1、sql语句索引失效:
索引建立顺序与条件里的顺序不一致;
对索引字段使用了 like,not in,<>、!=、sum、is null、is not null;
条件里写的类型不对
使用了函数或空值
2、union all 比union 效率高, 比union 快很多
select user_id from friend where valid_status=1
union
select user_id from friend_request where auditor_id=1079 LIMIT 10;
select user_id from friend where valid_status=1
union all
select user_id from friend_request where auditor_id=1079 LIMIT 10
两个SQL查询结果如下所示:

2.1、union对筛选结果自动去重, union all不会去除重复
2.2、union对筛选结果按字段顺序排序, union all只是简单的把两个结果合并返回
3、where语句高效使用
3.1、避免where子句中使用in,not in ,or ,having。建议使用exist,not exist代替in,not in . having可以使用where代替,若无法代替可以分两步处理
下面两组表达式等效,但第一三个高效,二四低效
select user_id from friend f where
not exists
(select user_id from friend_request fr where f.id=fr.id);
select user_id from friend where id
not in
(select id from friend_request );
select user_id from friend f where
exists
(select user_id from friend_request fr where f.id=fr.id);
select user_id from friend where id
in
(select id from friend_request );
3.2、避免字符格式声明数字,要以数字格式声明字符值
select * from friend where owner_id=1017; -- 高效
select * from friend where owner_id='1017'; -- 低效
4、select 语句的高效使用,限制使用"*",建议查询具体列名
select id,user_id from friend; -- 高效
select * from friend; -- 低效
5、避免使用耗费资源的操作,例distinct,union,minus,intersect,order by的sql语句会启动sql引擎执行,耗费资源的排序(sort)功能,distinct需要一次排序操作,而其它的至少需要执行两次排序。
-
优化sql server数据库方法:
1、查询速度慢的常见原因如下:
没有索引或没有用到索引(最常见,是程序设计的问题)
锁或死锁(常见,my sql查询是否锁表:show OPEN TABLES where In_use > 0;)
查询结果数据量过大(可多次查询)
返回了不必要的行和列
内存不足
网络速度慢
I/O吞吐量小,形成了瓶颈
解决方法如下:
根据查询条件 建立或优化索引,限制结果集的数据量,注意填充因子要适当,索引应该尽量小,用字节数小的列建索引列
提高网速;升级硬件
mysql自动评估并行处理还是串行处理;查询适合并行,update、insert、delete需要串行处理
对于需要like "%a%"的字段,一般用varchar(长度不固定),而不是用char(长度固定)
commit为提交当前事物,rollback是回滚所有的事物
sql的注释信息对执行效率没有影响
尽量不使用光标,它占用大量资源。如需row-by-row地执行,可在客户端循环、临时表、子查询
union all比union效率要高
没有必要时不要用distinct,它同union一样会使查询变慢,重复的记录在是没有问题的
查询时不要返回多余的行和列
not in 会多次扫描表,使用exists,not exists,in left outer join
min(),max()能使用到合适的索引
between会比in高效,因为in会有多次比较(如果只会用in,将出现频繁的值放在最前面,出现少的值放在后面,减少判断次数):
select * from friend where user_id in (1001,1002,1003,1004); -- 低效 in会多次比较
select * from friend where user_id BETWEEN 1001 and 1004 -- 高效
用or的子句可以分解成多个查询,通过union或union all 连接多个查询
视图效率比直接操作表低,可以用存储过程stored procedure来代替视图
没有必要时不要用distinct和order by
查询是否锁表:show OPEN TABLES where In_use > 0;
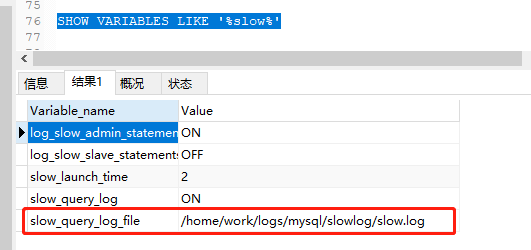
查询慢sql存放位置:SHOW VARIABLES LIKE '%slow%';