提升的概念

提升算法

提升算法推导



梯度提升决策树



决策树的描述

正则项的定义

目标函数的计算
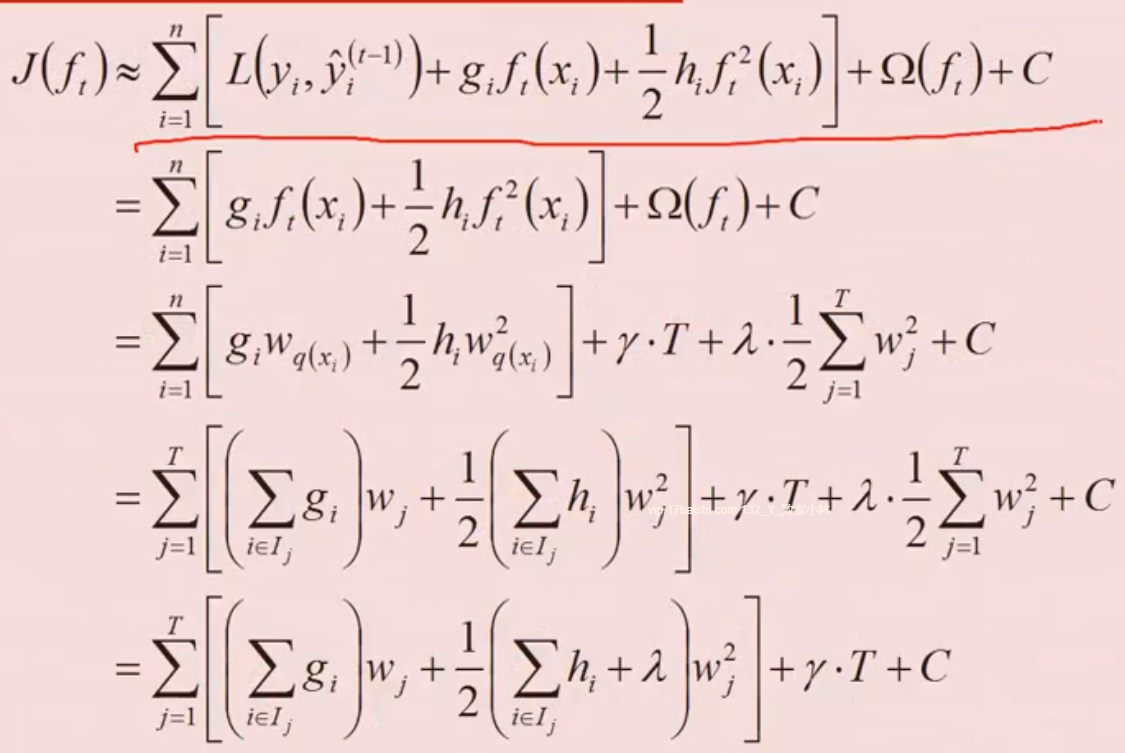
- 目标函数继续化简

- 子树划分

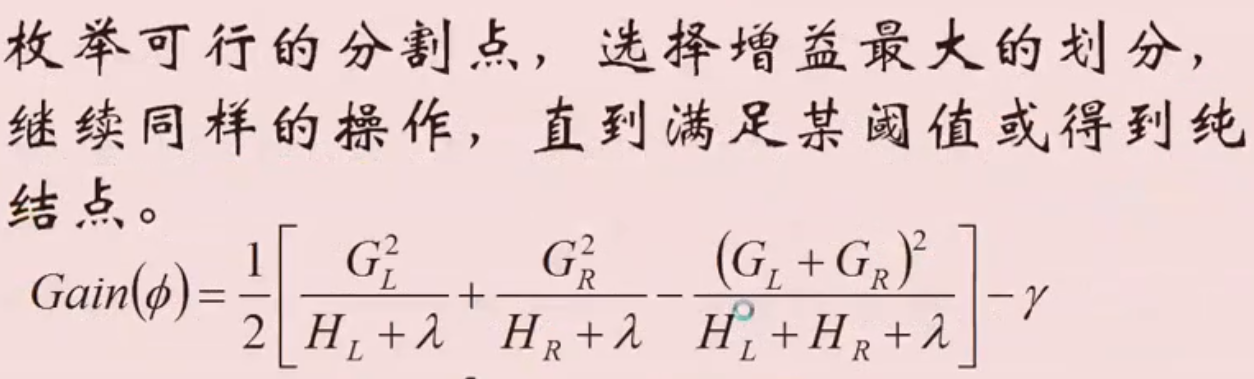
Adaboost
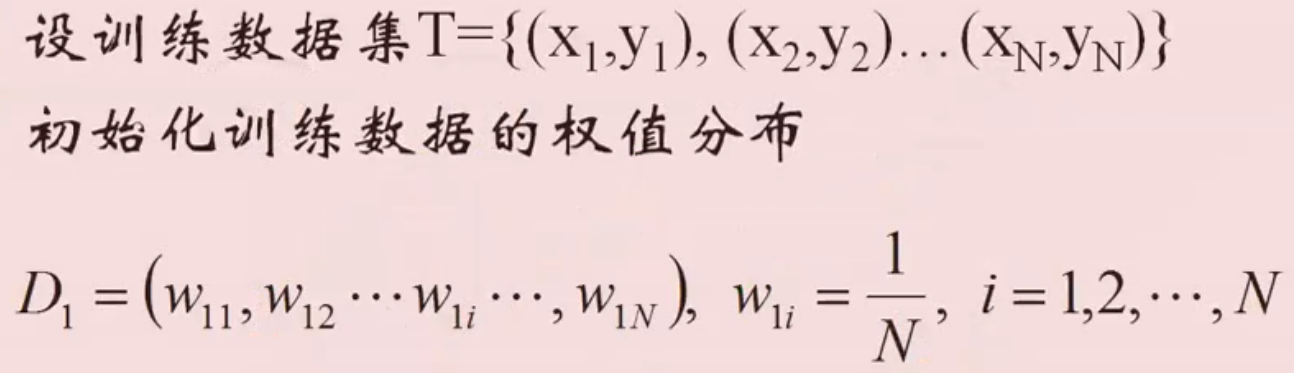



误差上限

方差与偏差
- Bagging能够减少训练方差,对于不剪枝的决策树、神经网络等学习器有良好的集成效果
- Boosting减少偏差,能够基于泛化能力较弱的学习器构造强学习器
boost算法
-
Boosting分类方法,其过程如下所示:
-
先通过对N个训练数据的学习得到第一个弱分类器h1;
-
将h1分错的数据和其他的新数据一起构成一个新的有N个训练数据的样本,通过对这个样本的学习得到第二个弱分类器h2;
-
将h1和h2都分错了的数据加上其他的新数据构成另一个新的有N个训练数据的样本,通过对这个样本的学习得到第三个弱分类器h3;
-
最终经过提升的强分类器h_final=Majority Vote(h1,h2,h3)。即某个数据被分为哪一类要通过h1,h2,h3的多数表决。
-
-
上述Boosting算法,存在两个问题:
-
如何调整训练集,使得在训练集上训练弱分类器得以进行。
-
如何将训练得到的各个弱分类器联合起来形成强分类器。
-
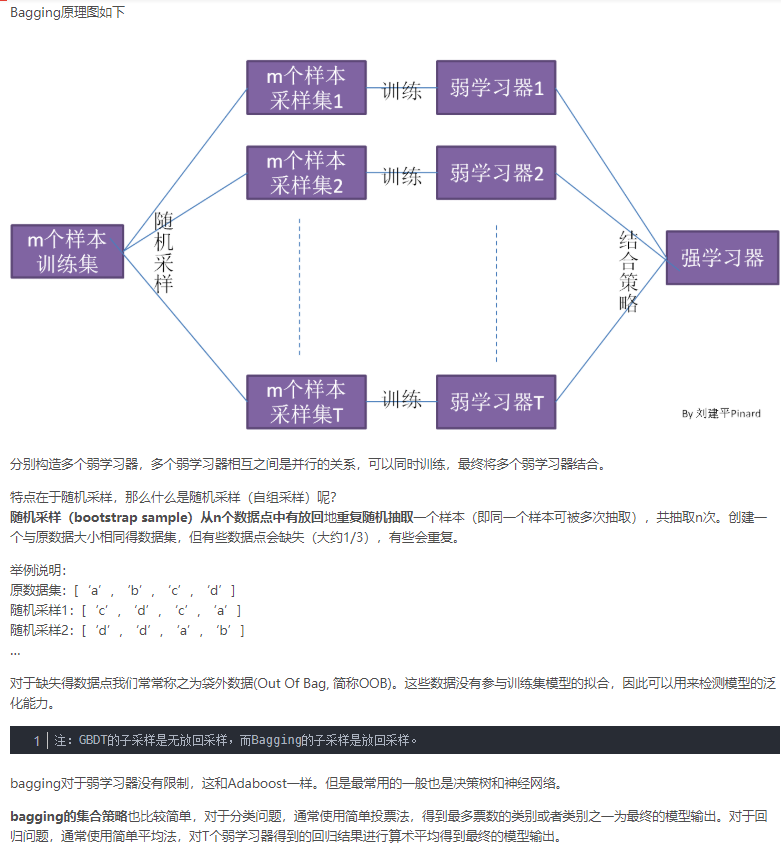
bagging算法
xgboost

数据预处理-清洗
