ajax爬取情况
有时候我们在用 Requests 抓取页面的时候,得到的结果可能和在浏览器中看到的是不一样的,在浏览器中可以看到正常显示的页面数据,但是使用 Requests 得到的结果并没有,这其中的原因是 Requests 获取的都是原始的 HTML 文档,而浏览器中的页面则是页面又经过 JavaScript 处理数据后生成的结果,这些数据的来源有多种,可能是通过 Ajax 加载的,可能是包含在了 HTML 文档中的,也可能是经过 JavaScript 经过特定算法计算后生成的
项目代码如下
1 import requests 2 from fake_useragent import UserAgent 3 from pyquery import PyQuery 4 from urllib.parse import urlencode 5 from requests.packages import urllib3 6 from pymongo import MongoClient 7 8 # 关闭警告 9 urllib3.disable_warnings() 10 11 base_url = 'https://m.weibo.cn/api/container/getIndex?' 12 13 # 激活本地MongoDB客户端 14 client = MongoClient('localhost',27001) 15 # 创建数据库 16 pages = client['pages'] 17 # 创建集合 18 ma_yun = pages['ma_yun'] 19 20 # 保存到mongoDB中 21 def save_to_mongo(result): 22 if ma_yun.insert_one(result): 23 print('saved to Mongo','已获取{number}条数据'.format(number=ma_yun.count())) 24 25 # 生成UA 26 def create_user_agent(): 27 ua = UserAgent(use_cache_server=False) 28 # print(ua.chrome) 29 return ua.chrome 30 31 # 生成headers 32 def create_headers(): 33 headers = { 34 'User-Agent': create_user_agent() 35 } 36 return headers 37 38 # 获取页面 39 def get_page(page): 40 # 设置参数 41 params = { 42 'sudaref':'germey.gitbooks.io', 43 'display':'0', 44 'retcode':'6102', 45 'type':'uid', 46 'value':'2145291155', 47 'containerid':'1076032145291155', 48 'page':page 49 } 50 url = base_url + urlencode(params) 51 try: 52 response = requests.get(url,create_headers(),verify=False) 53 if response.status_code == 200: 54 return response.json() 55 except requests.ConnectionError as e: 56 print('Error',e.args) 57 58 # 解析页面 59 def parse_page(json): 60 if json: 61 items = json.get('data').get('cards') 62 if items != None: 63 for item in items: 64 item = item.get('mblog') 65 weibo = {} 66 weibo['id'] = item.get('id') 67 # 将正文中的 HTML 标签去除掉 68 weibo['text'] = PyQuery(item.get('text')).text() 69 # 点赞数 70 weibo['attitudes_count'] = item.get('attitudes_count') 71 # 评论数 72 weibo['comments_count'] = item.get('comments_count') 73 # 发布时间 74 weibo['datetime'] = item.get('created_at') 75 # 转发数 76 weibo['reposts_count'] = item.get('reposts_count') 77 78 yield weibo 79 80 # 设置主方法进行调用其他方法 81 def main(): 82 for page in range(1,30): 83 json = get_page(page) 84 results = parse_page(json) 85 for result in results: 86 save_to_mongo(result) 87 88 if __name__ == '__main__': 89 main()
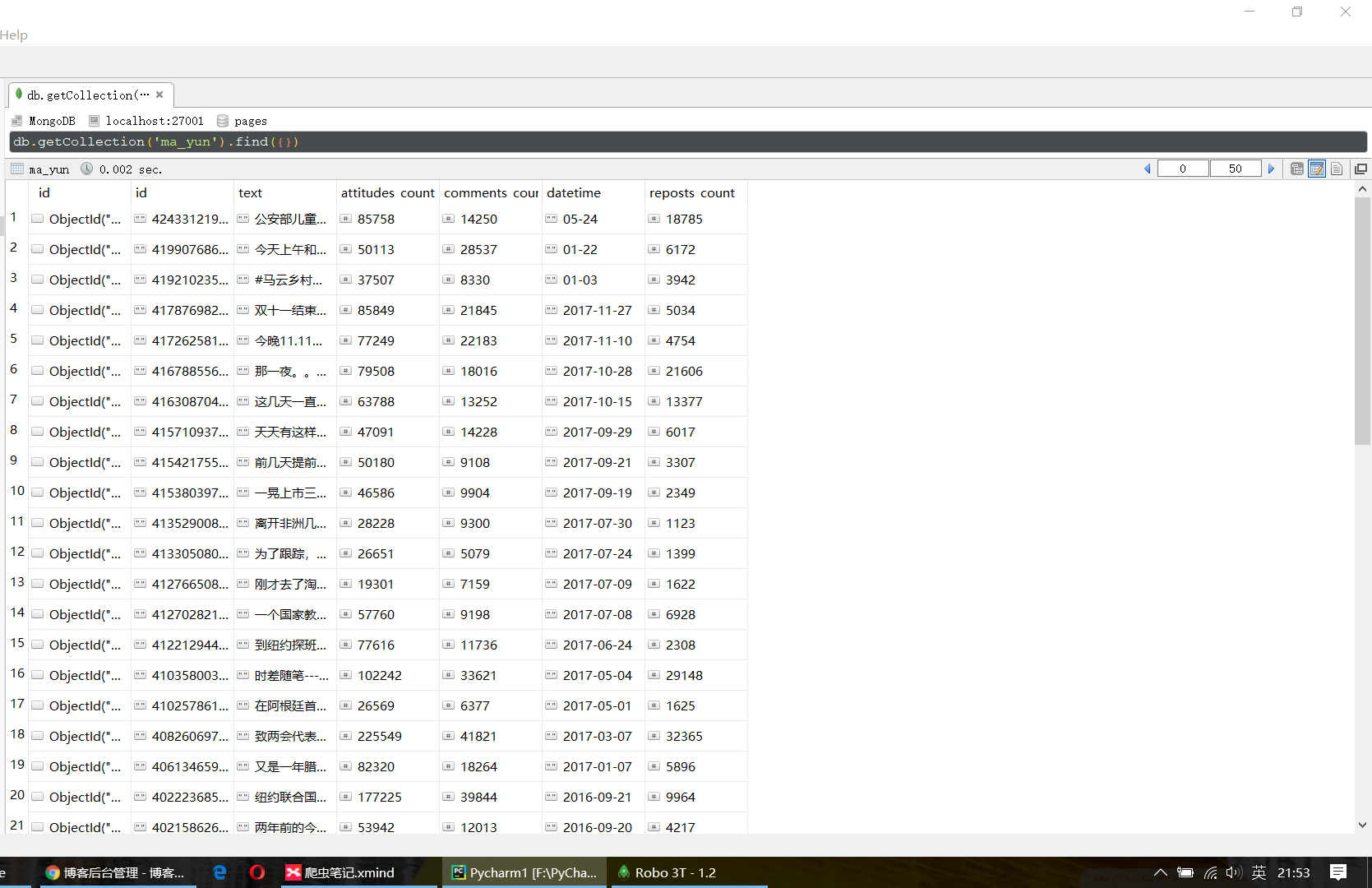
项目运行情况