1.算法工作原理
存在一个训练样本集,我们知道样本集中的每一个数据与所属分类的对应关系,输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应特征进行比较,然后算法提取样本集中特征最相似的数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处。通常k是不大于20的整数。
比如匹配是爱情片,还是动作片,将已知电影和未知电影比较,算出距离


假如k = 3,前三部又是爱情片,所以我们可判定此电影为爱情片。
2.算法流程
1.准备:使用python导入数据。
创建kNN.py模块
这里我们先用自己输入的数据测试。
from numpy import * #科学计算包 import operator #运算符模块 def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) #创建数据集 labels = ['A','A','B','B'] #标签 return group,labels def classify(inX,dataSet,labels,k): dataSetSize = dataSet.shape[0] #求数组的行数 diffarray = tile(inX, (dataSetSize, 1))-dataSet #tile使inx变为和dataSet相同行数的数组 squarediffarray = diffarray**2 # x^2 , y^2 sqDistances = squarediffarray.sum(axis=1) #对每一行向量求和 distances = sqDistances**2 #对每个和开根号 sortedDistIndexes = distances.argsort() #将所有值从小到大排序,取原先的索引 mp = {} for i in range(k): templabel = labels[sortedDistIndexes[i]] mp[templabel] = mp.get(templabel,0)+1 #dict.get(key,default=None),不存在返回0 sortedmp = sorted(mp.items(),key=operator.itemgetter(1),reverse=True) #[('D', 312), ('I', 100), ('C', 4), ('B', 3), ('A', 1)] #将出现次数较多的情况返回 return sortedmp[0][0] def main(): group,labels = createDataSet() var = classify([0.8,1.0],group ,labels , 3) print(var) main()
A
首先讨论的数组和矩阵的区别:
#数组和矩阵的区别 from numpy import * var = array([[1,2],[3,4]]) matr = mat(var) #print(type(var)) print(var**2) print(matr**2) print(var.shape[0]) print(matr.shape[0])
[[ 1 4] [ 9 16]] [[ 7 10] [15 22]] 2 2
数组的平方是对数组中的每个元素平方,矩阵的平方是两个矩阵相乘。
shape[0]可以计算数组和矩阵的行数。
关于tile,戳这
kNN中的应该还是数组
from numpy import * #科学计算包 import operator #运算符模块 b = [1,3,5] var = tile(b, (2, 3)) print(type(var))
<class 'numpy.ndarray'>
关于argsort,戳这
python 3.6下,将iteritems换成了items.
sort排序
from numpy import * #科学计算包 import operator #运算符模块 mp = {} mp['A'] = mp.get('A',1) mp['B'] = mp.get('B',3) mp['C'] = mp.get('C',4) mp['D'] = mp.get('D',312) mp['I'] = mp.get('I',100) so = sorted(mp.items(),key=operator.itemgetter(1),reverse=False) print(so)
[('A', 1), ('B', 3), ('C', 4), ('I', 100), ('D', 312)]
items()将dict分解为元组列表.
示例:使用kNN算法改进约会网站
使用Matplotlit创建散点图
此时代码
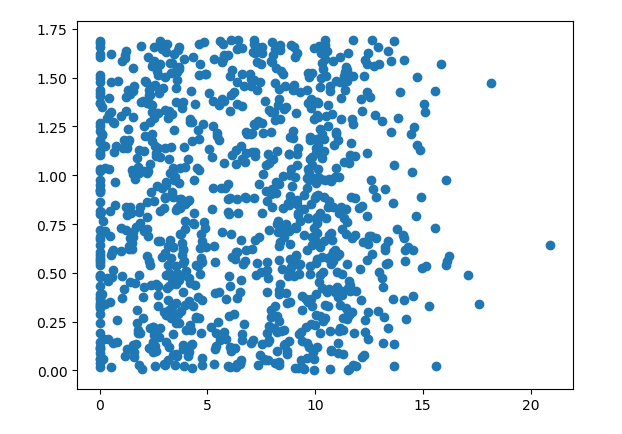
#该函数的输入为文本名字符串,输出位训练样本矩阵和类标记向量 def filearray(filename): fr = open(filename) #a = array([1,2,3,4,5]) arrayOLines = fr.readlines() #print(arrayOLines) #numberOfLines = len(a) numberOfLines = len(arrayOLines) #print(numberOfLines) #print(type(zeros((numberOfLines,3)))) returnarray = zeros((numberOfLines,3)) labels = [] index = 0 for line in arrayOLines: line = line.strip() #去掉回车 #print(line) listFromLine = line.split(' ') #print(listFromLine) #变成列表 returnarray[index,:] = listFromLine[0:3] labels.append(int((listFromLine[-1]))) #应用数据错误 index += 1 return returnarray,labels def main(): # group,labels = createDataSet() # var = classify([0.8,1.0],group ,labels , 3) # print(var) #datingDataArray,datinglabels = filearray('d3.txt') datingDataArray,datinglabels = filearray('datingTestSet2.txt') fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(datingDataArray[:,1],datingDataArray[:,2]) #第1列和第2列 plt.show() #print(datingDataArray) #print(datinglabels) main()
对应散点图
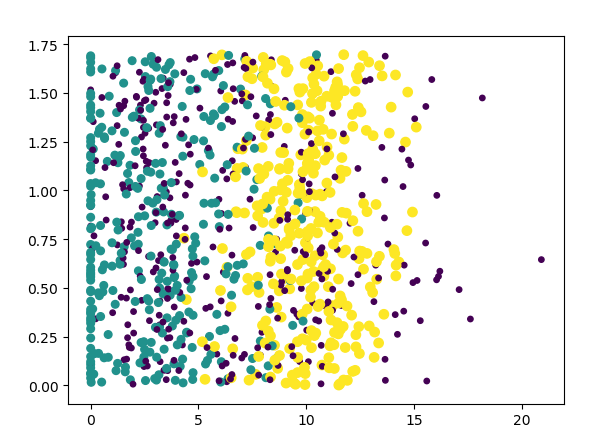
绘制不同色彩,三类人
ax.scatter(datingDataArray[:,1],datingDataArray[:,2], 15.0*array(datinglabels),15.0*array(datinglabels)) #第1列和第2列
对后面还15.0乘还不太理解
使用第一列和第二列更容易得出结论。
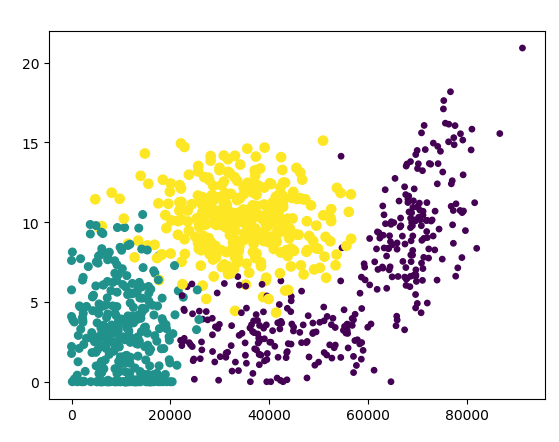
#数值归一化 #(oldValue - minVal)/(maxVal-minVal) def autoNorm(dataSet): minVals = dataSet.min(0) #获取每一列的最小值和最大值 maxVals = dataSet.max(0) # print(minVals) # print(maxVals) ranges = maxVals-minVals #print(shape(dataSet)) (9, 3) normDataSet = zeros(shape(dataSet)) #shape()返回矩阵规模 m = dataSet.shape[0] normDataSet = dataSet - tile(minVals, (m, 1)) normDataSet = normDataSet/tile(ranges, (m, 1)) #print(normDataSet) return normDataSet,ranges,minVals #计算错误率 def datingCalcError(): Radio = 0.1 datingDataArray,datinglabels = filearray('datingTestSet2.txt') normArray,ranges,minVals = autoNorm(datingDataArray) m = normArray.shape[0] numOfTestData = int(m*Radio) #10% errorNumber = 0.0 #浮点数 for i in range(numOfTestData): #90% classifierResult = classify(normArray[i,:],normArray[numOfTestData:m,:], datinglabels[numOfTestData:m],3) print("the test result:%d, the real result:%d"%(classifierResult,datinglabels[i])) if(classifierResult!=datinglabels[i]): errorNumber += 1.0 print("the error rate is %f"%(errorNumber/(float(numOfTestData)))) # main() datingCalcError()
约会网站预测


from numpy import * #科学计算包 import operator #运算符模块 import matplotlib import matplotlib.pyplot as plt def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) #创建数据集 labels = ['A','A','B','B'] #标签 return group,labels def classify(inX,dataSet,labels,k): dataSetSize = dataSet.shape[0] #求数组的行数 diffarray = tile(inX, (dataSetSize, 1))-dataSet #tile使inx变为和dataSet相同行数的数组 squarediffarray = diffarray**2 # x^2 , y^2 sqDistances = squarediffarray.sum(axis=1) #对每一行向量求和 distances = sqDistances**2 #对每个和开根号 sortedDistIndexes = distances.argsort() #将所有值从小到大排序,取原先的索引 mp = {} for i in range(k): templabel = labels[sortedDistIndexes[i]] mp[templabel] = mp.get(templabel,0)+1 #dict.get(key,default=None),不存在返回0 sortedmp = sorted(mp.items(),key=operator.itemgetter(1),reverse=True) #[('D', 312), ('I', 100), ('C', 4), ('B', 3), ('A', 1)] #将出现次数较多的情况返回 return sortedmp[0][0] #该函数的输入为文本名字符串,输出位训练样本矩阵和类标记向量 def filearray(filename): fr = open(filename) #a = array([1,2,3,4,5]) arrayOLines = fr.readlines() #print(arrayOLines) #numberOfLines = len(a) numberOfLines = len(arrayOLines) #print(numberOfLines) #print(type(zeros((numberOfLines,3)))) returnarray = zeros((numberOfLines,3)) labels = [] index = 0 for line in arrayOLines: line = line.strip() #去掉回车 #print(line) listFromLine = line.split(' ') #print(listFromLine) #变成列表 returnarray[index,:] = listFromLine[0:3] labels.append(int((listFromLine[-1]))) #应用数据错误 index += 1 return returnarray,labels def main(): # group,labels = createDataSet() # var = classify([0.8,1.0],group ,labels , 3) # print(var) datingDataArray,datinglabels = filearray('d3.txt') #datingDataArray,datinglabels = filearray('datingTestSet2.txt') # fig = plt.figure() # ax = fig.add_subplot(111) # ax.scatter(datingDataArray[:,0],datingDataArray[:,1 # ], # 15.0*array(datinglabels),15.0*array(datinglabels)) #第1列和第2列 # plt.show() #print(datingDataArray) #print(datinglabels) autoNorm(datingDataArray) #数值归一化 #(oldValue - minVal)/(maxVal-minVal) def autoNorm(dataSet): minVals = dataSet.min(0) #获取每一列的最小值和最大值 maxVals = dataSet.max(0) # print(minVals) # print(maxVals) ranges = maxVals-minVals #print(shape(dataSet)) (9, 3) normDataSet = zeros(shape(dataSet)) #shape()返回矩阵规模 m = dataSet.shape[0] normDataSet = dataSet - tile(minVals, (m, 1)) normDataSet = normDataSet/tile(ranges, (m, 1)) #print(normDataSet) return normDataSet,ranges,minVals #计算错误率 def datingCalcError(): Radio = 0.1 datingDataArray,datinglabels = filearray('datingTestSet2.txt') normArray,ranges,minVals = autoNorm(datingDataArray) m = normArray.shape[0] numOfTestData = int(m*Radio) #10% errorNumber = 0.0 #浮点数 for i in range(numOfTestData): #90% classifierResult = classify(normArray[i,:],normArray[numOfTestData:m,:], datinglabels[numOfTestData:m],3) print("the test result:%d, the real result:%d"%(classifierResult,datinglabels[i])) if(classifierResult!=datinglabels[i]): errorNumber += 1.0 print("the error rate is %f"%(errorNumber/(float(numOfTestData)))) #约会网站测试函数 def classifyPerson(): resultList = ['not at all','in small doses','in large doses'] ffMiles = float(input('flier miles')) percentTats = float(input('playing game')) #不再有raw_input函数 iceCream = float(input('ice cream')) datingDataArray,datinglabels = filearray('datingTestSet2.txt') normArray,ranges,minVals = autoNorm(datingDataArray) inArr = array([ffMiles,percentTats,iceCream]) #print(inArr) classifierResult = classify(((inArr - minVals)/ranges),normArray, datinglabels, 3) print(resultList[classifierResult-1]) # main() classifyPerson()
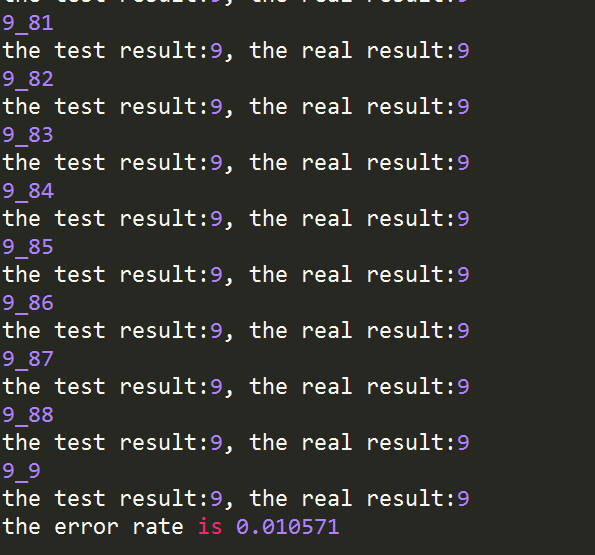
使用kNN算法识别手写数字
from numpy import * #科学计算包 import operator #运算符模块 import matplotlib import matplotlib.pyplot as plt from os import listdir #返回一个目录下文件名的列表 def createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) #创建数据集 labels = ['A','A','B','B'] #标签 return group,labels def classify(inX,dataSet,labels,k): dataSetSize = dataSet.shape[0] #求数组的行数 diffarray = tile(inX, (dataSetSize, 1))-dataSet #tile使inx变为和dataSet相同行数的数组 squarediffarray = diffarray**2 # x^2 , y^2 sqDistances = squarediffarray.sum(axis=1) #对每一行向量求和 distances = sqDistances**2 #对每个和开根号 sortedDistIndexes = distances.argsort() #将所有值从小到大排序,取原先的索引 mp = {} #print(sortedDistIndexes[0:1024]) for i in range(k): templabel = labels[sortedDistIndexes[i]] mp[templabel] = mp.get(templabel,0)+1 #dict.get(key,default=None),不存在返回0 sortedmp = sorted(mp.items(),key=operator.itemgetter(1),reverse=True) #[('D', 312), ('I', 100), ('C', 4), ('B', 3), ('A', 1)] #将出现次数较多的情况返回 return sortedmp[0][0] #该函数的输入为文本名字符串,输出位训练样本矩阵和类标记向量 def filearray(filename): fr = open(filename) #a = array([1,2,3,4,5]) arrayOLines = fr.readlines() #print(arrayOLines) #numberOfLines = len(a) numberOfLines = len(arrayOLines) #print(numberOfLines) #print(type(zeros((numberOfLines,3)))) returnarray = zeros((numberOfLines,3)) labels = [] index = 0 for line in arrayOLines: line = line.strip() #去掉回车 #print(line) listFromLine = line.split(' ') #print(listFromLine) #变成列表 returnarray[index,:] = listFromLine[0:3] labels.append(int((listFromLine[-1]))) #应用数据错误 index += 1 return returnarray,labels def main(): # group,labels = createDataSet() # var = classify([0.8,1.0],group ,labels , 3) # print(var) datingDataArray,datinglabels = filearray('d3.txt') #datingDataArray,datinglabels = filearray('datingTestSet2.txt') # fig = plt.figure() # ax = fig.add_subplot(111) # ax.scatter(datingDataArray[:,0],datingDataArray[:,1 # ], # 15.0*array(datinglabels),15.0*array(datinglabels)) #第1列和第2列 # plt.show() #print(datingDataArray) #print(datinglabels) autoNorm(datingDataArray) #数值归一化 #(oldValue - minVal)/(maxVal-minVal) def autoNorm(dataSet): minVals = dataSet.min(0) #获取每一列的最小值和最大值 maxVals = dataSet.max(0) # print(minVals) # print(maxVals) ranges = maxVals-minVals #print(shape(dataSet)) (9, 3) normDataSet = zeros(shape(dataSet)) #shape()返回矩阵规模 m = dataSet.shape[0] normDataSet = dataSet - tile(minVals, (m, 1)) normDataSet = normDataSet/tile(ranges, (m, 1)) #print(normDataSet) return normDataSet,ranges,minVals #计算错误率 def datingCalcError(): Radio = 0.1 datingDataArray,datinglabels = filearray('datingTestSet2.txt') normArray,ranges,minVals = autoNorm(datingDataArray) m = normArray.shape[0] numOfTestData = int(m*Radio) #10% errorNumber = 0.0 #浮点数 for i in range(numOfTestData): #90% classifierResult = classify(normArray[i,:],normArray[numOfTestData:m,:], datinglabels[numOfTestData:m],3) print("the test result:%d, the real result:%d"%(classifierResult,datinglabels[i])) if(classifierResult!=datinglabels[i]): errorNumber += 1.0 print("the error rate is %f"%(errorNumber/(float(numOfTestData)))) #约会网站测试函数 def classifyPerson(): resultList = ['not at all','in small doses','in large doses'] ffMiles = float(input('flier miles')) percentTats = float(input('playing game')) #不再有raw_input函数 iceCream = float(input('ice cream')) datingDataArray,datinglabels = filearray('datingTestSet2.txt') normArray,ranges,minVals = autoNorm(datingDataArray) inArr = array([ffMiles,percentTats,iceCream]) #print(inArr) classifierResult = classify(((inArr - minVals)/ranges),normArray, datinglabels, 3) print(resultList[classifierResult-1]) def imgVector(filename): returnVector = zeros((1,1024)) fr = open(filename) for i in range(32): lineStr = fr.readline() for j in range(32): returnVector[0,32*i+j] = int(lineStr[j]) #print(returnVector[0,0:32]) return returnVector def handwritingClassTest(): hwlabels = [] trainingFileList = listdir('trainingDigits') m = len(trainingFileList) #list用len,array用shape[0] trainingArray = zeros((m,1024)) #储存训练矩阵 for i in range(m): fileNameStr = trainingFileList[i] fileStr = fileNameStr.split('.')[0] #['0_100', 'txt'] print(fileStr) #0_102 classNum = int(fileStr.split('_')[0]) hwlabels.append(classNum) #hwlabels[i] = classNum trainingArray[i,:] = imgVector('trainingDigits/%s'%fileNameStr) testFileList = listdir('testDigits') errorNumber = 0.0 mTest = len(testFileList) for i in range(mTest): fileNameStr = testFileList[i] fileStr = fileNameStr.split('.')[0] #['0_100', 'txt'] print(fileStr) #0_102 classNum = int(fileStr.split('_')[0]) testVector = imgVector('testDigits/%s'%fileNameStr) classifierResult = classify(testVector,trainingArray,hwlabels,3) print("the test result:%d, the real result:%d"%(classifierResult,classNum)) if(classifierResult!=classNum): errorNumber += 1.0 print("the error rate is %f"%(errorNumber/(float(mTest)))) # for i in range(len(hwlabels)): # print(hwlabels[i]) #main() #classifyPerson() #imgVector('testDigits/0_12.txt') handwritingClassTest()