1.COW机制
Docker镜像由多个只读层叠加而成,启动容器时,Docker会加载只读镜像层并在镜像栈顶部添加一个读写层。
如果运行中的容器修改了现有的一个已经存在的文件,那么该文件将会从读写层下面的只读层复制到读写层,该文件的只读版本依然存在,只是已经被读写层中该文件的副本所隐藏,这就是“写时复制(COW)”机制。

对于这种方式来说,我们去访问一个文件,修改和删除等一类的操作,其效率会非常的低,因为隔着很多层镜像。
而要想绕过这种限制,我们可以通过使用存储卷的机制来实现。
2.什么是存储卷
存储卷就是将宿主机的本地文件系统中存在的某个目录直接与容器内部的文件系统上的某一目录建立绑定关系。这就意味着,当我们在容器中的这个目录下写入数据时,容器会将其内容直接写入到宿主机上与此容器建立了绑定关系的目录。
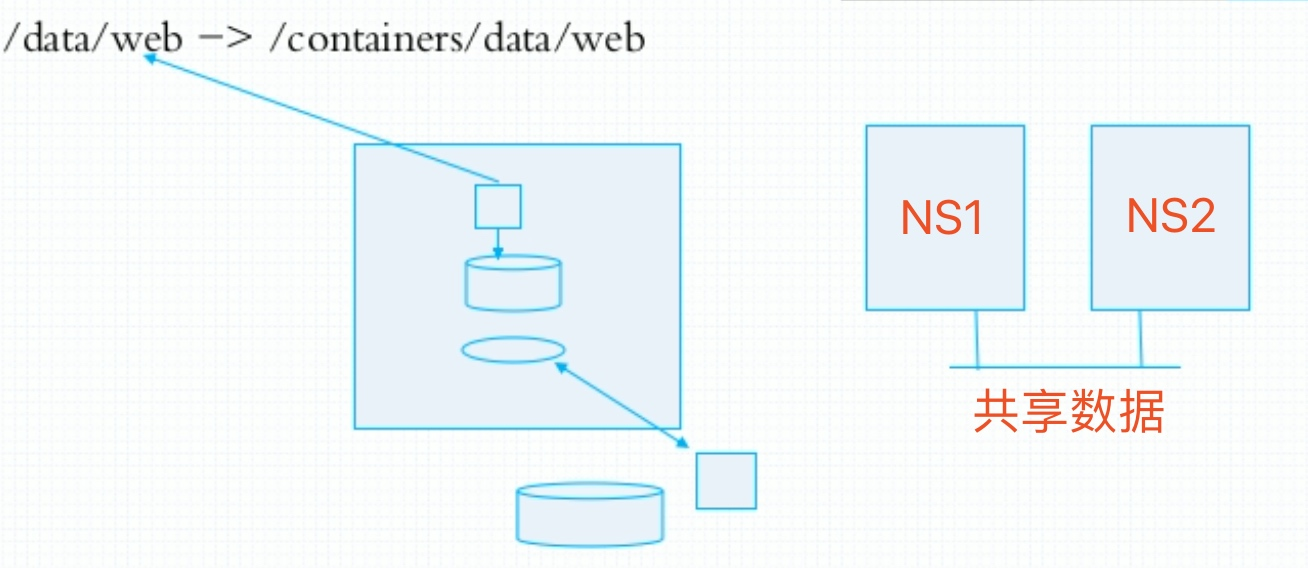
在宿主机上的这个与容器形成绑定关系的目录被称作存储卷。
3.使用存储卷的好处
如果容器中跑的进程的所有有效数据都保存在存储卷中,从而脱离容器自身文件系统之后,带来的好处是当容器关闭甚至被删除时,只要不删除与此容器绑定的在宿主机上的这个存储目录,我们就不用担心数据丢失了。因此就可以实现数据持久,脱离容器的生命周期而持久。
我们通过这种方式管理容器,容器就可以脱离主机的限制,可以在任意一台部署了docker的主机上跑容器,而其数据则可以置于一个共享存储文件系统上,比如nfs。
Docker的存储卷默认情况下是使用其所在的宿主机上的本地文件系统目录的,也就是说宿主机上有一块属于自己的硬盘,这个硬盘并没有共享给其他的Docker主机,而在这台主机上启动的容器所使用的存储卷是关联到此宿主机硬盘上的某个目录之上。
这就意味着容器在这台主机上停止运行或者被删除了再重建,只要关联到硬盘上的这个目录下,那么其数据还存在。但如果在另一台主机上启动一个新容器,那么数据就没了。而如果在创建容器的时候我们手动的将容器的数据挂载到一台nfs服务器上,那么这个问题就不再是问题了。
4.为什么要用存储卷
关闭并重启容器,其数据不受影响,但删除Docker容器,则其更改将会全部丢失。
因此Docker存在的问题有:
- 存储于联合挂载文件系统中,不易于宿主机访问
- 容器间数据共享不便
- 删除容器其数据会丢失
而要解决这些问题,解决方案就是使用存储卷。
5.存储卷管理方式
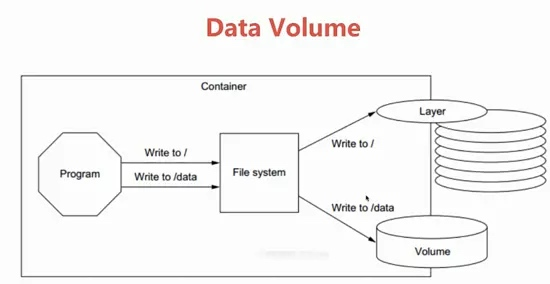
存储卷(Data Volume)于容器初始化时被自动创建,由base image提供的卷中的数据会于此期间完成复制。
Volume的初衷是独立于容器的生命周期实现数据持久化,因此删除容器之时既不会删除卷,也不会对未被引用的卷做垃圾回收操作。
存储卷为Docker提供了独立于容器的数据管理机制,我们可以把镜像想象成静态文件,例如“程序”,把卷类比为动态内容,例如“数据”。所以镜像可以重用,而卷则可以共享。
卷实现了“程序(镜像)”和“数据(卷)”的分离,以及“程序(镜像)”和“制作镜像的主机”的分离,用户制作镜像时无须再考虑镜像运行的容器所在的主机的环境。
6.存储卷的分类
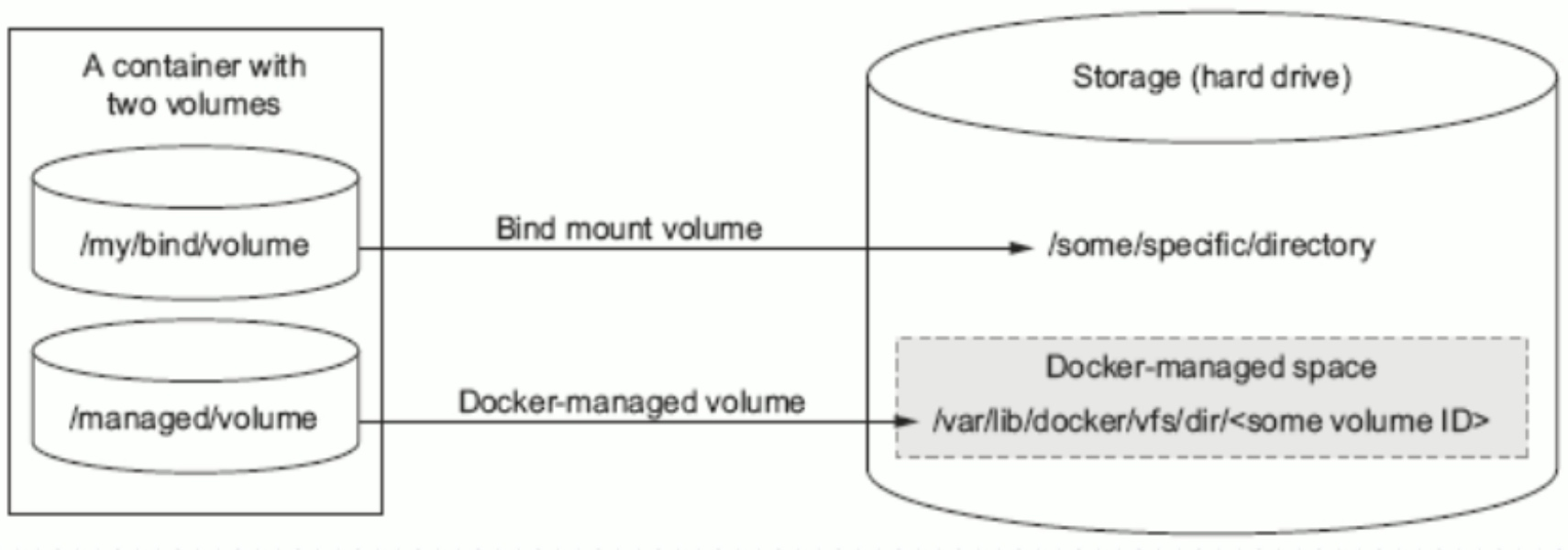
Docker有两种类型的卷,每种类型都在容器中存在一个挂载点,但其在宿主机上的位置有所不同:
- Bind mount volume
- a volume that points to a user-specified location on the host file system
- Docker-managed volume
- the Docker daemon creates managed volumes in a portion of the host's file system that's owned bye Docker
- the Docker daemon creates managed volumes in a portion of the host's file system that's owned bye Docker
7.容器数据管理
用户在使用Docker的过程中,往往需要能查看容器内应用产生的数据,或者需要把容器内的数据进行备份,甚至多个容器之间进行数据的共享,这必然涉及容器的数据管理操作。
容器中管理数据主要有两种方式:
- 数据卷(Data Volumes)
- 数据卷容器(Data Volumes Containers)
容器Volume使用语法:
- Docker-managed volume
docker run -it --name CONTAINER_NAME -v VOLUMEDIR IMAGE_NAME
- Bind mount volume
docker run -it --name CONTAINER_NAME -v HOSTDIR:VOLUMEDIR IMAGE_NAME
7.1在容器中使用数据卷
在容器内创建一个数据卷
下面使用nginx镜像创建一个web容器,并创建一个数据卷挂载到容器的/webapp目录下:
[root@192 ~]# docker run -d -P --name web -v /webapp nginx
这里的-P是允许外部访问容器需要暴露的端口。
挂载一个主机目录作为数据卷
[root@192 ~]# docker run -d -P --name web1 -v /var/www/html:/webapp nginx
上面的命令加载主机的/var/www/html目录到容器的/webapp目录:
这个功能在进行测试的时候非常方便,比如用户可以放置一些程序或数据到本地目录中,然后在容器内运行和使用。另外,本地目录的路径必须是绝对路径,如果目录不存在,Docker会自动创建。
Docker挂载数据卷的默认权限是读写(rw),用户也可以通过(ro)指定为只读:
[root@192 ~]# docker run -d -P --name web2 -v /var/www/html:/webapp:ro nginx
加了:ro以后,容器内挂载的数据卷的数据就无法修改了。
挂载一个本地主机文件作为数据卷
-v选项也可以从主机挂载单个文件到容器中作为数据卷:
[root@192 ~]# docker run -it --rm -v ~/.bash_history:/.bash_history centos /bin/bash
这样就可以记录在容器输入过的命令历史了。
如果直接挂载一个文件到容器,使用文件编辑工具,包括vi或者sed去修改文件内容的时候,可能会造成inode的改变,这样将会导致错误。所以推荐的方式是直接挂载文件所在的目录。
7.2数据卷容器
如果用户需要在容器之间共享一些持续更新的数据,最简单的方式是使用数据卷容器。数据卷容器其实就是一个普通的容器,专门用它提供数据卷供其他容器挂载使用,方法如下:
首先,创建一个数据卷容器dbdata,并在其中创建一个数据卷挂载到/dbdata:
[root@192 ~]# docker run -it -d --name dbdata -v /dbdata centos
然后可以在其他容器中使用--volumes-from来挂载dbdata容器中的数据卷,例如创建db1和db2两个容器,并从dbdata容器挂载数据卷:
[root@192 ~]# docker run -it --name db1 --volumes-from dbdata centos /bin/bash
[root@192 ~]# docker run -it --name db2 --volumes-from dbdata centos /bin/bash
此时,容器db1和db2都挂载同一个数据卷到相同的/dbdata目录。三个容器任何一方在该目录下的写入,其他容器都可以看到。
例如,在db1容器中创建一个test文件:
[root@192 ~]# docker run -it --name db1 --volumes-from dbdata centos /bin/bash
[root@1023ffbd55bc /]# ls
bin dev home lib64 media opt root sbin sys usr
dbdata etc lib lost+found mnt proc run srv tmp var
[root@1023ffbd55bc /]# cd dbdata/
[root@1023ffbd55bc dbdata]# touch test
[root@1023ffbd55bc dbdata]# ls
test
在db2容器中查看:
[root@192 ~]# docker run -it --name db2 --volumes-from dbdata centos /bin/bash
[root@12f2b478eee3 /]# ls
bin dev home lib64 media opt root sbin sys usr
dbdata etc lib lost+found mnt proc run srv tmp var
[root@12f2b478eee3 /]# ls dbdata/
test
可以多次使用--volumes-from参数来从多个容器挂载多个数据卷。还可以从其他已挂载了容器卷的容器来挂载数据卷:
[root@192 ~]# docker run -it --name db3 --volumes-from db1 centos /bin/bash
[root@0fb9832c53f5 /]# ls
bin dev home lib64 media opt root sbin sys usr
dbdata etc lib lost+found mnt proc run srv tmp var
[root@0fb9832c53f5 /]# ls dbdata/
test
使用--volumes-from参数所挂载数据卷的容器自身并不需要保持在运行状态。
如果删除了挂载的容器(包括dbdata、db1和db2),数据卷并不会被自动删除。如果要删除一个数据卷,必须在删除最后一个还挂载着它的容器时显式使用docker rm -v命令来指定同时删除关联的容器。
7.3利用数据卷容器迁移数据
可以利用数据卷容器对其中的数据卷进行备份、恢复,以实现数据的迁移。
备份恢复
如果要恢复数据到一个容器,可以按照下面的操作。首先创建一个带有数据卷的容器dbdata2
使用下面的命令来备份dbdata数据卷容器内的数据卷:
[root@192 ~]# docker run --name worker --volumes-from dbdata -v $(pwd):/backup centos tar cvf /backup/backup.tar /dbdata
tar: Removing leading `/' from member names
/dbdata/
/dbdata/test
[root@192 ~]# ls
anaconda-ks.cfg backup.tar
这个命令稍微有点复杂,具体分析下。
首先利用centos镜像创建了一个容器worker。使用--volumes-from dbdata参数来让worker容器挂载dbdata容器的数据卷(即dbdata数据卷);使用-v $(pwd):/backup参数来挂载本地的当前目录到worker容器的/backup目录。
worker容器启动后,使用了tar cvf /backup/backup.tar /dbdata命令来将/dbdata下内容备份为容器内的/backup/backup.tar,即宿主主机当前目录下的backup.tar。
恢复
如果要恢复数据到一个容器,可以按照下面的操作。首先创建一个带有数据卷的容器dbdata2:
[root@192 ~]# docker run -d --name dbdata2 -v /dbdata centos
然后创建另一个新的容器,挂载dbdata2容器,并使用untar解压备份文件到所挂载的容器卷中即可:
[root@192 ~]# docker run --volumes-from dbdata2 -v $(pwd):/backup busybox tar xvf /backup/backup.tar
dbdata/
dbdata/test