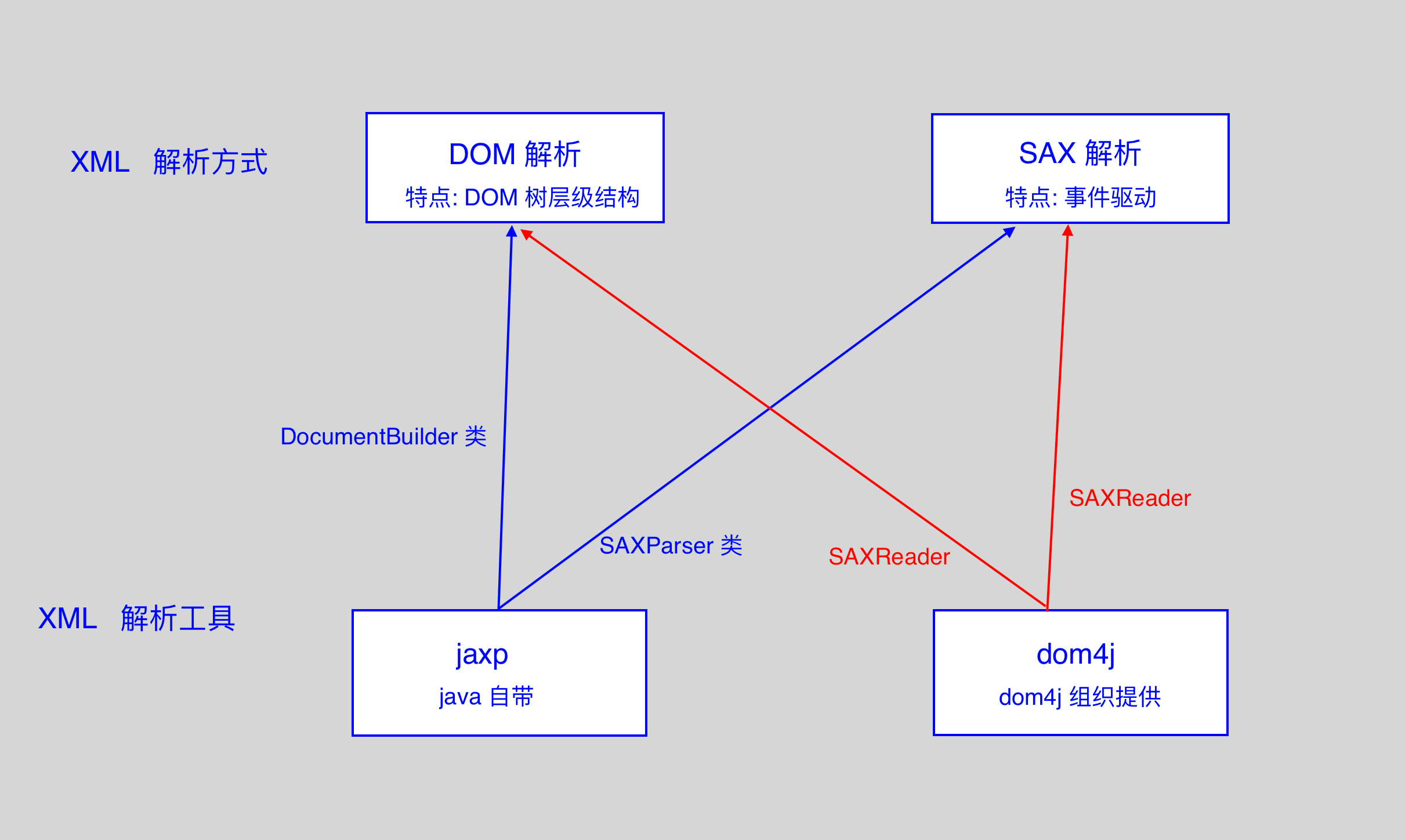
- XML 的解析方式有两种方式: DOM 解析和 SAX 解析.
- DOM 解析: 根据 XML 的层级结构, 在内存中分配一个树形结构, 把 XML 的标签, 属性和文本都封装成对象.
- 优点: 可以实现增删改查操作
- 弊端: 如果文件过大, 容易造成内存溢出
- SAX 解析: 采用事件驱动, 边读边解析. 从上到下, 一行一行的解析, 解析到某一个对象, 把对象返回.
- 优点: 可以方便的实现查询
- 不能实现增删改操作
- XML 解析器
- jaxp 解析器, 由 SUN 公司提供的针对 dom 和 sax 的解析器
- dom4j 解析器, 由 dom4j 组织提供的针对 dom 和 sax 的解析器
jaxp 解析器
- jaxp 解析器在 JDK 的 javax.xml.parsers 包里面
- DOM 解析使用到的类:
- DocumentBuilder : 解析器类
- DocumentBuildreFactory : 解析器工厂类
- SAX 解析使用到的类:
- SAXParser : 解析器类
- SAXParserFactory : 解析器工厂
jaxp 解析器的 DOM 方式解析 xml 文件
- DocumentBuilder 解析器类
- 该解析器类是一个抽象类, 不能 new. 此类的实例可以从
DocumentBuilderFactory.newDocumentBuilder()方法获取. - 解析 xml 文档, 使用解析器类中的
parse("xml 路径");方法, 返回的是 Document 对象, 其父接口为 Node - Document 对象中的方法:
getElementsByTagName(String tagname);: 获取标签, 返回的是 NodeList 集合createElement(String tagName);: 创建标签createTextNode(String data);: 创建文本appendChild(Node newChild);: 将文本添加到标签下面
- 该解析器类是一个抽象类, 不能 new. 此类的实例可以从
- DocumentBuilderFactory 解析器工厂
- 该解析器工厂也是一个抽象类, 不能直接 new. 以
DocumentBuilderFactory.newInstance()获取对应的实例.
- 该解析器工厂也是一个抽象类, 不能直接 new. 以
- 使用 jaxp 解析器实现对 xml 文档的增删改查
// 示例:
// xml 文件
<?xml version="1.0" encoding="gbk"?>
<person>
<p1>
<name>zhangsan</name>
<age>20</age>
</p1>
<p1>
<name>lisi</name>
<age>32</age>
</p1>
</person>
// 查询: 查询 xml 文件中所有的 name 元素的值
/*
* 思路:
* 1. 创建解析器工厂
* 2. 根据解析器工厂创建解析器
* 3. 解析 xml 返回 document, 需要导包, org.w3c.dom.Document
* 4. 使用 document 对象中的 getElementsByTagName() 方法, 获取 NodeList 集合
* 5. 遍历集合, 获取每一个 name 对应的值
*/
public class TestJaxp {
public static void main(String[] args){
// 1. 创建解析器工厂
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
// 2. 根据解析器工厂创建解析器
DocumentBuilder builder = builderFactory.newDocumentBuilder();
// 3. 解析 xml 文档
Document document = builder.parser("src/person.xml");
// 4. 得到 name 元素
NodeList list = document.getElementsByTagName("name");
// 5. 遍历集合, 得到每一个 name 元素, NodeList 接口位于 org.w3c.dom 包下
for(int i=0; i<list.getLength(); i++){
Node name1 = list.item(i);
// 得到 name 元素里面的值
String s = name1.getTextContent();
System.out.println("name:"+s);
}
}
}
// 添加: 在第一个 p1 下面添加 <sex>male</sex>
/*
* 思路:
* 1. 创建解析器工厂
* 2. 根据解析器工厂创建解析器
* 3. 解析 xml 文档返回 document
* 4. 获取第一个 p1 元素
* 5. 创建 sex 标签, createElement
* 6. 创建文本 "male", createTextNode
* 7. 把文本添加到 sex 下面, appendChild()
* 8. 把 sex 添加到第一个 p1 下面
*
*
* 9. 回写 xml 文档(将内存中的数据写入到硬盘中)
* 9.1 创建 TransformerFactory 工厂
* 9.2 创建 Transformer 类
* 9.3 回写
*/
public class TestJaxp{
public static void main(String[] args){
// 1. 创建解析器工厂
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
// 2. 创建解析器
DocumentBuilder builder = builderFactory.newDocumentBuilder();
// 3. 解析 xml 文档
Document document = builder.parse("src/person.xml");
// 4. 获取所有 p1 元素
NodeList list = document.getElementsByTagName("p1");
// 5. 获取第一个 p1 元素
Node p1 = list.item(0);
// 6. 创建 sex 标签
Element sex1 = document.createElement("sex");
// 7. 创建 "male" 文本
TextNode text1 = document.createTextNode("male");
// 8. 将文本添加到 sex 标签下, 没有返回值
sex1.appendChild(text1);
// 9. 将 sex 标签添加到 p1 下面
p1.appendChild(sex1);
// 10. 回写 xml
// 创建 TransformerFactory 工厂
TransformerFactory transformerFactory = TransformerFactory.newInstance();
// 得到 Transformer 类
Transformer transformer = transformerFactory.newTransformer();
// 回写
// transform(Source xmlSource, Result outputTarget);
// Source 是接口, DOMSource 是其中的一个实现类.
// Result 也是接口, StreamResult 是其中的一个实现类
transformer.transform(new DOMSource(document), new StreamResult("src/person.xml"));
}
}
// 升级版, 把获取 document 对象封装成方法,
// 只要对 xml 文档进行增删改操作, 都需要回写 xml , 因此回写 xml 也封装成一个方法
public class JaxpUtils{
// 返回 document 对象
public static Document getDocument(String path){
// 有异常需要 try/catch
try{
// 1. 创建解析器工厂
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
// 2. 根据解析器工厂创建解析器
DocumentBuilder builder = builderFactory.newDocumentBuilder();
// 3. 解析 xml 文档,获取 document 对象
Document document = builder.parser(path);
// 4. 将结果返回
return document;
} catch (Exception e){
e.printStackTrace();
}
// 如果出现异常, 返回 null
return null;
}
// 回写 xml 操作
public static void xmlTransform(Document document, String path){
try{
// 1. 创建 TransformerFactory 工厂
TransformerFactory transformerFactory = TransformerFactor.newInstance();
// 2. 得到 Transformer 类
Transformer transformer = transformerFactory.newTransformer();
// 3. 使用 transform 方法进行回写
transformer.transform(new DOMSource(document), new StreamResult(path));
} catch(Exception e){
e.printStackTrace();
}
}
}
// 删除: 删除 p1 下面的 <sex>male</sex>
public void remSex(){
// 1. 获取 document 对象
Document document = JaxpUtils.getDocument("src/person.xml");
// 2. 获取 sex 标签
NodeList list = document.getElementsByTagName("sex")
Node sex1 = list.item(0);
// 3. 使用 sex 的父节点并删除 sex,
// 获取父节点, 使用 getParentNode 方法
sex1.getParentNode.removeChild(sex1);
// 4. 回写 xml
JaxpUtils.xmlTransform(document,"src/person.xml");
}
// 使用 jaxp 遍历节点, 也就是把 xml 中的所有元素名称打印出来
/*
* 思路: 使用递归实现遍历
* 1. 得到根节点
* 2. 得到根节点的子节点
* 3. 得到根节点的子节点的子节点
*/
public static void listElement(String path) throws Exception{
// 1. 获取 document 对象
Document document = JaxpUtils.getDocument("src/person.xml");
// 2. 编写一个方法实现遍历
list2(document);
}
// 因为 Node 是 Document 的父接口
// list(Document document) 升级为 list(Node node)
public static void list2(Node node){
// 判断是否是元素, 如果是, 就输出
// 如果不判断, 会把空格和换行当成内容也打印出来
if(node.getNodeType() == Node.ELEMENT_NODE){
System.out.println(node.getNodeName);
}
// 得到第一层子节点
NodeList list = node.getChildNodes();
// 遍历 list
for(int i=0; i<list.getLength(); i++){
// 得到每一个节点
Node node2 = list.item(i);
// 递归
list2(node2);
}
}
jaxp 解析器的 SAX 方式解析 xml 文件
- SAX 方式解析 xml 文档, 只能实现对文档的查询操作,不能实现增删改操作.
- SAXParser 解析器
- 该解析器的实例通过
SAXParserFactory.newSAXParser()方法获得 - 解析 xml 文档, 使用解析器类中的
parse(String uri, DefaultHandler dh);方法, 返回值为 void String uri: xml 文档的路径DefaultHandler dh: 事件处理器, 相当于在 parse() 方法上绑定了一个事件
- 该解析器的实例通过
- SAXParserFactory 解析器工厂
- 通过
newInstance()方法获得
- 通过
- 使用 jaxp 的 SAX 方式解析 xml 文档
// DefaultHandler 说明
// 1. DefaultHandler 中有三个方法: startElement, characters, endElement
// 2. 当解析到开始标签时, 自动执行 startElement 方法,
// 3. 当解析到文本内容时, 自动执行 characters 方法
// 4. 当解析到标签结束时, 自动执行 endElement 方法
// 示例:
// xml 文件
<?xml version="1.0" encoding="gbk"?>
<person>
<p1>
<name>zhangsan</name>
<age>20</age>
</p1>
<p1>
<name>lisi</name>
<age>32</age>
</p1>
</person>
// 需求一: 打印 xml 文档中所有元素
/*
* 思路:
* 1. 创建解析器工厂
* 2. 创建解析器
* 3. 执行 parse 方法
*
* 4. 自己创建一个类, 继承 DefaultHandler
* 5. 重写类里面的三个方法
* /
public class TestJaxp{
public static void main(String[] args){
// 1. 创建解析器工厂
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
// 2. 创建解析器
SAXParser saxParser = saxParserFactory.newSAXParser();
// 3. 执行 parse 方法, 并传入自定义的事件处理器
saxParser.parse("src/person.xml", new MyDefault2());
}
}
// 打印整个文档的事件处理器
class MyDefault2 extends DefaultHandler{
// 重写 startElement
public void startElement(String uri, String localName, String qname,
Attributes attributes) throws SAXException{
System.out.print("<"+qName+"/>"); // qName 表示的是标签名, 此处输出的是开始标签
}
// 重写 characters 方法
public void characters(char[] ch, int start, int length) throws SAXException{
System.out.print(new String(ch,start,length)); // 打印元素中的文本
}
// 重写 endElement 方法
public void endElement(String uri, String localName, String qName) throws SAXException{
System.out.print("</"+qName+">"); // qName 表示的是标签名, 此处输出的是结束标签
}
}
// 获取所有的 name 元素的值, 事件处理器
class MyDefault3 extends DefaultHandler{
// 定义变量
boolean flag = false;
// 重写 startElement
public void startElement(String uri, String localName, String qname,
Attributes attributes) throws SAXException{
// 判断 qName 是否是 name 元素
if("name".equals(qName)){
flag = true;
}
}
// 重写 characters 方法
public void characters(char[] ch, int start, int length) throws SAXException{
// 如果 flag 值是 true 的时候, 表示解析到的是 name 元素
if(flag){
System.out.println(new String(ch,start,length));
}
}
// 重写 endElement 方法
public void endElement(String uri, String localName, String qName) throws SAXException{
// 重置 flag 标记, 表示 name 元素读取结束
if("name".equals(qName)){
flag = false;
}
}
}
// 获取第一个 name 元素中的值
class MyDefault3 extends DefaultHandler{
// 定义变量
boolean flag = false;
int count=1;
// 重写 startElement
public void startElement(String uri, String localName, String qname,
Attributes attributes) throws SAXException{
// 判断 qName 是否是 name 元素
if("name".equals(qName)){
flag = true;
}
}
// 重写 characters 方法
public void characters(char[] ch, int start, int length) throws SAXException{
// 如果 flag 值是 true 的时候, 表示解析到的是 name 元素
if(flag && count == 1){
System.out.println(new String(ch,start,length));
}
}
// 重写 endElement 方法
public void endElement(String uri, String localName, String qName) throws SAXException{
// 重置 flag 标记, 表示 name 元素读取结束
if("name".equals(qName)){
flag = false;
count++;
}
}
}
参考资料: