一、什么是大数据
专业咨询公司IDC对大数据特征的定义: 4V
1、数据量(Volume): TB,PB级别以上。
2、多样性,复杂性(Variety): 结构化数据(关系型数据库),文件,视频,音频、图像,地理位置
3、基于高度分析的新价值(Value): 价值密度比较低,比如1个小时的视频,只有1分钟是有价值的。
4、速度(Velocity): 处理速度,原来处理方式比较久如每天处理一次。现在要求实时处理。
二、大数据带来的技术变革
1、计算瓶颈(原来都是单机计算的,现在数据越来越大,如超过100G,单机处理不过来了)。
解决方法: 单机转集群。
2、存储瓶颈
解决方式:分布式存储,不同的块存在不同的机器里,而且是多副本存储。
3、数据库瓶颈
原来存储在关系型数据库,如Oracle,MySQL等,即使它们有集群的方式,但是存储还是有限的。
解决方式: 采用NoSQL数据库,如Redis,HBASE来满足大数据存储的需求。
三、Hadoop概述
1、什么是Hadoop
一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。
Hadoop包括Distributed File System(HDFS) 分布式文件系统,YARN,MapReduce。
官网地址:
Hadoop: hadoop.apache.org
Hive: hive.apache.org
Spark: spark.apache.org
HBase: hbase.spache.org
2、Hadoop包括的模块
Hadoop Common: The common utilities that support the other Hadoop modules.
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
Hadoop Ozone: An object store for Hadoop
3、狭义Hadoop和广义Hadoop
狭义的Hadoop: 是一个适合大数据分布式存储(HDFS)、分布式计算(MapReduce)和资源调度(YARN)的平台。
广义的Hadoop: 指的是Hadoop生态系统,Hadoop生态系统是一个很庞大的概念,hadoop是其中最重要最基础的一部分;生态系统中的每一个子系统只解决某一个特定的问题域(甚至可能很窄),不搞统一型的一个全能系统,而是小而精的多个小系统
4、Hadoop生态圈(广义Hadoop)
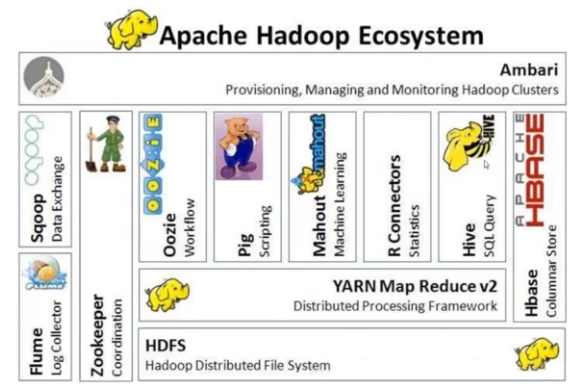
图片来自官网: https://hadoop.apache.org/docs/r3.2.2/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
为什么很多公司选择Hadoop作为大数据平台的解决方案?
1) 源码开源
2) 社区活跃、参与者很多,如Spark
3) 涉及到分布式存储和计算的方方面面:
Flume进行数据采集
Spark/MR/Hive等进行数据处理
HDFS/HBase进行数据存储
4) 已得到企业界认证
三、分布式文件系统HDFS
1、什么是HDFS
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS
源自于Google的GFS论文
发表与2003年,HDFS是GFS的克隆版
2、HDFS的设计目标
1) 非常巨大的分布式文件系统
2) 运行在普通廉价的硬件上
3) 易扩展、为用户提供性能不错的文件存储服务。
3、HSDS架构
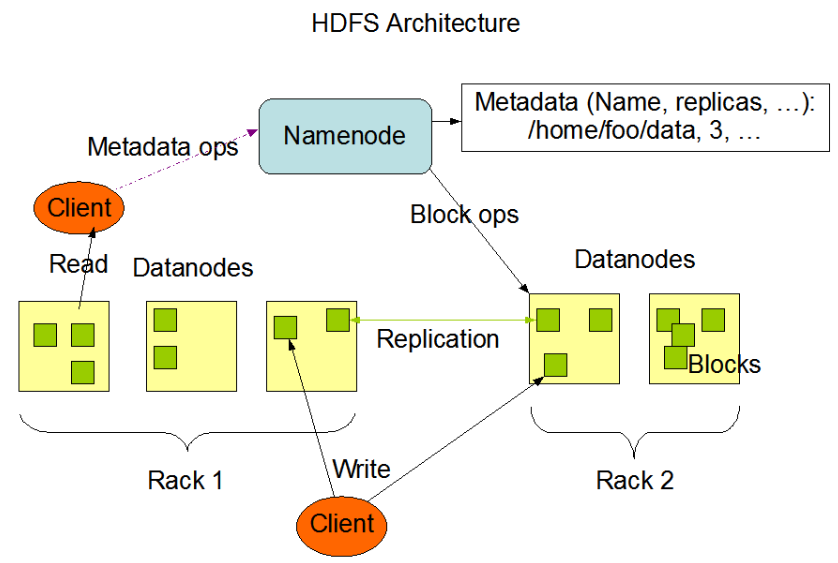
图片来自官网: https://hadoop.apache.org/docs/r3.2.2/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
1个Master(NameNode,简称NN),多个Slave(DataNode,简称DN)
1个文件会被拆分成多个Block(块)
blocksize: 128M
例如130M文件会被拆分成2个Block,一个128M和2M
NN职责:
1) 负责客户端请求的响应
2) 负责元数据(文件的名称、副本系数、Block存放的DN)的管理
DN职责
1) 存储用户的文件对应的数据块(Block)
2) 要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
建议: NN和DN部署在不同的节点上
Client:
就是你的操作,比如HDFS的Shell文件或者Java API的一些文件
4、HDFS副本机制
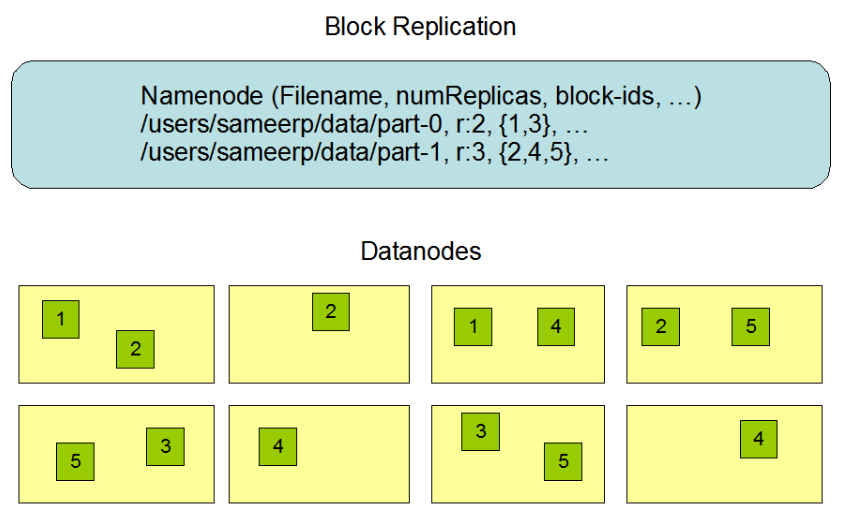
文件名 ,副本数,块ID
如文件名part-0, r:2 副本数为2, 块号为1号和3号
文件名part-1, r:3 副本数为3, 块号为2号,4号和5号
数据有多个副本,目的是为了容错。