一、文本的预处理---文本转数字列表
TensorFlow的Keras库有文本预处理功能。Tokenizer是一个用于向量化文本,或将文本转换为序列(即单词在字典中的下标构成的列表,从1算起)的类。如下面示例的:
- ['ha ha gua angry','howa ha gua excited naive'],按照每个词的位置重新编号为
- [[1, 1, 2, 3], [4, 1, 2, 5, 6]] 表示每个词在文本的索引位置。每个词只有一个索引。
实验代码如下:
import tensorflow as tf
somestr = ['ha ha gua angry','howa ha gua excited naive']
tok = tf.keras.preprocessing.text.Tokenizer(num_words=20)
tok.fit_on_texts(somestr) #装入文档,转数字列表
train_sequences=tok.texts_to_sequences(somestr)
print(train_sequences)
x_train=tf.keras.preprocessing.sequence.pad_sequences(train_sequences, #补齐,每行字符串用10列表示,不够补0
padding="post",
truncating="post",
maxlen=10)
#x_train输出结果为:
[[1 1 2 3 0 0 0 0 0 0]
[4 1 2 5 6 0 0 0 0 0]]
二、词嵌入层设计--数字序列转成词向量表示
文档转数字表示后,还是不便于表示词的特征。需要对数字再次编码。如以下某个文本的数字列表如下:
我 从 哪 里 来 要 到 何 处 去
0 1 2 3 4 5 6 7 8 9`
1.One-Hot 编码
one-hot编码,one-hot编码的优势就体现出来了,计算方便快捷、表达能力强。稀疏矩阵做矩阵计算的时候,只需要把1对应位置的数相乘求和就行。
# 我从哪里来,要到何处去
[
[1 0 0 0 0 0 0 0 0 0]
[0 1 0 0 0 0 0 0 0 0]
[0 0 1 0 0 0 0 0 0 0]
[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 0 1 0 0 0]
[0 0 0 0 0 0 0 1 0 0]
[0 0 0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 0 0 0 1]
]
最明显的缺点。过于稀疏时,过度占用资源。比如:中文大大小小简体繁体常用不常用有十几万,然后一篇文章100W字,你要表示成100W X 10W的矩阵?这时,Embedding层横空出世。Embedding降维度功能。
所以,embedding层做了个什么呢?它把我们的稀疏矩阵,通过一些线性变换(在CNN中用全连接层进行转换,也称为查表操作),变成了一个密集矩阵,这个密集矩阵用了N(例子中N=3)个特征来表征所有的文字,在这个密集矩阵中,表象上代表着密集矩阵跟单个字的一一对应关系,实际上还蕴含了大量的字与字之间,词与词之间甚至句子与句子之间的内在关系(如:我们得出的王妃跟公主的关系)。他们之间的关系,用的是嵌入层学习来的参数进行表征。从稀疏矩阵到密集矩阵的过程,叫做embedding,很多人也把它叫做查表,因为他们之间也是一个一一映射的关系。embedding后的词向量表示如下:
公 [ 0.5 0.125 0.5]
主 [ 0.5 0.125 0.5]
王 [ 0.3 0.375 0.5]
妃 [ 0.3 0.375 0.5]
更重要的是,这种关系在反向传播的过程中,是一直在更新的,因此能在多次epoch后,使得这个关系变成相对成熟,即:正确的表达整个语义以及各个语句之间的关系。这个成熟的关系,就是embedding层的所有权重参数。
2.embedding 嵌入层代码调试
model = keras.models.Sequential()
model.add(keras.layers.Embedding(input_dim=10, output_dim=2, input_length=10))
#input_dim:字典长度,即输入数据最大下标+1 ,有多少个文本。output_dim:大于0的整数,代表全连接嵌入的维度,nput_length:当输入序列的长度固定时,该值为其长度。
#该层输入数据个数:10,每个数据词向量维度为2,数据有10个。
#输入形如(samples,sequence_length)的2D张量。这里是个二维数据,一维数组务必再加一层[],改二维。
#输出形如(samples, sequence_length, output_dim)的3D张量,(1,(10,2))
model.compile('rmsprop', 'mse')
print(model.summary())
p=model.predict([[1, 1, 2, 3,0,0,0,0,0,0]])
#p的输出结果如下:
[[[-0.04306092 -0.03373697]
[-0.04306092 -0.03373697]
[-0.03351045 -0.03122779]
[ 0.01788462 0.0147854 ]
[ 0.01061829 -0.00132079]
[ 0.01061829 -0.00132079]
[ 0.01061829 -0.00132079]
[ 0.01061829 -0.00132079]
[ 0.01061829 -0.00132079]
[ 0.01061829 -0.00132079]]]
三、keras建模与应用
建多层神经网路模型
- 输入层:7个神经元+一个偏置项
- 隐藏层1:64个神经元
- 隐藏层2:32个神经元
- 输出层:1个神经元
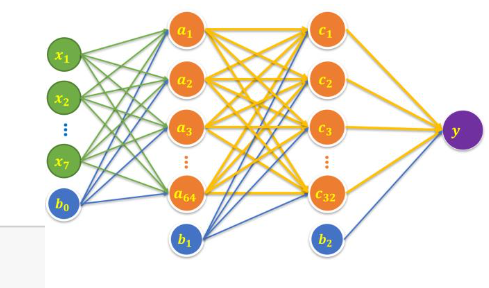
1. 模型搭建
情感评论模型构建的代码:
import tensorflow as tf
model=tf.keras.models.Sequential() #序列化
model.add(tf.keras.layers.Embedding(output_dim=32, #词向量输出为32维度的0,1编码
input_dim=4000,
input_length=400))
model.add(tf.keras.layers.Flatten()) #类似池化
model.add(tf.keras.layers.Dense(units=256,activation="relu")) #全连接隐藏层
model.add(tf.keras.layers.Dropout(0.3)) #丢弃层
model.add(tf.keras.layers.Dense(units=2,activation='sigmoid'))#输出层
model.compile(optimizer='adam',loss="binary_crossentropy",
metrics=['accuracy']) #loss为损失函数,二分类选择binary_crossentropy,多分类选择categorical_crossentropy
print(model.summary())
history=model.fit(x_train,y_train,validation_split=0.2,
epochs=10,batch_size=128,verbose=1) #batch_size一次带128个数据进去
#x_train:训练数据集,y_train为标签数据集,用ont-hot编码。若[1,0]表示正向,[0,1】表示负向。
#多分类的one-hot编码[1,0,0,0]
model.save("d:/film.h5") #模型保存
2.模型可视化
静待
3.模型评估
test_loss,test_acc=model.evaluate(x_test,y_test,verbose=1) #verbose为1,可以看到每轮训练结果
print("test accuracy:",test_acc)
4.模型预测
predictions=model.predict(x_test)
print(predictions[0])
结果如下:
[9.9994373e-01 5.6257828e-05],表示正向。