一、引言
一直搞不明白Oracle数据库的客户端是怎么回事,怎么配置,前几天由于工作中需要用到Oracle,而且需要连接两个不同的数据库,就通过上网和请教同事终于把客户端的配置搞定了,记录之,学习之
二、步骤
其实对于软件的配置,如果重启软件后,这个配置还生效的话,那么它就一定把这个配置写入了某个文件中,只不过有些软件会对这些文件加密或者以二进制写入,所以我们看不到,但是所幸Oracle的文件时可以看到并且可以编辑的。下面就看一下两种方式配置客户端登陆多个远程数据库。
方法一、修复配置文件
这种方法简单直接,但是有个前提条件:你得知道这个文件在哪,然后直接添加需要的配置项就可以了,而且你还得知道如何添加是正确的。
文件位置:homedirproduct11.1.0client_1 etworkadmin nsnames.ora
其中homedir是指安装客户端端的目录,如果不知道在哪,在window中可以在所有程序找到客户端中的一个程序然后右键打开文件位置即可。
配置项格式:如果你的客户端已经添加了一个远程数据库,那么文件已经有一个配置好的了,你只要按照它的格式修改一下就可以了。
下面是我的配置文件,其中有一个配置好的了,所以已经有一个配置项了,按照修改就可以了。

这张图是我用第二种方式添加的第二远程数据库后,该配置文件的内容
可以看到,新添加的配置项与原来的仅有一处差别,就是IP地址。
方法二、
与方法一不同,此方法是使用Oracle提供的工具来配置的--Net Configuration Assistant
可以在所有程序中找到它:

Oracle的这个工具已经做的很人性化了,但是如果你是第一次接触它,那么你可能依然不知道怎么使用它,因为里面的一些术语你不懂是什么意思。下面我就一步一图来告诉你如何配置。
步骤一、打开Net Configuration Assitant这个工具,选择本地服务名配置

步骤二、选择添加

步骤三、填写服务名,此处是远程数据库的服务名

步骤四、选择通信协议--TCP

步骤五、填写主机名及端口号--远程数据库服务器的IP地址及端口号

步骤六、是否进行测试?此处选择进行测试即测试是否连接成功

步骤七、如果连接未成功,可以修改登陆,因为默认是用system用户登陆的
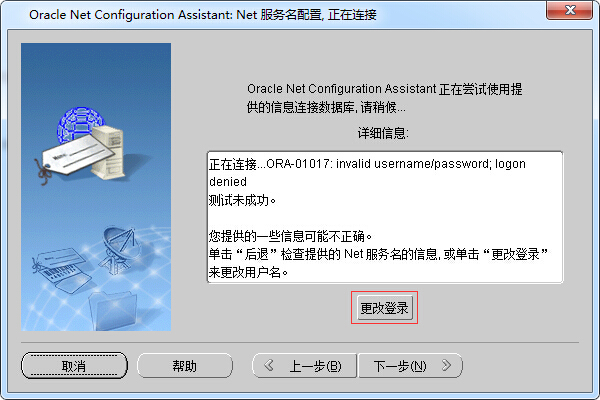
步骤八、测试连接成功

步骤九、为此服务输入名称即填写标识该服务的标示符(我们在使用plsql登陆时使用),因为我已经又一个orcl了,所以我在此处写的是orcl21

步骤十、是否配置另一个Net服务名,此处选否,如果你要继续配置,那么选是。
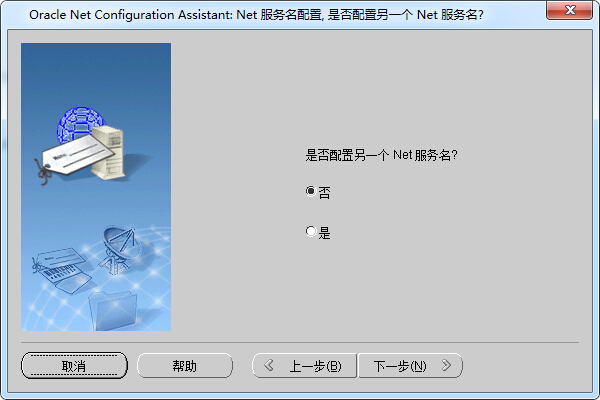
步骤十一、到此我们的配置已经基本完成了,此处点击下一步
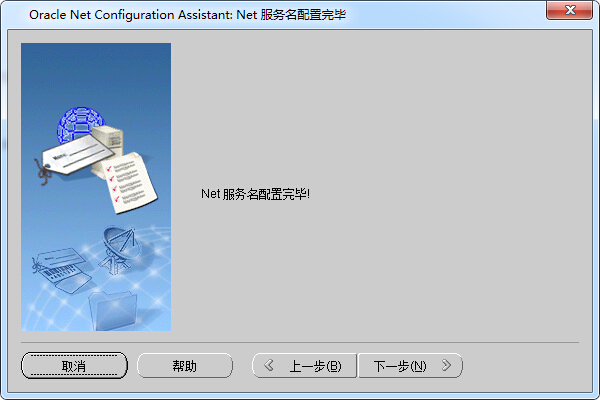
步骤十二、到这一步,我们已经彻底完成了配置,点击完成退出Net Configuration Assistant

完成配置后,我们可以登录一下试试,配置是否可用。

我们使用splsql登录,此处需要在Database处选择刚才添加的配置项,它的名称是前面配置的:orcl21
到此处我们已经完成Oracle客户端登陆多个数据库的配置,我们回头看看经过配置后的那个文件现在是什么样了:

在文件中添加了一个配置项,配置项中的参数跟我们填写的一模一样。所以这也印证了第一种方法的可行性。
三、总结
关于Oracle配置中的一些术语,此博客写的很全面可以参考一下。
通过这次配置,发现,客户端是不需要监听程序配置的。那是数据库安装的服务器才需要的,以前配置的时候不懂,就连这个也配置了T_T。
任何软件都离不开IO,要想永久保存的数据,只有写入文件中才行。
就像这些数据库一样,不管它们怎么对它的数据进行组织,归根结底都还是在读写文件,它们对数据进行组织无非是想要提高读取数据的速度,或者是把数据组织成更加复杂的结构,以便直接使用。但是最后还是读写文件,只不过写入的格式是根据自家数据库的设计进行制定的。
貌似总结跟上面的内容无关T_T,哈哈,突然想到了就写上去了。