在学习python以及在使用python进行项目开发的过程中,经常会使用print语句打印一些调试信息,这些调试信息中往往会包含中文,如果你使用python版本是python2.7,或许你也会遇到和我一样的问题:那就是print打印中文异常以及显示乱码问题。本文主要分析一下在linux下使用python2.7的print语句中文异常以及终端显示中文乱码问题的原因及解决办法。转载请注明出处,谢谢!
1.print打印显示的过程
![]()
图1. Print打印显示过程
Python2.7中调用print打印var 变量时,操作系统会对var做一定的字符处理:如果var是str类型的变量,则直接将var变量交付给终端进行显示;如果var变量是unicode类型,则操作系统首先将var编码成str类型的对象(编码格式取决于stdout的编码格式),然后再交由终端进行显示。在终端显示时,如果str类型的变量的编码方式和终端设置的编码方式不一致,很可能会出现乱码问题。
2.print中文字符出现错误问题
在python源码中print中文字符,时常会出现Non-ASCII character和UnicodeEncodeError两类错误。下面分别一一介绍。
2.1 Non-ASCII character错误
print.py源码示例(代码1):
import sys
print sys.getdefaultencoding()
a="测试"
b=u"测试"
print a
print b
这段代码试图在linux的终端打印变量a和b的值,但是在实际执行的过程中,会提示Non-ASCII character错误:

原因:该print.py的文件格式是utf-8(可以vi print.py,然后在命令模式下,输入:set fileencoding,查看文件的编码方式,)。“测试”对应的utf-8编码为:'xe6xb5x8bxe8xafx95',由于print.py中含有中文,且print.py没有指定编码方式,python会按照系统的默认编码解析执行print.py(这里的系统默认编码是ascii,查看系统的默认编码,可以调用sys.getdefaultencoing()函数),因此会提示Non-ASCII character的错误。
解决办法:在print.py起始处,指定编码方式为utf-8,这样python在执行代码时,就知道要按照utf-8来解释执行代码了。代码2:
#coding=utf-8
import sys
print sys.getdefaultencoding()
a="测试"
b=u"测试"
print a
print b
运行结果如下:

2.2 UnicodeEncodeError问题
代码2在192.168.86.61上能正常运行,但是换到另一台机器192.168.86.157就不能正常运行了,现象如下:

从打印信息来看,print a可以正常输出,而print b就会出现UnicodeEncodeError错误,这是为什么呢??
根据第1节中的介绍,变量b是unicode类型的,操作系统会按照stdout的默认编码将b编码成str类型的变量,根据报错信息猜测系统stdout的默认编码是ascii,而ascii字符的范围是0-127,因此会报上述错误。而变量a是str类型,调用print时,不需要经过操作系统进行编码,所以能正常输出。
那么,如何验证157上的系统stdout的编码方式是不是ascii呢?可以通过sys.stdout.encoding查看stdout的编码方式,这里的输出结果是ANSI_X3.4-1968,其别名就是ASCII,哈哈,原来真的是这样。
那么,为什么在192.168.86.61上,print b就能正常被打印输出呢?想要知道原因,让我们查看一下192.168.86.61上的stdout的编码方式,通过sys.stdout.encoding查得stdout的编码方式为utf-8,unicode类型的变量b的print时,首先被编码成utf-8,然后在送至终端显示,一切正常!
至此,你可能明白了该问题产生的原因,那么,这个问题该怎么解决呢?一般建议在调用print打印变量时,首先调用encode()函数将unicode类型的变量进行编码,转换成str类型的变量,代码3如下:
#coding=utf-8
import sys
print sys.getdefaultencoding()
a="测试"
b=u"测试"
print a
print b.encode('utf-8')
之后,程序可以正常运行,如下:
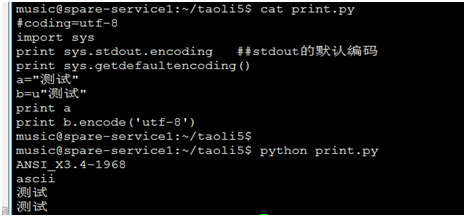
3.linux终端显示中文乱码
第1节中曾提到过:如果str类型的变量的编码方式和终端设置的编码方式不一致,在终端显示时就会出现中文乱码问题。笔者使用的终端的编码方式为utf-8,如下图:
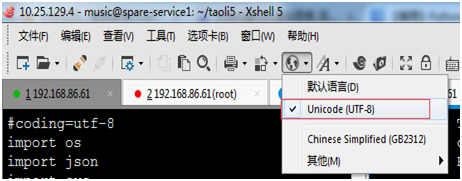
如果将终端的编码方式改为GB2312,则中文就会出现乱码。因为b.encode('utf-8')的编码为utf-8,而终端的为GB2312,因此导致了乱码。
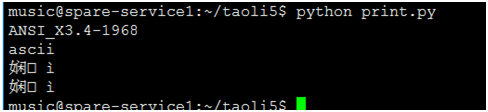
解决方法就是要保持终端编码和待显示的变量的编码方式的一致。