因为教程的demo网站糗事百科已经gg(好像是涉及用户私人信息什么的原因),所以我就只好随便找了个网站练手。
前几天学习了部分lxml的用法,主要是etree,因为4.4.2版本的更新,etree现在在ElementInclude包内,直接引用是不行了,并且etree添加了新的parser,调用parse方法时要先实例化HTMLparse方法,当然我这个垃圾爬虫没有用爬取html和数据清洗两个步骤分离,而且demo么没有用多线程,导致爬200个鬼故事,几mb的txt,爬取写入时间真的不是很理想啊(雾,大草),所以说多线程时多么重要。xxxxx
首先哦f12分析下网站源码,要获取的内容和分页网址,因为我们获取的内容都是文字,且都显式显示在网页上,很容易得出规律:
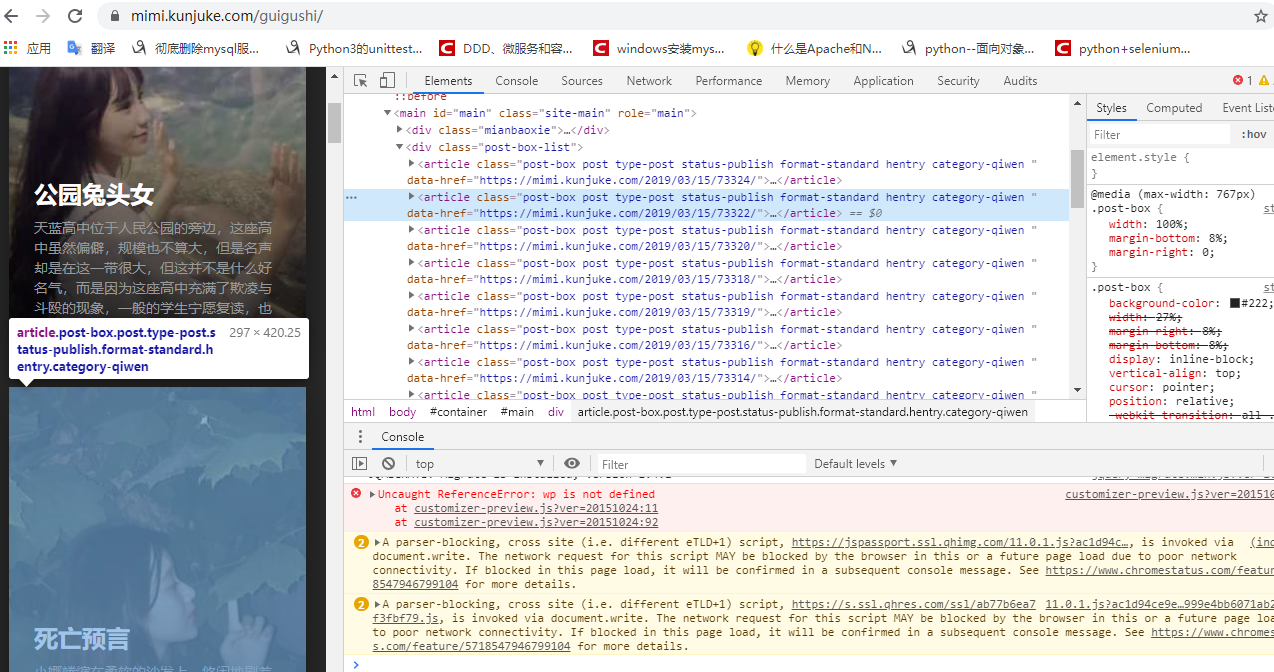
我们要获取的鬼故事内容页面的链接 <a>标签,在<article>标签下,可以使用xpath定位到,(“//article//h2/a/@href”),即可获取到当前页面20个鬼故事的内容页链接
接着打开内容详情页
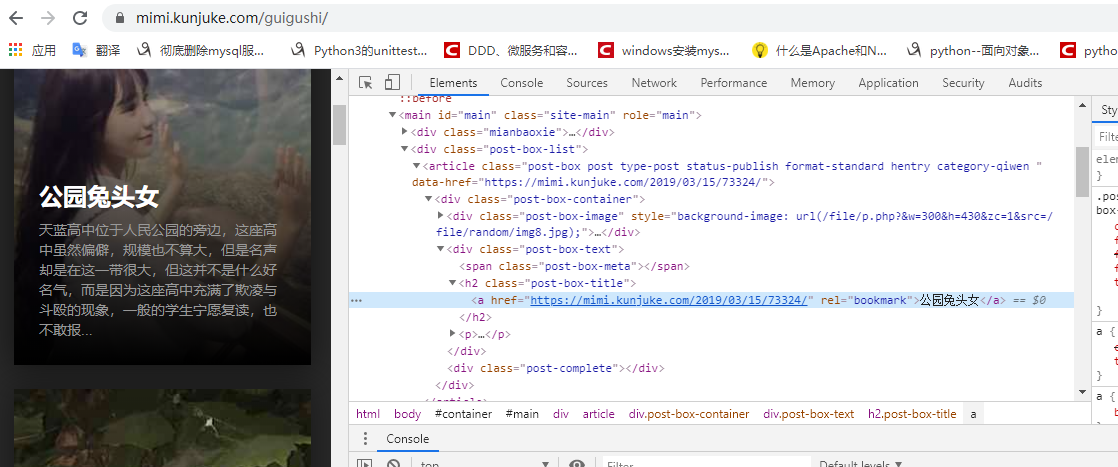
很容易看到,我们想要的<p>标签文本内容在id = “single”的div下,可以用xpath定位到,(“//div[@id='single']”//p)

当人内容分页还是一如既往的每页20个,拼接网址也有了,/page/i 就完事了

没抓图片,虽然显然图文无关 xxxxx
然后是代码实现
import requests from lxml.ElementInclude import etree for i in range(1, 11): url = "https://mimi.kunjuke.com/guigushi/page/" + str(i) headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36"} res = requests.get(url, headers=headers).text html = etree.HTML(res) url_result = html.xpath("//article//h2/a/@href") for site in url_result: res2 = requests.get(site).text html2 = etree.HTML(res2) content_result = html2.xpath("//div[@id='single']//p") title_result = html2.xpath("//div[@id='single']//h2") storyName = "H:/GhostStory/"+title_result[0].text+".txt" with open(storyName,"wb+") as f: f.write(bytes(content_result[0].text, encoding="utf-8"))
很简单的实现,诶呀不用多线程爬这种几kb的txt,真实难受,看来后续还要进一步学习多线程啊
因为没做日志info或者系统打印台输出和异常管理,嘿嘿,懒狗,手动校验一下吧
爬完校验一下是不是爬了十页两百个鬼故事
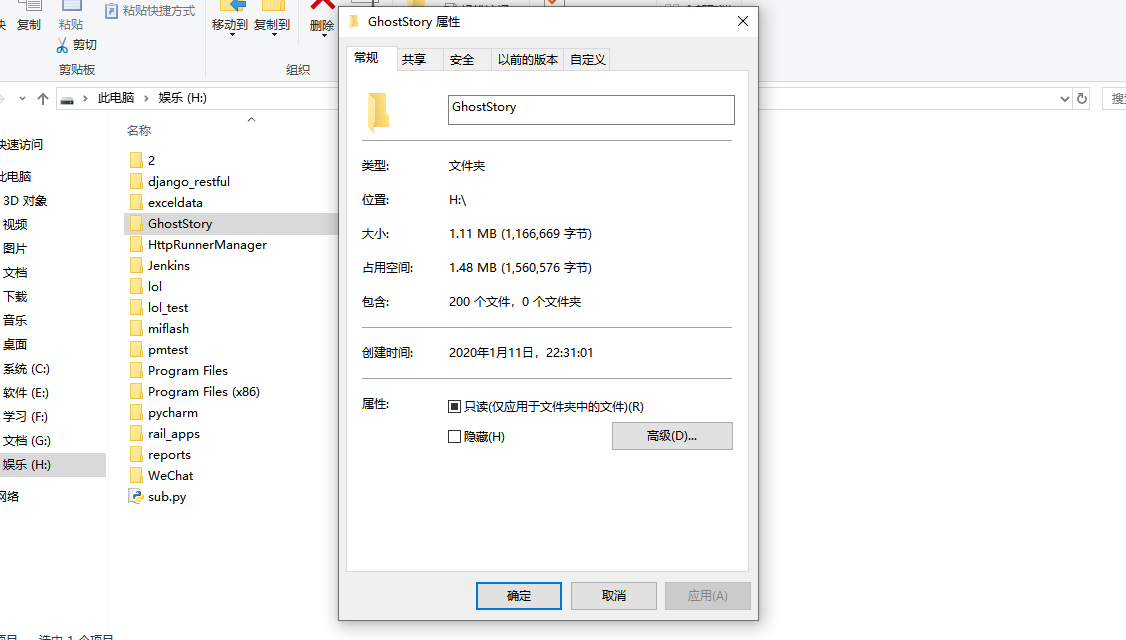
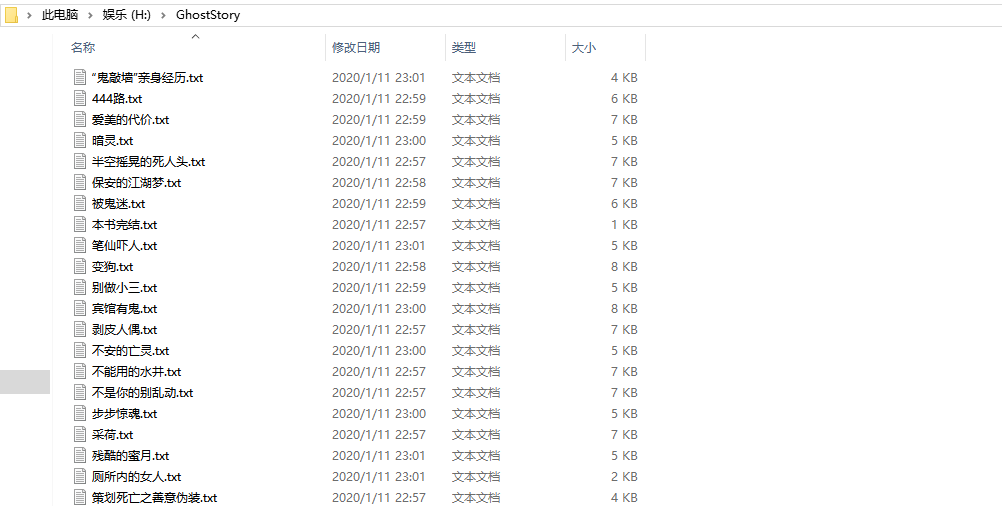
打开一个看看,i/o和encoding没写错的话就应该没问题
bingo ,欸,好垃圾哦, 我转了一圈吃完一个肉松饼,这200个鬼故事还没爬完,残念xxxxxx
下次一定,下次一定,下次一定补上 info ,异常和多线程,惭愧地流出了虚假地泪水 喵 >_<!!!