输入
输出
样例输入 Copy
5 8
0 1 1
0 2 2
0 3 5
0 4 7
1 2 0
2 3 15
2 4 25
1 4 100
样例输出 Copy
13
提示

对于30%的数据,m≤10;
对于50%的数据,m≤1000;
对于100%的数据,m≤100000,c≤2000。
Kruskal(克鲁斯卡尔)算法开始时,认为每一个点都是孤立的,分属于n个独立的集合。
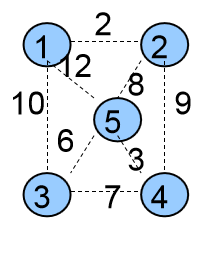
5个集合{ {1},{2},{3},{4},{5} }
生成树中没有边
Kruskal每次都选择一条最小的边,而且这条边的两个顶点分属于两个不同的集合。将选取的这条边加入最小生成树,并且合并集合。
第一次选择的是<1,2>这条边,将这条边加入到生成树中,并且将它的两个顶点1、2合并成一个集合。
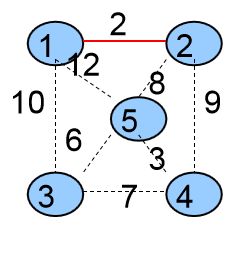
4个集合{ {1,2},{3},{4},{5} }
生成树中有一条边{ <1,2> }
第二次选择的是<4,5>这条边,将这条边加入到生成树中,并且将它的两个顶点4、5合并成一个集合。
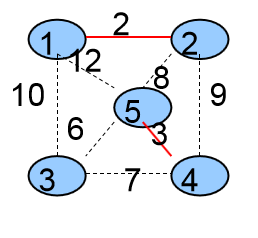
3个集合{ {1,2},{3},{4,5} }
生成树中有2条边{ <1,2> ,<4,5>}
第三次选择的是<3,5>这条边,将这条边加入到生成树中,并且将它的两个顶点3、5所在的两个集合合并成一个集合
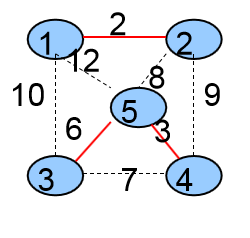
2个集合{ {1,2},{3,4,5} }
生成树中有3条边{ <1,2> ,<4,5>,<3,5>}
第四次选择的是<2,5>这条边,将这条边加入到生成树中,并且将它的两个顶点2、5所在的两个集合合并成一个集合。
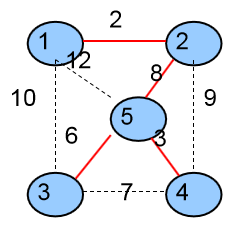
1个集合{ {1,2,3,4,5} }
生成树中有4条边{ <1,2> ,<4,5>,<3,5>,<2,5>}
算法结束,最小生成树权值为19。
通过上面的模拟能够看到,Kruskal算法每次都选择一条最小的,且能合并两个不同集合的边,一张n个点的图总共选取n-1次边。因为每次我们选的都是最小的边,所以最后的生成树一定是最小生成树。每次我们选的边都能够合并两个集合,最后n个点一定会合并成一个集合。通过这样的贪心策略,Kruskal算法就能得到一棵有n-1条边,连接着n个点的最小生成树。
Kruskal算法的时间复杂度为O(E*logE),E为边数。
int Find(int x) 并差集 压缩路径 {if(fa[x]==x) return x;fa[x]=Find(fa[x]);} FORa(i,1,n) fa[i]=i; 初始化,将父亲指向自己 sort(edge+1,edge+1+n,cmp);排序 FORa(i,1,m) { t1=Find(edge[i].from);t2=Find(edge[i].to); if(t1!=t2) 并差集合并 cnt++,fa[t1]=t2,ans+=edge[i].dis; if(cnt==n-1) cout<<ans;return;
本题代码:
#include<bits/stdc++.h> using namespace std; typedef long long ll; inline int read() { int x=0;char ch=getchar(); while(ch<'0'||ch>'9')ch=getchar(); while(ch>='0'&&ch<='9'){x=x*10+ch-'0';ch=getchar();} return x; } const int maxn=1e6+100; int pre[maxn],n,m; struct node{ ll u,v,w; }a[maxn]; bool cmp(node x,node y){ return x.w<y.w; } void inint(){ for(int i=0;i<=n;i++){ pre[i]=i; } } int find(int h)//找根? { return pre[h]==h?h:pre[h]=find(pre[h]); } int merge(node n){ int x=find(n.u); int y=find(n.v); if(x!=y){ pre[x]=y; return 1; } return 0; } int main(){ cin>>n>>m; inint(); for(int i=1;i<=m;i++){ a[i].u=read(); a[i].v=read(); a[i].w=read(); } sort(a+1,a+m+1,cmp); ll num=0,ans=0; for(int i=1;i<=m&&num<=n-1;i++) { if(merge(a[i])==1) { num++; ans+=a[i].w; } } printf("%lld ",ans); }
克鲁斯卡尔
- 并查集加排序
- 预处理,现将所有的节点的父亲指向自己
- 输入m条边,切记,只需要m条边
- 按每一条边的权值排序
- 最后并查集来查询,看是否加入到生成树中,注意并查集模板是这样写的
int Find(int x){if(fa[x]==x) return fa[x]; return fa[x]=Find(fa[x]);
- 最后查看是否是构造了一颗n个点,n-1条边的最小生成树
普里姆
- 对于构造边,就使用链式前向星,但是对于边的话就需要开两倍
- 初始化,将dis[](这个点到最小生成树的最近的距离)赋值为一个极大的值,但是不能超过INF的二分之一,即为memset(dis,63,sizeof (dis))为一个较大的值,memset赋值的时候需要赋值为2的x次方-1
- 再用一个pair来储存队列节点的信息,宏定义 #define pair<int,int> pp
- 放入优先队列priority_queue<pp,vector<pp>,greater<pp> > q; 小根堆,默认为大根堆
- 两个连着的尖括号之间需要打空格
- Pair的比较,先比较first,在比较second,所以将dis存入first,u存入second
- 最外层循环为队列不为空且最小生成树还没有构建好while(!q.empty()&&cnt<n)
- 接着,退出队列中的对头,查看是否出现过,没有出现过就将此点打标记,cnt++,答案加上这条边的权值,扩散连接它的边,放入队列
普里姆的算法就是最短路的贪心思想
#include<cstdio> #include<queue> #include<cstring> #include<utility> #include<algorithm> #define FORa(i,s,e) for(i=s;i<=e;i++) #define R register int using namespace std; int n,m,cnt,ans,head[5005],dis[5005],bz[5005]; struct Edge { int next,to,dis; }edge[400005]; int num_edge; void Add_edge(int from,int to,int dis) { edge[++num_edge]=(Edge){head[from],to,dis}; head[from]=num_edge; } typedef pair <int,int> pp; priority_queue <pp,vector<pp>,greater<pp>> q;//first dis second u void Prim() { pp ft; dis[1]=0; q.push(make_pair(0,1)); while(!q.empty()&&cnt<n) { ft=q.top(),q.pop(); if(bz[ft.second]) continue; cnt++,ans+=ft.first,bz[ft.second]=1; for(R i=head[ft.second];i;i=edge[i].next) if(dis[edge[i].to]>edge[i].dis) dis[edge[i].to]=edge[i].dis,q.push(make_pair(dis[edge[i].to],edge[i].to)); } } int main() { memset(dis,127,sizeof(dis)); R from,to,fdis; scanf("%d%d",&n,&m); for(R i=1;i<=m;i++) { scanf("%d%d%d",&from,&to,&fdis); Add_edge(to,from,fdis),Add_edge(from,to,fdis); } Prim(); if (cnt==n)printf("%d",ans); else printf("orz"); }