 172.16.0.11
[admin@89 ~]$ exit
logout
Connection to node89 closed.
[admin@60 ~]$ ssh node145
Last login: Sun Mar 8 20:52:26 2020 from 172.16.0.11
[admin@145 ~]$ exit
logout
Connection to node145 closed.
[admin@60 ~]$ ssh node60
Last login: Sun Mar 8 20:52:16 2020 from 172.16.0.11
[admin@60 ~]$ exit
logout
Connection to node60 closed.
到此,主机之间设置免密完成。
6、安装Zookeeper
安装详解参考:
ZooKeeper集群搭建
ZooKeeper安装与配置
CentOS7.5搭建Zookeeper集群与命令行操作
7、安装hadoop集群
7.1、下载hadoop安装包
http://archive.apache.org/dist/hadoop/core/
http://archive.apache.org/dist/hadoop/core/hadoop-2.7.6/hadoop-2.7.6.tar.gz
hadoop-2.7.6.tar.gz下载后存到/opt/software/
7.2、解压安装Hadoop
解压 hadoop-2.7.6到/opt/module/目录下
$ tar zxvf hadoop-2.7.6.tar.gz -C /opt/module/
7.2 配置Hadoop集群
配置文件都在/opt/module/hadoop-2.7.6/etc/hadoop/下
7.2.1 修改hadoop-env.sh, mapred-env.sh ,yarn-env.sh 的JAVA环境变量
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
注:export JAVA_HOME=${JAVA_HOME} 采用变量方式,会导致 hadoop-daemons.sh start datanode 执行失败
7.2.2 修改 core-site.xml
$ vim core-site.xml
<configuration>
<!-- 把两个NameNode的地址组装成一个集群mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.6/data/ha/tmp</value>
</property>
<!-- 指定ZKFC故障自动切换转移 -->
<property>
<name>ha.zookeeper.quorum</name>
<!-- <value>node60:2181,node89:2181,node145:2181</value> -->
<value>node145:2181</value>
</property>
<!--修改core-site.xml中的ipc参数,防止出现连接journalnode服务ConnectException-->
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>Indicates the number of retries a client will make to establish a server connection.</description>
</property>
</configuration>
7.2.3 修改hdfs-site.xml
$ vim hdfs-site.xml
<configuration>
<!-- 设置dfs副本数,默认3个 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中NameNode节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node60:8020</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node89:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node60:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node89:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node60:8485;node89:8485;node145:8485/mycluster</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh无秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/admin/.ssh/id_rsa</value>
</property>
<!-- 声明journalnode服务器存储目录-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/hadoop-2.7.6/data/ha/jn</value>
</property>
<!-- 关闭权限检查-->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
7.2.4 修改mapred-site.xml
$ mv mapred-site.xml.template mapred-site.xml
$ vim mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 指定mr历史服务器主机,端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node60:10020</value>
</property>
<!-- 指定mr历史服务器WebUI主机,端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node60:19888</value>
</property>
<!-- 历史服务器的WEB UI上最多显示20000个历史的作业记录信息 -->
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>20000</value>
</property>
<!--配置作业运行日志 -->
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/tmp/hadoop-yarn/staging</value>
</property>
</configuration>
7.2.5 修改 slaves
$ vim slaves
node60
node89
node145
7.2.6 修改yarn-site.xml
[admin@node21 hadoop]$ vim yarn-site.xml
<configuration>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--启用resourcemanager ha-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--声明两台resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmCluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node89</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node145</value>
</property>
<!--指定zookeeper集群的地址-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node60:2181,node89:2181,node145:2181</value>
</property>
<!--启用自动恢复-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
7.2.7 拷贝hadoop到其他节点
[admin@145 module]# scp -r hadoop-2.7.6/ admin@node60:/opt/module/
[admin@145 module]# scp -r hadoop-2.7.6/ admin@node89:/opt/module/
注:记得切换成admin用户操作
7.2.8 配置Hadoop环境变量
$ sudo vim /etc/profile
末尾追加
export HADOOP_HOME=/opt/module/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
编译生效 source /etc/profile
$ echo ${HADOOP_HOME}
8、启动集群
8.1、启动journalnode,三台机器都要执行(仅第一次启动hadoop时,需要这一步操作,之后不再需要手动启动journalnode),前提zookeeper集群已启动:
$ sudo mkdir -p /opt/module/hadoop-2.7.6/logs
$ sudo chown admin:admin /opt/module/hadoop-2.7.6/logs
$ ssh admin@node60 '/opt/module/hadoop-2.7.6/sbin/stop-all.sh';
$ ssh admin@node89 '/opt/module/hadoop-2.7.6/sbin/stop-all.sh';
$ ssh admin@node145 '/opt/module/hadoop-2.7.6/sbin/stop-all.sh';
$ ssh admin@node60 'rm -rf /opt/module/hadoop-2.7.6/data';
$ ssh admin@node89 'rm -rf /opt/module/hadoop-2.7.6/data';
$ ssh admin@node145 'rm -rf /opt/module/hadoop-2.7.6/data';
$ ssh admin@node60 'cd /opt/module/hadoop-2.7.6/sbin/;sh hadoop-daemon.sh start journalnode;';
$ ssh admin@node89 'cd /opt/module/hadoop-2.7.6/sbin/;sh hadoop-daemon.sh start journalnode;';
$ ssh admin@node145 'cd /opt/module/hadoop-2.7.6/sbin/;sh hadoop-daemon.sh start journalnode;';
启动Journalnde是为了创建/data/ha/jn,此时jn里面是空的
[admin@60 jn]$ cd /opt/module/hadoop-2.7.6/data/ha/jn
[admin@60 jn]$ ll
total 0
查看journalnode服务日志
$ tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-journalnode-145.out
$ tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-journalnode-145.log
注:hadoop-daemon.sh stop journalnode 关闭JournalNode节点
8.2、在[nn1]上,对namenode进行格式化,并启动:
[admin@node60 ~]$ cd /opt/module/hadoop-2.7.6/bin
[admin@node60 ~]$ hdfs namenode -format

格式化namenode,此时jn里面会产生集群ID等信息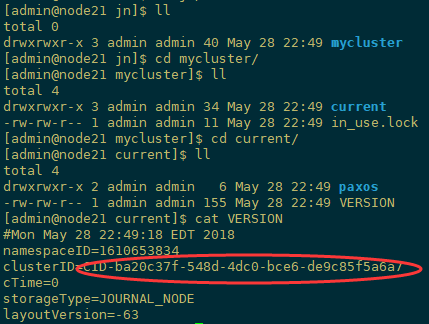
注:图片盗用别人的,node21对用我主机的node60
另外,/data/ha/tmp也会产生如下信息
注:图片盗用别人的,node21对用我主机的node60
启动nn1上namenode
[admin@60 sbin]$ hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.6/logs/hadoop-admin-namenode-node21.out
[admin@60 sbin]$ tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-namenode-60.out
[admin@60 sbin]$ tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-namenode-60.log
8.3、在[nn2]上,同步nn1的元数据信息:
[admin@89 bin]$ cd /opt/module/hadoop-2.7.6/bin
[admin@89 ~]$ hdfs namenode -bootstrapStandby
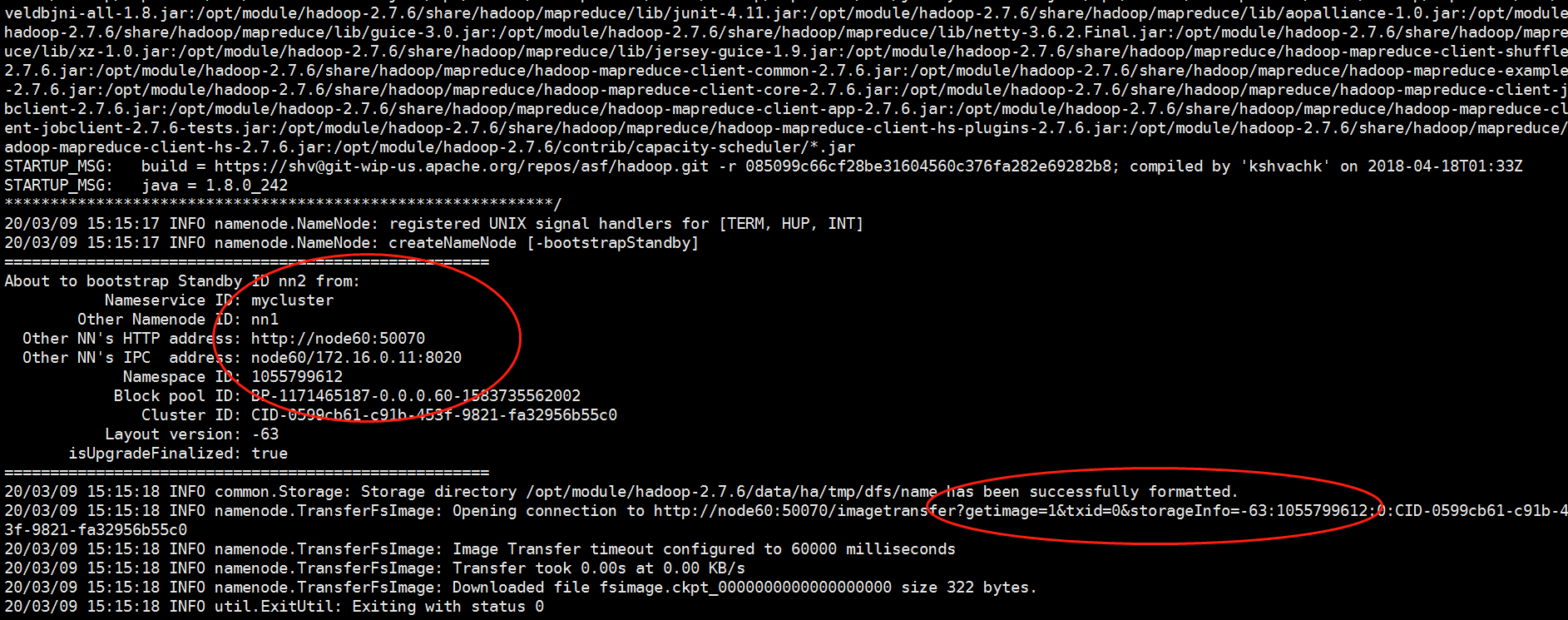
8.4、启动[nn2]:
[admin@89 sbin]$ hadoop-daemon.sh start namenode
8.5、在[nn1]上,启动所有datanode
[admin@60 sbin]$ hadoop-daemons.sh start datanode
8.6、查看web页面此时显示
http://182.*.*.60:50070
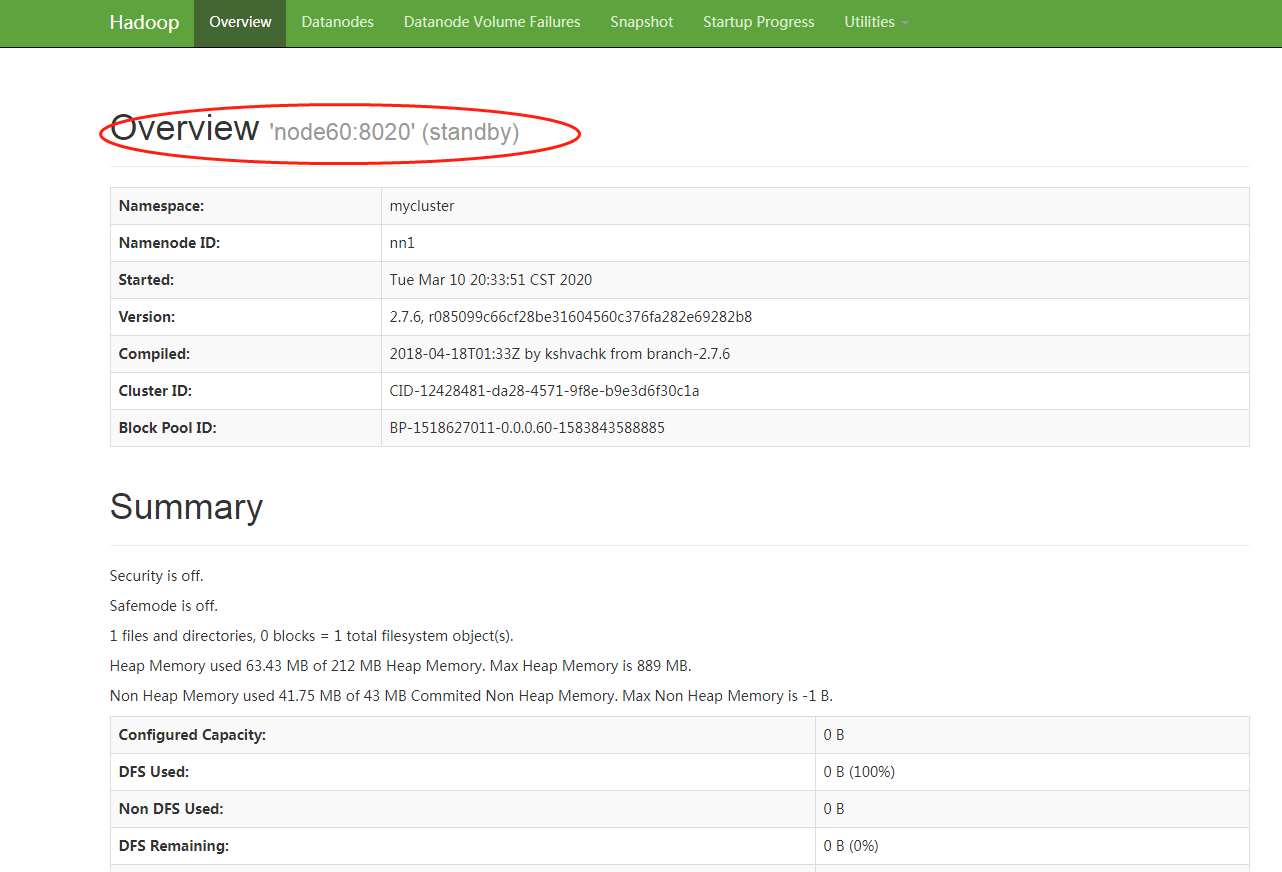
http://106.*.*.89:50070
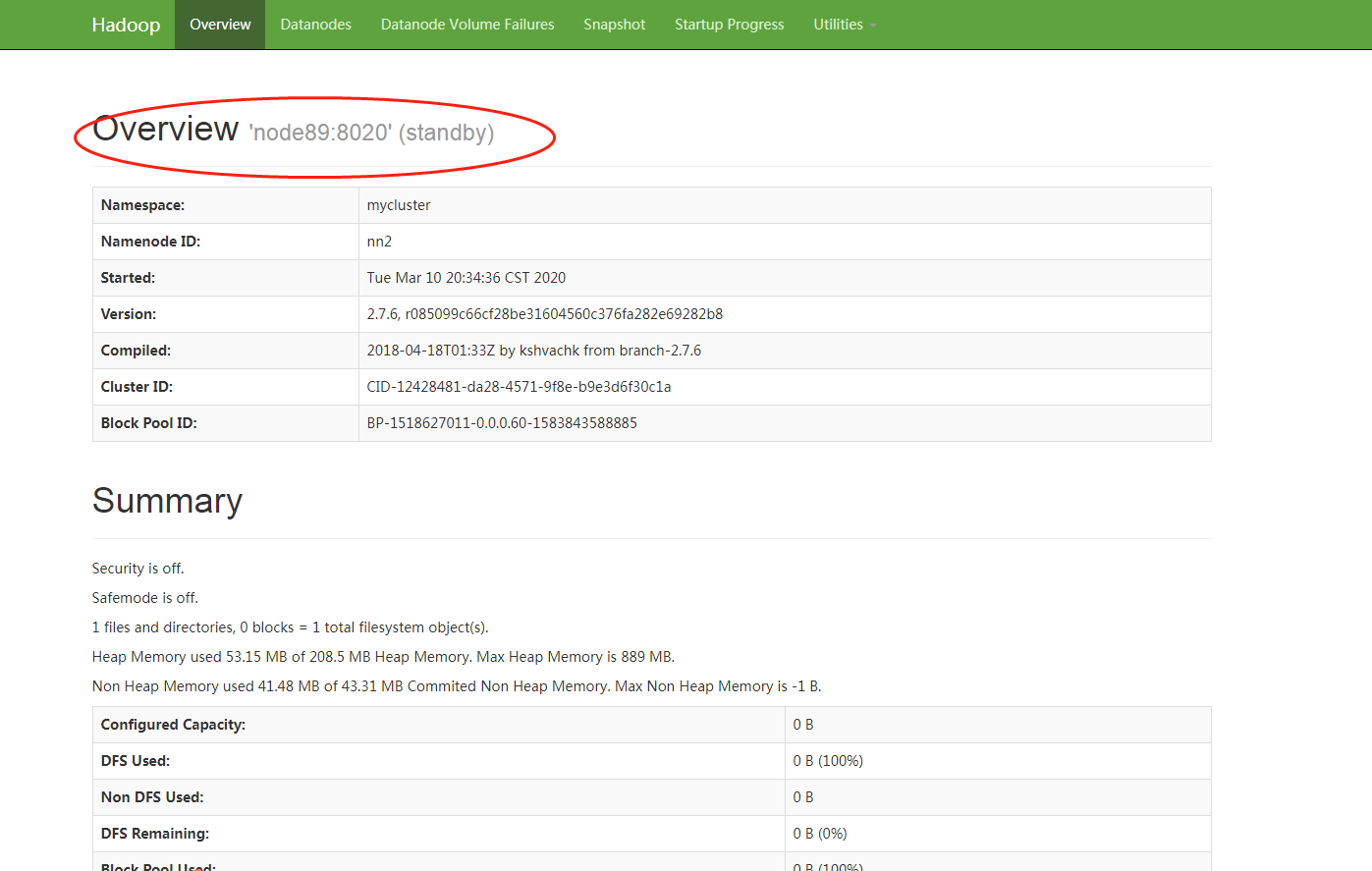
8.7、手动切换状态,在各个NameNode节点上启动DFSZK Failover Controller,先在哪台机器启动,哪个机器的NameNode就是Active NameNode
[admin@60 ~]$ hadoop-daemon.sh start zkfc
[admin@89 ~]$ hadoop-daemon.sh start zkfc
或者强制手动其中一个节点变为Active
[admin@60 data]$ hdfs haadmin -transitionToActive nn1 --forcemanual
Web页面查看
Overview 'node60:8020' (active)
Overview 'node89:8020' (standby)
8.8、自动切换状态,需要初始化HA在Zookeeper中状态,先停掉hdfs服务,然后随便找一台zookeeper的安装节点
[admin@60 current]$ hdfs zkfc -formatZK
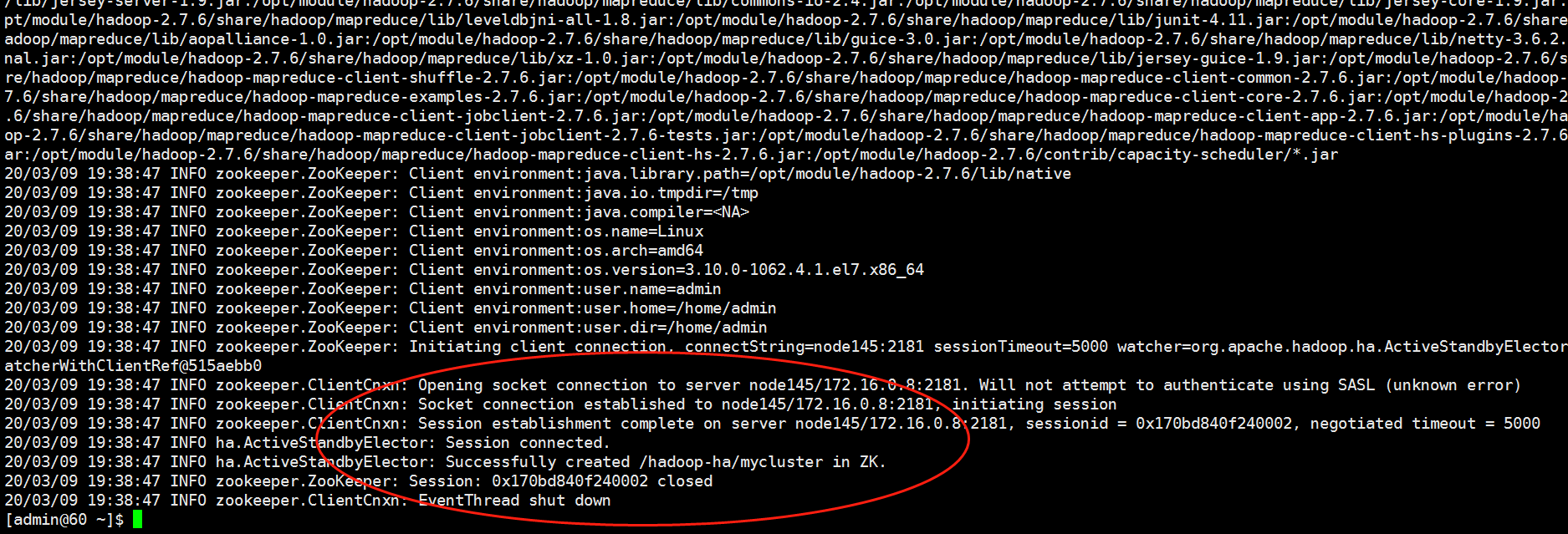
查看,此时会产生一个hadoop-ha的目录
[admin@145 ~]# cd /opt/module/zookeeper-3.4.6/bin
[admin@145 bin]$ ./zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, hadoop-ha]
[zk: localhost:2181(CONNECTED) 1]
启动hdfs服务,查看namenode状态
[admin@60 ~]$ ./start-dfs.sh
8.9、测试namenode高可用
8.9.1、在node60上kill掉namenode进程,然后通过浏览器查看node89的状态,发现状态变为active,说明高可用测试成功
[admin@60 sbin]$ jps
20441 NameNode
24523 Jps
20172 JournalNode
24430 DFSZKFailoverController
21278 DataNode
[admin@60 sbin]$ kill -9 20441
8.9.2、重新启动node60的namenode进程,sh start-dfs.sh,浏览器访问node60,此时node60的状态为standby
[admin@60 sbin]$ hadoop-daemon.sh start journalnode
[admin@60 sbin]$ sh start-dfs.sh
至此,hadoop高可用集群搭建完毕。
9、启动yarn
9.1、在node89中执行:
[admin@89 ~]$ cd /opt/module/hadoop-2.7.6/sbin
[admin@89 ~]$ start-yarn.sh
9.2、在node145中执行:
[admin@89 ~]$ cd /opt/module/hadoop-2.7.6/sbin
[admin@145 ~]$ yarn-daemon.sh start resourcemanager
9.3、查看服务状态
[admin@145 sbin]$ yarn rmadmin -getServiceState rm1
standby
[admin@145 sbin]$ yarn rmadmin -getServiceState rm2
active
[admin@145 sbin]$
10、查看启动journalnode日志
ssh admin@node60 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-journalnode-60.log';
ssh admin@node89 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-journalnode-89.log';
ssh admin@node145 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-journalnode-145.log';
ssh admin@node60 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-namenode-60.log';
ssh admin@node89 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-namenode-89.log';
ssh admin@node60 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-zkfc-60.log';
ssh admin@node89 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/hadoop-admin-zkfc-89.log';
ssh admin@node60 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/yarn-admin-nodemanager-60.log';
ssh admin@node89 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/yarn-admin-nodemanager-89.log';
ssh admin@node89 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/yarn-admin-resourcemanager-89.log';
ssh admin@node145 'tail -f -n 1000 /opt/module/hadoop-2.7.6/logs/yarn-admin-nodemanager-145.log';
配置集群常见错误
1、执行yum提示错误:rpmdb: BDB0113 Thread/process 424227/139826856310848 failed
解决方案:https://blog.csdn.net/qq_41688455/article/details/86690143
2、hadoop-daemon.sh start journalnode启动失败
2020-03-09 14:20:03,099 INFO org.apache.hadoop.hdfs.qjournal.server.JournalNode: registered UNIX signal handlers for [TERM, HUP, INT]
2020-03-09 14:20:03,303 ERROR org.apache.hadoop.hdfs.qjournal.server.JournalNode: Failed to start journalnode.
org.apache.hadoop.util.DiskChecker$DiskErrorException: Cannot create directory: /opt/module/hadoop-2.7.6/data/ha/jn
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:106)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.validateAndCreateJournalDir(JournalNode.java:118)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.start(JournalNode.java:138)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.run(JournalNode.java:128)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:84)
at org.apache.hadoop.hdfs.qjournal.server.JournalNode.main(JournalNode.java:299)
2020-03-09 14:20:03,309 INFO org.apache.hadoop.util.ExitUtil: Exiting with status -1
2020-03-09 14:20:03,311 INFO org.apache.hadoop.hdfs.qjournal.server.JournalNode: SHUTDOWN_MSG:
解决方案:
$ sudo chown admin:admin hadoop-2.7.6/
3、2020-03-13 17:15:20,059 WARN org.apache.hadoop.hdfs.server.common.Storage: Failed to add storage directory [DISK]file:/opt/module/hadoop-2.7.6/data/ha/tmp/dfs/data/
java.io.IOException: Incompatible clusterIDs in /opt/module/hadoop-2.7.6/data/ha/tmp/dfs/data: namenode clusterID = CID-1e9a7844-9d48-4d66-be81-5ee83e19a482; datanode clusterID = CID-0599cb61-c91b-453f-9821-fa32956b55c0
由于多次格式化命令所致(/opt/module/hadoop-2.7.6/bin/hdfs namenode -format)
解决方法:
停止Hadoop服务,删除/opt/module/hadoop-2.7.6/data下的所有文件,然后重新格式化,再启动就好了.
ssh admin@node60 'rm -rf /opt/module/hadoop-2.7.6/data';
ssh admin@node89 'rm -rf /opt/module/hadoop-2.7.6/data';
ssh admin@node145 'rm -rf /opt/module/hadoop-2.7.6/data';
参考文章:
CentOS7.5搭建Hadoop2.7.6完全分布式集群
hadoop高可用集群搭建