---恢复内容开始---
一: web 应用模式(有两种)
1: 前后端不分离(前端从后端直接获取数据)
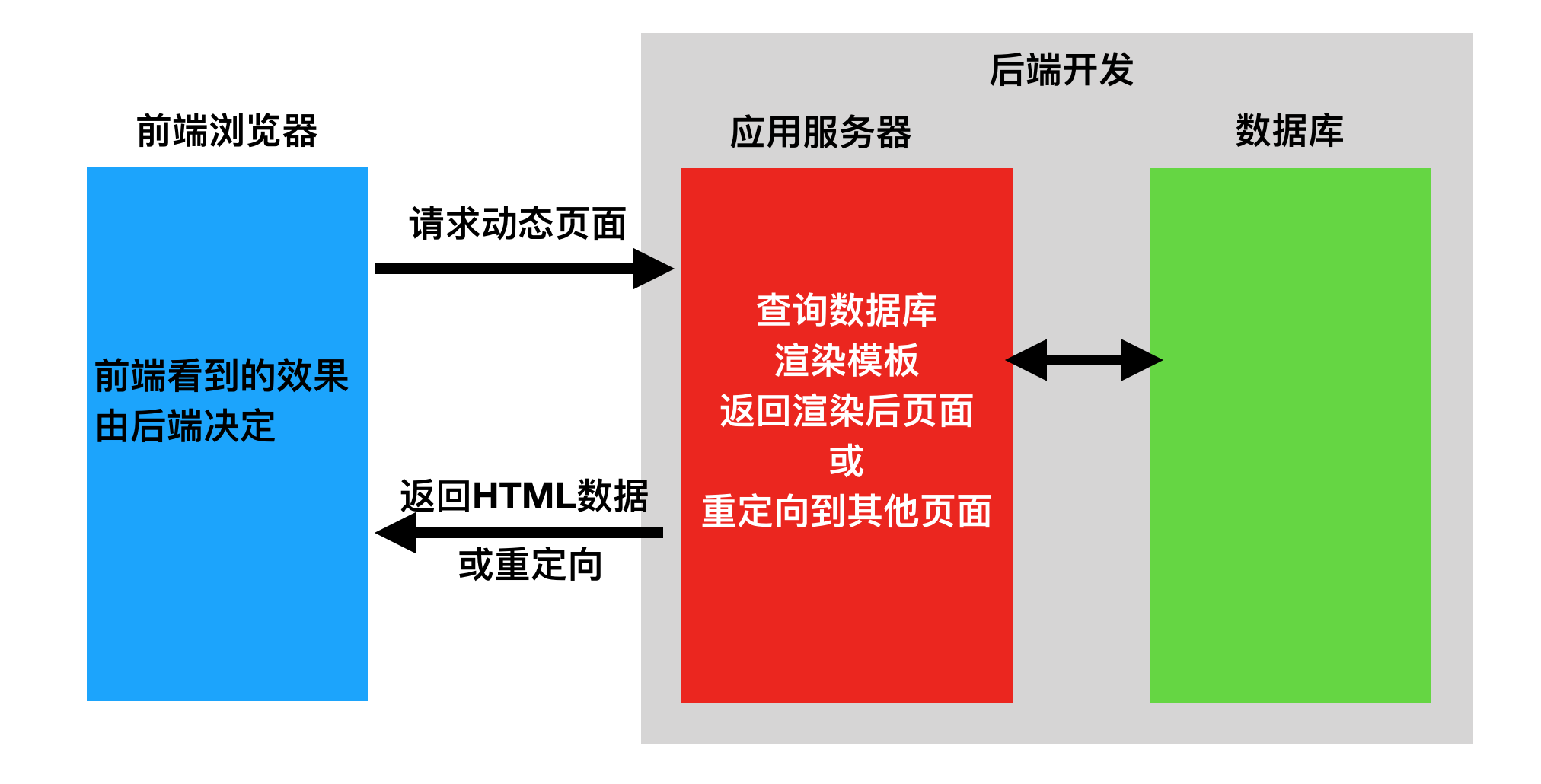
2: 前后端分离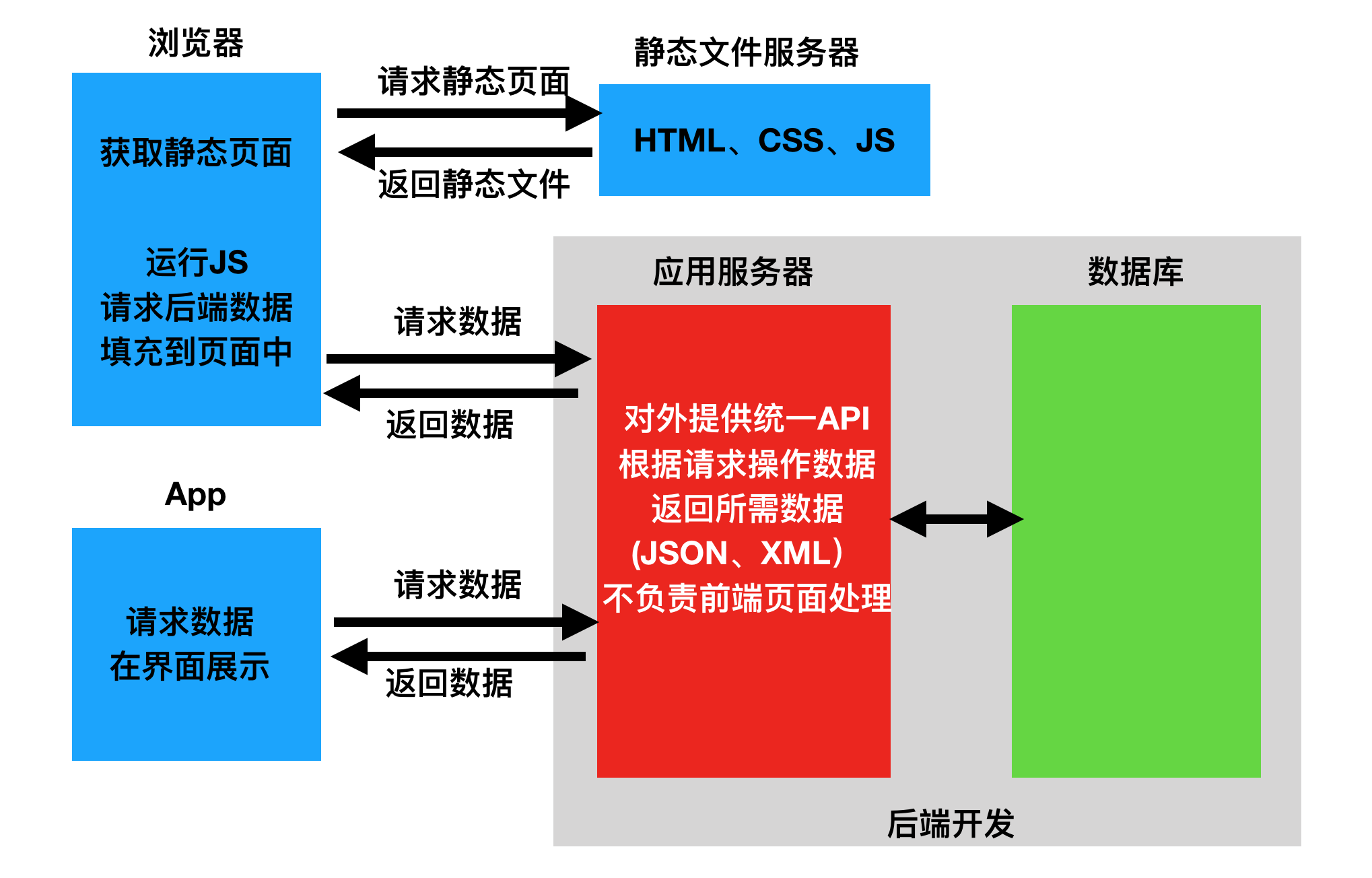
二: api 接口
原因一: 为了在团队内部形成共识、防止个人习惯差异引起的混乱,我们需要找到一种大家都觉得很好的接口实现规范,
而且这种规范能够让后端写的接口,用途一目了然,减少双方之间的合作成本。 目前市面上大部分公司开发人员使用的接口服务架构主要有:restful、rpc。 1: rpc: 翻译成中文:远程过程调用[远程服务调用]. post请求 action=get_all_student¶ms=301&sex=1 原因二: 接口多了,对应函数名和参数就多了,前端在请求api接口时,就会比较难找.容易出现重复的接口 2: restful: 翻译成中文: 资源状态转换. 把后端所有的数据/文件都看成资源. 那么接口请求数据,本质上来说就是对资源的操作了. web项目中操作资源,无非就是增删查改.所以要求在地址栏中声明要操作的资源是什么,然后通过http请求动词来说明对资源进行哪一种操作. POST http://www.lufei.com/api/students/ 添加数据 GET http://www.lufei.com/api/students/ 获取所有学生
三: RESTful API规范
REST全称是Representational State Transfer,中文意思是表述(编者注:通常译为表征)性状态转移。 它首次出现在2000年Roy Fielding的博士论文中。
RESTful是一种定义Web API接口的设计风格,尤其适用于前后端分离的应用模式中。
这种风格的理念认为后端开发任务就是提供数据的,对外提供的是数据资源的访问接口,所以在定义接口时,客户端访问的URL路径就表示这种要操作的数据资源。
而对于数据资源分别使用POST、DELETE、GET、UPDATE等请求动作来表达对数据的增删查改。
| 请求地址 | 后端操作 | |
|---|---|---|
| GET | /students | 获取所有学生 |
| POST | /students | 增加学生 |
| GET | /students/1 | 获取编号为1的学生 |
| PUT | /students/1 | 修改编号为1的学生 |
| DELETE | /students/1 |
事实上,我们可以使用任何一个框架都可以实现符合restful规范的API接口。
四: 序列化
api接口开发,最核心最常见的一个过程就是序列化,所谓序列化就是把**数据转换格式**,序列化可以分两个阶段: 1. 序列化: 把我们识别的数据转换成指定的格式提供给别人。 例如:我们在django中获取到的数据默认是模型对象,但是模型对象数据无法直接提供给前端或别的平台使用,所以我们需要把数据进行序列化,变成字符串或者json数据,提供给别人。 2.反序列化:把别人提供的数据转换/还原成我们需要的格式。 例如:前端js提供过来的json数据,对于python而言就是字符串,我们需要进行反序列化换成模型类对象,这样我们才能把数据保存到数据库中。
五:
核心思想:缩减编写api接口的代码
执行流程:
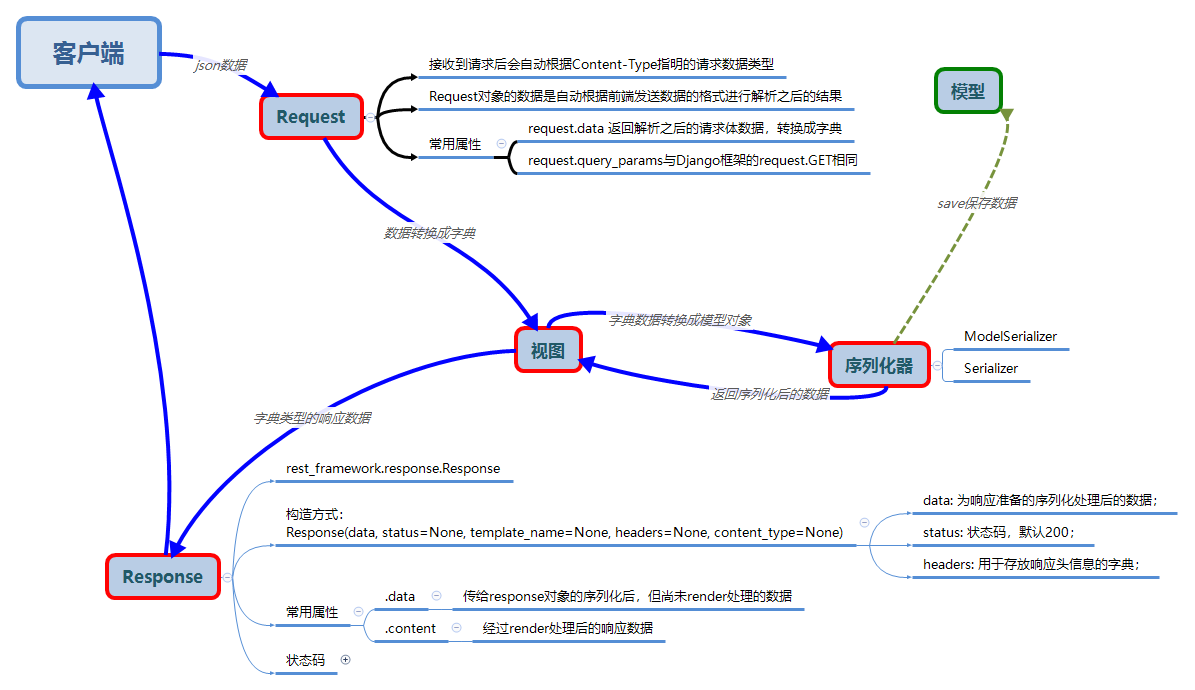
中文文档:https://q1mi.github.io/Django-REST-framework-documentation/#django-rest-framework


Django REST framework是一个建立在Django基础之上的Web 应用开发框架,可以快速的开发REST API接口应用。在REST framework中,提供了序列化器Serialzier的定义,可以帮助我们简化序列化与反序列化的过程,不仅如此,还提供丰富的类视图、扩展类、视图集来简化视图的编写工作。REST framework还提供了认证、权限、限流、过滤、分页、接口文档等功能支持。REST framework提供了一个API 的Web可视化界面来方便查看测试接口。
- 提供了定义序列化器Serializer的方法,可以快速根据 Django ORM 或者其它库自动序列化/反序列化; - 提供了丰富的类视图、Mixin扩展类,简化视图的编写; - 丰富的定制层级:函数视图、类视图、视图集合到自动生成 API,满足各种需要; - 多种身份认证和权限认证方式的支持;[jwt] - 内置了限流系统; - 直观的 API web 界面; - 可扩展性,插件丰富
六: 安装及配置环境
1.部署环境
DRF需要以下依赖: - Python (2.7, 3.2, 3.3, 3.4, 3.5, 3.6) - Django (1.10, 1.11, 2.0) -DRF是以Django扩展应用的方式提供的,所以我们可以直接利用已有的Django环境而无需从新创建。(若没有Django环境,需要先创建环境安装Django)
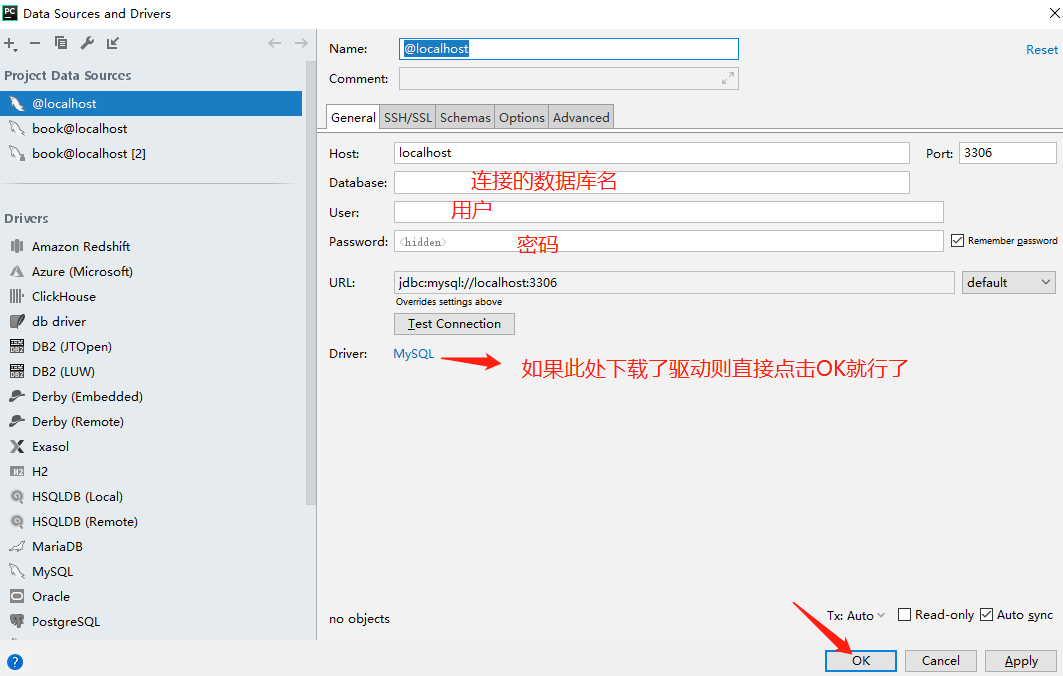
1. 本地安装django项目 django-admin startproject drf 2. 创建子应用目录booktest,在项目根目录下执行以下命令 python manage.py startapp booktest 创建一个数据库,book create database book charset=utf8; grant all privileges on book.* to root@localhost identified by '123456'; flush privileges; 3. 配置数据库信息 3.1 在主应用drf目录下的drf/__init__.py添加以下代码: import pymysql pymysql.install_as_MySQLdb() 3.2 在项目配置文件中,settings中修改数据链接信息。 DATABASES = { # 'default': { # 'ENGINE': 'django.db.backends.sqlite3', # 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), # } 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'drf', 'USER': 'root', 'PASSWORD': '123456', 'HOST': '127.0.0.1', 'PORT': '3306', }, }
2. 定义
创建应用book_test,在book_test目录下的models.py中定义模型类,创建模型表
from django.db import models #定义图书模型类BookInfo class BookInfo(models.Model): btitle = models.CharField(max_length=20, verbose_name='图书标题') bpub_date = models.DateField(verbose_name='出版时间') bread = models.IntegerField(default=0, verbose_name='阅读量') bcomment = models.IntegerField(default=0, verbose_name='评论量') is_delete = models.BooleanField(default=False, verbose_name='逻辑删除') class Meta: db_table = 'tb_books' # 指明数据库表名 verbose_name = '图书' # 在admin站点中显示的名称 verbose_name_plural = verbose_name # 显示的复数名称 def __str__(self): """定义每个数据对象的显示信息""" return "图书:《"+self.btitle+"》" #定义英雄模型类HeroInfo class HeroInfo(models.Model): GENDER_CHOICES = ( (0, 'female'), (1, 'male') ) hname = models.CharField(max_length=20, verbose_name='名称') hgender = models.SmallIntegerField(choices=GENDER_CHOICES, default=0, verbose_name='性别') hcomment = models.CharField(max_length=200, null=True, verbose_name='描述信息') hbook = models.ForeignKey(BookInfo, on_delete=models.CASCADE, verbose_name='图书') # 外键 is_delete = models.BooleanField(default=False, verbose_name='逻辑删除') class Meta: db_table = 'tb_heros' verbose_name = '英雄' verbose_name_plural = verbose_name def __str__(self): return self.hname
1) 数据库表名 模型类如果未指明表名,Django默认以 小写app应用名_小写模型类名 为数据库表名。 可通过db_table 指明数据库表名。 2) 关于主键 django会为表创建自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后django不会再创建自动增长的主键列。 默认创建的主键列属性为id,可以使用pk代替,pk全拼为primary key。 3) 属性命名限制 - 不能是python的保留关键字。 - 不允许使用连续的下划线,这是由django的查询方式决定的。 - 定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下: 属性=models.字段类型(选项) 4)字段类型
| 说明 | |
|---|---|
| AutoField | 自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性 |
| BooleanField | 布尔字段,值为True或False |
| NullBooleanField | 支持Null、True、False三种值 |
| CharField | 字符串,参数max_length表示最大字符个数 |
| TextField | 大文本字段,一般超过4000个字符时使用 |
| IntegerField | 整数 |
| DecimalField | 十进制浮点数, 参数max_digits表示总位数, 参数decimal_places表示小数位数 |
| FloatField | 浮点数 |
| DateField | 日期, 参数auto_now表示每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为False; 参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为False; 参数auto_now_add和auto_now是相互排斥的,组合将会发生错误 |
| TimeField | 时间,参数同DateField |
| DateTimeField | 日期时间,参数同DateField |
| FileField | 上传文件字段 |
| ImageField |
5)选项
| 说明 | |
|---|---|
| null | 如果为True,表示允许为空,默认值是False |
| blank | 如果为True,则该字段允许为空白,默认值是False |
| db_column | 字段的名称,如果未指定,则使用属性的名称 |
| db_index | 若值为True, 则在表中会为此字段创建索引,默认值是False |
| default | 默认 |
| primary_key | 若为True,则该字段会成为模型的主键字段,默认值是False,一般作为AutoField的选项使用 |
| unique |
6) 外键
在设置外键时,需要通过**on_delete**选项指明主表删除数据时,对于外键引用表数据如何处理,在django.db.models中包含了可选常量:
- **CASCADE** 级联,删除主表数据时连通一起删除外键表中数据
- **PROTECT** 保护,通过抛出**ProtectedError**异常,来阻止删除主表中被外键应用的数据
- **SET_NULL** 设置为NULL,仅在该字段null=True允许为null时可用
- **SET_DEFAULT** 设置为默认值,仅在该字段设置了默认值时可用
- **SET()** 设置为特定值或者调用特定方法,如
from django.conf import settings
from django.contrib.auth import get_user_model
from django.db import models
def get_sentinel_user():
return get_user_model().objects.get_or_create(username='deleted')[0]
class MyModel(models.Model):
user = models.ForeignKey(
settings.AUTH_USER_MODEL,
on_delete=models.SET(get_sentinel_user),
)
**DO_NOTHING** 不做任何操作,如果数据库前置指明级联性,此选项会抛出**IntegrityError**异常
3. 数据迁移(将模型类同步到数据库中)
1)生成迁移文件 python manage.py makemigrations 2)同步到数据库中 python manage.py migrate
4.添加测试数据
insert into tb_books(btitle,bpub_date,bread,bcomment,is_delete) values ('射雕英雄传','1980-5-1',12,34,0), ('天龙八部','1986-7-24',36,40,0), ('笑傲江湖','1995-12-24',20,80,0), ('雪山飞狐','1987-11-11',58,24,0); insert into tb_heros(hname,hgender,hbook_id,hcomment,is_delete) values ('郭靖',1,1,'降龙十八掌',0), ('黄蓉',0,1,'打狗棍法',0), ('黄药师',1,1,'弹指神通',0), ('欧阳锋',1,1,'蛤蟆功',0), ('梅超风',0,1,'九阴白骨爪',0), ('乔峰',1,2,'降龙十八掌',0), ('段誉',1,2,'六脉神剑',0), ('虚竹',1,2,'天山六阳掌',0), ('王语嫣',0,2,'神仙姐姐',0), ('令狐冲',1,3,'独孤九剑',0), ('任盈盈',0,3,'弹琴',0), ('岳不群',1,3,'华山剑法',0), ('东方不败',0,3,'葵花宝典',0), ('胡斐',1,4,'胡家刀法',0), ('苗若兰',0,4,'黄衣',0), ('程灵素',0,4,'医术',0), ('袁紫衣',0,4,'六合拳',0);
使用pycharm插入数据 方法如下
第一步:
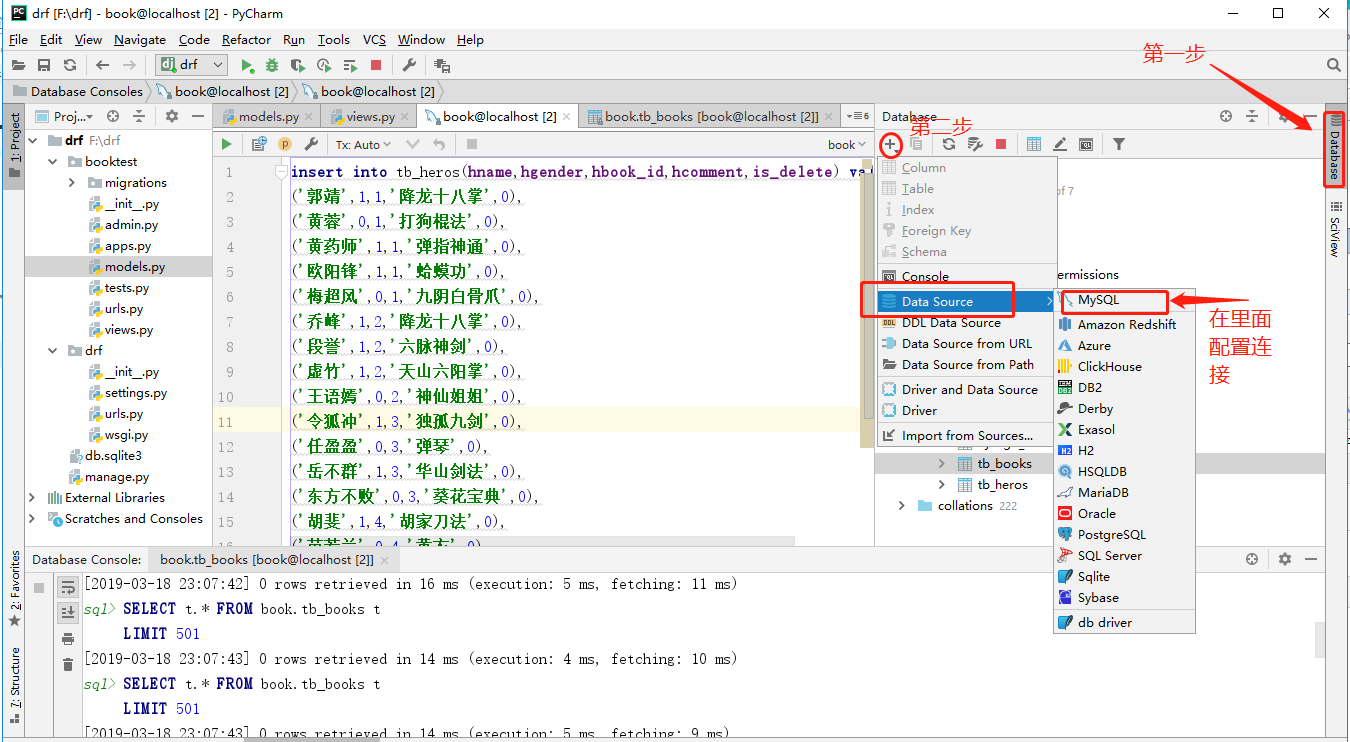
第二部:
第三步

5. 配置项目路由
1).在全局路由

from django.contrib import admin from django.urls import path,include urlpatterns = [ path('admin/', admin.site.urls), path('api/',include("booktest.urls")) ]
2)在分支路由配置book_test下创建路由文件urls.py
from django.urls import path
from .views import BookAPI
urlpatterns={
path(r"books/",BookAPI.as_view()),
}
6. 开发图书相关的数据接口的视图函数
from django.shortcuts import render # Create your views here. # Create your views here. # 图书相关的restful api接口 # 获取所有数据 # 添加一条数据 # 删除一条数据 # 修改一条数据 from django.views import View from .models import BookInfo from django.http.response import JsonResponse class BookAPI(View): def get(self,request): '''获取所有图书数据''' #1 操作数据库 books=BookInfo.objects.all() #2 序列化转换数据 data=[] for book in books: data.append({ "id":book.id, "btitle":book.btitle, }) #3 返回客户端 #safe=false 不要对json数据进行安全监测,默认情况下jsonresponse #不能对列表数据进行转换json return JsonResponse(data,safe=False)
7. 运行项目
python manage.py migrate
浏览器效果:
七创建
1 在窗口执行
python manage.py startapp app
2.安装DRF
pip install djangorestframework
3.全局配置文件seting.py中注册app
INSTALLED_APPS = [
...
'rest_framework',
]
接下来就可以使用DRF进行开发了。在项目中如果使用rest_framework框架实现API接口,主要有以下三个步骤: - 将请求的数据(如JSON格式)转换为模型类对象 - 操作数据库 - 将模型类对象转换为响应的数据(如JSON格式)
4 在全局路由配置文件中注册路由
drf.urls.py中注册路由
path('app/', include('app.urls')),
5 在app应用下创建局部分支路由文件urls.py,代码如下
from rest_framework.routers import DefaultRouter from .views import BookInfoAPIView urlpatterns = [ ] # 创建路由对象 routers = DefaultRouter() # # 通过路由对象对视图类进行路由生成 routers.register("books",BookInfoAPIView) print(">>>>>",routers.urls) urlpatterns+=routers.urls
6. 创建序列化器
在app应用中创建序列化器
from rest_framework import serializers from booktest.models import BookInfo class BookInfoSerializer(serializers.ModelSerializer): """专门用于对图书进行进行序列化和反序列化的类: 序列化器类""" class Meta: # 当前序列化器在序列化数据的时候,使用哪个模型 model = BookInfo # fields = ["id","btitle"] # 多个字段可以使用列表声明,如果是所有字段都要转换,则使用 '__all__' fields = '__all__' # 多个字段可以使用列表声明,如果是所有字段都要转换,则使用 '__all__'
7. 在app应用视图函数中views.py中序列化数据,代码如下
from rest_framework.viewsets import ModelViewSet from booktest.models import BookInfo from .serializers import BookInfoSerializer # Create your views here. class BookInfoAPIView(ModelViewSet): # 当前视图类所有方法使用得数据结果集是谁? queryset = BookInfo.objects.all() # 当前视图类使用序列化器类是谁 serializer_class = BookInfoSerializer
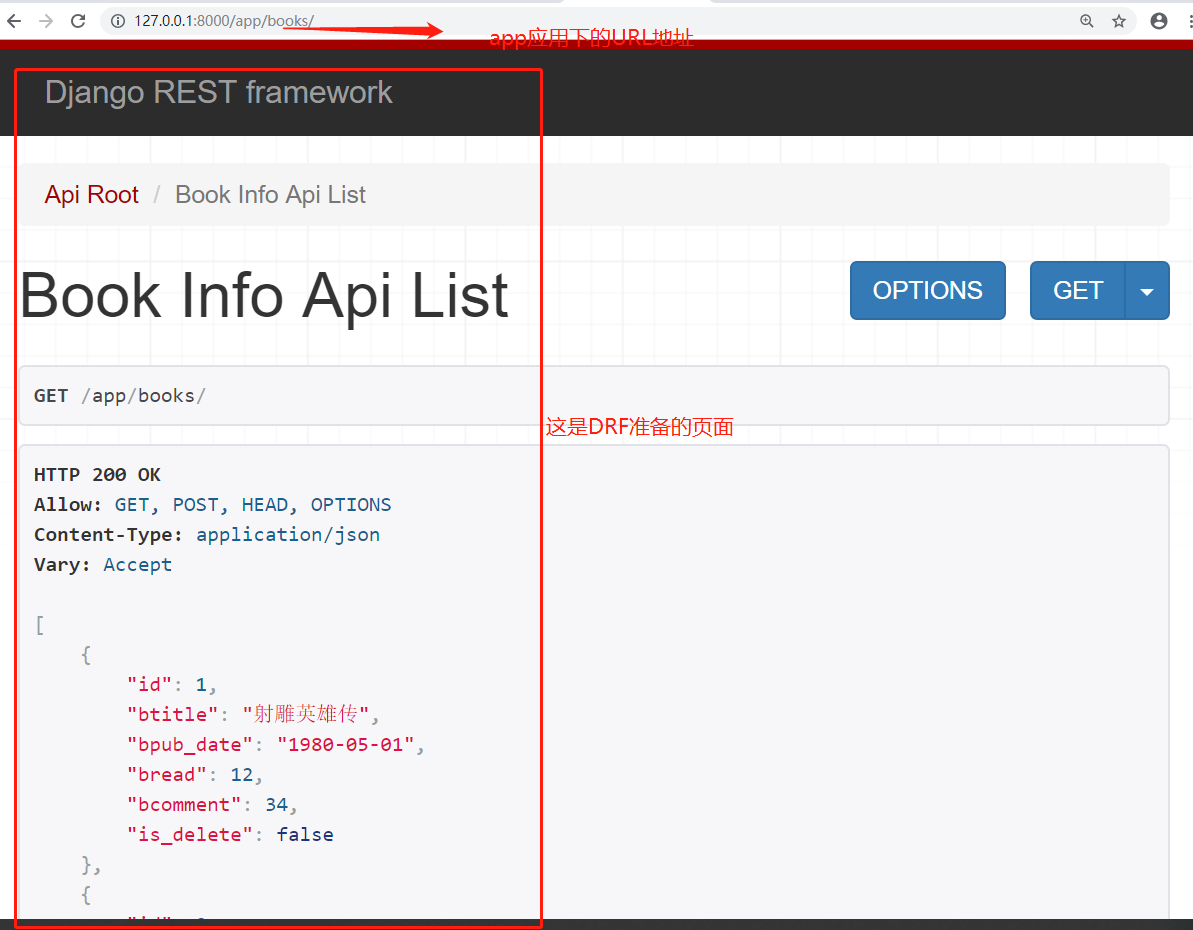
8. 重启应用
访问DRF应用下的url地址,效果如下:
八. 序列化器-Serializer
1. 作用:
1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串 2. 完成数据校验功能 3. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型
2.定义序列化器
Django REST framework中的Serializer使用类来定义,须继承自rest_framework.serializers.Serializer。
3 案例
1)创建序列化器应用
python manage.py startapp ser
2)在全局配置文件seting.py中注册应用
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'booktest',
'rest_framework',
'app',
'ser', #序列化器应用
]
3)路由分发
1.全局urls.py文件中注册路由
path('ser/',include("ser.urls")),
2.在应用中局部创建urls.py文件并进行分发,代码如下:
from django.urls import path,re_path
from . import views
urlpatterns=[
path("books/",views.BookInfoView.as_view()),
path("books2/",views.BookInfo2View.as_view())
re_path("books2/(?P<pk>d+)/",views.BookInfo2View.as_view()),
path("books3/",views.BookInfo3View.as_view()),
]
4)创建serializers,py文件,并创建序列化器, 代码及其serializers序列化和反序列化使用方法如下
############################################### ###1. 序列化器的序列化阶段使用 ############################################### from rest_framework import serializers class BookInfo2Serializer(serializers.Serializer): #自定义要序列化的字段 id = serializers.IntegerField(label="主键ID", read_only=True) btitle=serializers.CharField(label="图书标题") bpub_date = serializers.DateField(label="出版日期") bread=serializers.IntegerField(label="阅读量") bcomment=serializers.IntegerField(label="评论量") is_delete=serializers.BooleanField(label="逻辑删除") ############################################# # 2 序列化器的反序列化阶段使用 # 主要用户验证数据和字典数据转换成模型 ############################################# from rest_framework import serializers from booktest.models import BookInfo # 自定义验证字段选项函数 def check_btitle(data): if data=="西厢记": raise serializers.ValidationError("西厢记也是禁书~") # 一定要返回数据 return data class BookInfo2Serializer(serializers.Serializer): # 自定义要反序列化的字段 id = serializers.IntegerField(label="主键ID",read_only=True) btitle = serializers.CharField(label="标题",required=True,min_length=1,max_length=20,validators=[check_btitle]) bpub_date=serializers.DateField(label="出版日期") bread=serializers.IntegerField(label="阅读量",min_value=0) bcomment=serializers.IntegerField(label="评论量",default=0) # required=False 反序列化时, 当前字段可以不填 is_delete=serializers.BooleanField(label="逻辑删除") # 自定义验证方法[验证单个字段,可以有多个方法] # def validate_<字段名>(self,data): # data当前字段对应的值 def validate_btitle(self,data): # 例如,图书名不能是红楼梦 if data=="红楼梦": # 抛出错误 raise serializers.ValidationError("红楼梦是禁书~") # 验证方法中,把数据值必须返回给字段,否则字段值为空 return data # 自定义验证方法[验证多个或者所有字段,只能出现一次] def validate(self,data): # data 这个是所有字段的内容,字典类型 bread = data.get("bread") bcomment = data.get("bcomment") if bread>=bcomment: return data raise serializers.ValidationError("阅读量小于评论量,数据太假了") def create(self,validated_data): """保存数据,把字典转换成模型 validated_data 客户端提交过来,并经过验证的数据 """ instance = BookInfo.objects.create( btitle = validated_data.get("btitle"), bread = validated_data.get("bread"), bcomment = validated_data.get("bcomment"), bpub_date = validated_data.get("bpub_date"), is_delete = validated_data.get("is_delete"), ) return instance def update(self,instance,validated_data): """更新数据 instance 本次更新操作的模型对象 validated_data 客户端提交过来,并经过验证的数据 """ instance.btitle=validated_data.get('btitle') instance.bread=validated_data.get('bread') instance.bcomment=validated_data.get('bcomment') instance.bpub_date=validated_data.get('bpub_date') instance.is_delete=validated_data.get('is_delete') # 调用ORM的保存更新操作 instance.save() # 返回模型对象 return instance ############################################# # 3 模型序列化器 # 1. 可以帮我们自动完成字段的声明[主要是从模型中的字段声明里面提取过来] # 2. 模型序列化器也可以帮我们声明了create和update方法的代码 ############################################# from rest_framework import serializers from booktest.models import BookInfo class BookInfoModelSerializer(serializers.ModelSerializer): # 模型序列化器也可以自定义验证字段[当某些数据不存在于数据库时,但是需要前端提交过来的,可以进行自定义, # 例如,验证码,确认密码] class Meta: model=BookInfo fields = "__all__" # 可以给模型序列化器里面指定的字段设置限制选项 extra_kwargs = { "bread":{"min_value":0,"required":True}, } # 自定义验证方法[验证单个字段,可以有多个方法] # def validate_<字段名>(self,data): # data当前字段对应的值 def validate_btitle(self,data): # 例如,图书名不能是红楼梦 if data=="红楼梦": # 抛出错误 raise serializers.ValidationError("红楼梦是禁书~") # 验证方法中,把数据值必须返回给字段,否则字段值为空 return data # 自定义验证方法[验证多个或者所有字段,只能出现一次] def validate(self,data): # data 这个是所有字段的内容,字典类型 bread = data.get("bread") bcomment = data.get("bcomment") if bread>=bcomment: return data raise serializers.ValidationError("阅读量小于评论量,数据太假了")

选项参数:
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最小值 |
| min_value | 最大值 |
通用参数:
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text |
5)创建响应视图图
############################################# # 1. 序列化器的序列化阶段使用 ############################################# from django.http import JsonResponse from django.views import View from booktest.models import BookInfo # 导入序列化器类 from .serializers import BookInfo2Serializer class BookInfoView(View): def get(self,request): # 操作数据库 books = BookInfo.objects.all() # 创建序列化器对象 # 参数1: instance=要序列化的模型数据 # 参数2: data=要反序列化器的字典数据 # 参数3: many= 是否要序列化多个模型数据,多条数据many=True,默认一条数据 # 参数4: context=序列化器使用的上下文,字典类型数据,可以通过context把视图中的数据,传递给序列化器内部使用 serializer = BookInfo2Serializer(instance=books,many=True) # 通过 serializer.data 获取序列化完成以后的数据 print ( serializer.data ) # 返回数据 return JsonResponse(serializer.data,safe=False) ############################################################################################################################### # 2 序列化器的反序列化阶段使用 # 主要用户验证数据和字典数据转换成模型 # 为了保证测试顺利进行,我们在settings.py中关闭 csrf的中间件 # 'django.middleware.csrf.CsrfViewMiddleware', ############################################# from django.views import View from django.http import JsonResponse from django.http import QueryDict from .serializers import BookInfo2Serializer class BookInfo2View(View): def post(self,request): """添加一本图书""" # 接受数据 data = request.POST # 反序列化 serializer = BookInfo2Serializer(data=data) # 1. 验证数据 # raise_exception=True 把验证的错误信息返回给客户端,同时阻止程序继续往下执行 serializer.is_valid(raise_exception=True) # is_valid调用验证方式: 字段选项validators->自定义验证方法[单字段]->自定义验证方法[多字段] # 验证成功后的数据 # print(serializer.validated_data) # 2. 转换数据成模型,同步到数据库中 result = serializer.save() # save会自动调用序列化器类里面声明的create/update方法,返回值是当前新增/更新的模型对象 # 响应数据 return JsonResponse(serializer.data) def put(self,request,pk): """更新一个图书""" # 根据id主键获取指定图书信息 book = BookInfo.objects.get(pk=pk) # 接受到客户端提交过来的数据 # data = { # "btitle":"西厢记外传", # "bpub_date":"1998-10-10", # "bread":"100", # "bcomment":"50" # } # 获取put数据 data = QueryDict(request.body) # 使用序列化器完成验证和反序列化过程 # partial=True 接下里在反序列化中允许部分数据更新 serializer = BookInfo2Serializer(instance=book,data=data,partial=True) serializer.is_valid(raise_exception=True) # save之所以可以自动识别,什么时候执行create ,什么时候执行update # 主要是看创建序列化器对象时,是否有传入instance参数, # 有instance参数,则save会调用序列化器内部的update方法 # 没有instance参数,则save会调用序列化器内部的create方法 serializer.save() # 响应数据 return JsonResponse(serializer.data) ############################################# # 3 模型序列化器 # 1. 可以帮我们自动完成字段的声明[主要是从模型中的字段声明里面提取过来] # 2. 模型序列化器也可以帮我们声明了create和update方法的代码 ############################################# from django.views import View from django.http import JsonResponse from .serializers import BookInfoModelSerializer class BookInfo3View(View): def post(self,request): """添加一本图书""" # 接受数据 data = request.POST # 反序列化 serializer = BookInfoModelSerializer(data=data) serializer.is_valid(raise_exception=True) result = serializer.save() # 响应数据 return JsonResponse(serializer.data) def put(self,request,pk): """更新一个图书""" book = BookInfo.objects.get(pk=pk) # 获取put提交的数据 data = QueryDict(request.body) serializer = BookInfoModelSerializer(instance=book,data=data,partial=True) serializer.is_valid(raise_exception=True) serializer.save() # 响应数据 return JsonResponse(serializer.data)
serializers的总结:
Serializer(instance=None, data=empty, **kwarg)
说明:
1)用于序列化时,将模型类对象传入instance参数
2)用于反序列化时,将要被反序列化的数据传入data参数
3)除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据,如
serializer = AccountSerializer(account, context={'request': request})
通过context参数附加的数据,可以通过Serializer对象的context属性获取。
-
使用序列化器的时候一定要注意,序列化器声明了以后,不会自动执行,需要我们在视图中进行调用才可以。
-
序列化器无法直接接收数据,需要我们在视图中创建序列化器对象时把使用的数据传递过来。
-
序列化器的字段声明类似于我们前面使用过的表单系统。
-
开发restful api时,序列化器会帮我们把模型数据转换成字典.
-
drf提供的视图会帮我们把字典转换成json,或者把客户端发送过来的数据转换字典.
1 序列化器的使用
序列化器的使用分两个阶段:
-
在客户端请求时,使用序列化器可以完成对数据的反序列化。
-
在服务器响应时,使用序列化器可以完成对数据的序列化。
2 序列化
基本使用
1) 先查询出一个图书对象
from booktest.models import BookInfo
book = BookInfo.objects.get(id=2)
2) 构造序列化器对象
from booktest.serializers import BookInfoSerializer
serializer = BookInfoSerializer(book)
3)获取序列化数据
通过data属性可以获取序列化后的数据
serializer.data
# {'id': 2, 'btitle': '天龙八部', 'bpub_date': '1986-07-24', 'bread': 36, 'bcomment': 40, 'image': None}
4)如果要被序列化的是包含多条数据的查询集QuerySet,可以通过添加many=True参数补充说明
book_qs = BookInfo.objects.all()
serializer = BookInfoSerializer(book_qs, many=True)
serializer.data
# [OrderedDict([('id', 2), ('btitle', '天龙八部'), ('bpub_date', '1986-07-24'), ('bread', 36), ('bcomment', 40), ('image', N]), OrderedDict([('id', 3), ('btitle', '笑傲江湖'), ('bpub_date', '1995-12-24'), ('bread', 20), ('bcomment', 80), ('image'ne)]), OrderedDict([('id', 4), ('btitle', '雪山飞狐'), ('bpub_date', '1987-11-11'), ('bread', 58), ('bcomment', 24), ('ima None)]), OrderedDict([('id', 5), ('btitle', '西游记'), ('bpub_date', '1988-01-01'), ('bread', 10), ('bcomment', 10), ('im', 'booktest/xiyouji.png')])]
3反序列化
数据验证
使用序列化器进行反序列化时,需要对数据进行验证后,才能获取验证成功的数据或保存成模型类对象。
在获取反序列化的数据前,必须调用is_valid()方法进行验证,验证成功返回True,否则返回False。
验证失败,可以通过序列化器对象的errors属性获取错误信息,返回字典,包含了字段和字段的错误。如果是非字段错误,可以通过修改REST framework配置中的NON_FIELD_ERRORS_KEY来控制错误字典中的键名。
验证成功,可以通过序列化器对象的validated_data属性获取数据。
在定义序列化器时,指明每个字段的序列化类型和选项参数,本身就是一种验证行为。
如我们前面定义过的BookInfoSerializer
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20)
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
image = serializers.ImageField(label='图片', required=False)
通过构造序列化器对象,并将要反序列化的数据传递给data构造参数,进而进行验证
from booktest.serializers import BookInfoSerializer
data = {'bpub_date': 123}
serializer = BookInfoSerializer(data=data)
serializer.is_valid() # 返回False
serializer.errors
# {'btitle': [ErrorDetail(string='This field is required.', code='required')], 'bpub_date': [ErrorDetail(string='Date has wrong format. Use one of these formats instead: YYYY[-MM[-DD]].', code='invalid')]}
serializer.validated_data # {}
data = {'btitle': 'python'}
serializer = BookInfoSerializer(data=data)
serializer.is_valid() # True
serializer.errors # {}
serializer.validated_data # OrderedDict([('btitle', 'python')])
is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
# Return a 400 response if the data was invalid.
serializer.is_valid(raise_exception=True)
如果觉得这些还不够,需要再补充定义验证行为,可以使用以下三种方法:
1) validate_字段名
对<field_name>字段进行验证,如
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
...
def validate_btitle(self, value):
if 'django' not in value.lower():
raise serializers.ValidationError("图书不是关于Django的")
return value
测试
from booktest.serializers import BookInfoSerializer
data = {'btitle': 'python'}
serializer = BookInfoSerializer(data=data)
serializer.is_valid() # False
serializer.errors
# {'btitle': [ErrorDetail(string='图书不是关于Django的', code='invalid')]}
2) validate
在序列化器中需要同时对多个字段进行比较验证时,可以定义validate方法来验证,如
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
...
def validate(self, attrs):
bread = attrs['bread']
bcomment = attrs['bcomment']
if bread < bcomment:
raise serializers.ValidationError('阅读量小于评论量')
return attrs
测试
from booktest.serializers import BookInfoSerializer
data = {'btitle': 'about django', 'bread': 10, 'bcomment': 20}
s = BookInfoSerializer(data=data)
s.is_valid() # False
s.errors
# {'non_field_errors': [ErrorDetail(string='阅读量小于评论量', code='invalid')]}
3) validators
在字段中添加validators选项参数,也可以补充验证行为,如
def about_django(value):
if 'django' not in value.lower():
raise serializers.ValidationError("图书不是关于Django的")
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名称', max_length=20, validators=[about_django])
bpub_date = serializers.DateField(label='发布日期', required=False)
bread = serializers.IntegerField(label='阅读量', required=False)
bcomment = serializers.IntegerField(label='评论量', required=False)
image = serializers.ImageField(label='图片', required=False)
测试:
from booktest.serializers import BookInfoSerializer
data = {'btitle': 'python'}
serializer = BookInfoSerializer(data=data)
serializer.is_valid() # False
serializer.errors
# {'btitle': [ErrorDetail(string='图书不是关于Django的', code='invalid')]}
4 反序列化-保存数据
前面的验证数据成功后,我们可以使用序列化器来完成数据反序列化的过程.这个过程可以把数据转成模型类对象.
可以通过实现create()和update()两个方法来实现。
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
...
def create(self, validated_data):
"""新建"""
return BookInfo(**validated_data)
def update(self, instance, validated_data):
"""更新,instance为要更新的对象实例"""
instance.btitle = validated_data.get('btitle', instance.btitle)
instance.bpub_date = validated_data.get('bpub_date', instance.bpub_date)
instance.bread = validated_data.get('bread', instance.bread)
instance.bcomment = validated_data.get('bcomment', instance.bcomment)
return instance
如果需要在返回数据对象的时候,也将数据保存到数据库中,则可以进行如下修改
class BookInfoSerializer(serializers.Serializer):
"""图书数据序列化器"""
...
def create(self, validated_data):
"""新建"""
return BookInfo.objects.create(**validated_data)
def update(self, instance, validated_data):
"""更新,instance为要更新的对象实例"""
instance.btitle = validated_data.get('btitle', instance.btitle)
instance.bpub_date = validated_data.get('bpub_date', instance.bpub_date)
instance.bread = validated_data.get('bread', instance.bread)
instance.bcomment = validated_data.get('bcomment', instance.bcomment)
instance.save()
return instance
实现了上述两个方法后,在反序列化数据的时候,就可以通过save()方法返回一个数据对象实例了
book = serializer.save()
如果创建序列化器对象的时候,没有传递instance实例,则调用save()方法的时候,create()被调用,相反,如果传递了instance实例,则调用save()方法的时候,update()被调用。
from db.serializers import BookInfoSerializer
data = {'btitle': '封神演义'}
serializer = BookInfoSerializer(data=data)
serializer.is_valid() # True
serializer.save() # <BookInfo: 封神演义>
from db.models import BookInfo
book = BookInfo.objects.get(id=2)
data = {'btitle': '倚天剑'}
serializer = BookInfoSerializer(book, data=data)
serializer.is_valid() # True
serializer.save() # <BookInfo: 倚天剑>
book.btitle # '倚天剑'
5 附加说明
1) 在对序列化器进行save()保存时,可以额外传递数据,这些数据可以在create()和update()中的validated_data参数获取到
# request.user 是django中记录当前登录用户的模型对象
serializer.save(owner=request.user)
2)默认序列化器必须传递所有required的字段,否则会抛出验证异常。但是我们可以使用partial参数来允许部分字段更新
# Update `comment` with partial data
serializer = CommentSerializer(comment, data={'content': u'foo bar'}, partial=True)
6 模型类序列化器
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。
ModelSerializer与常规的Serializer相同,但提供了:
-
基于模型类自动生成一系列字段
-
基于模型类自动为Serializer生成validators,比如unique_together
-
包含默认的create()和update()的实现
7 定义
比如我们创建一个BookInfoSerializer
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = '__all__'
-
model 指明参照哪个模型类
-
fields 指明为模型类的哪些字段生成
我们可以在python manage.py shell中查看自动生成的BookInfoSerializer的具体实现
>>> from booktest.serializers import BookInfoSerializer
>>> serializer = BookInfoSerializer()
>>> serializer
BookInfoSerializer():
id = IntegerField(label='ID', read_only=True)
btitle = CharField(label='名称', max_length=20)
bpub_date = DateField(allow_null=True, label='发布日期', required=False)
bread = IntegerField(label='阅读量', max_value=2147483647, min_value=-2147483648, required=False)
bcomment = IntegerField(label='评论量', max_value=2147483647, min_value=-2147483648, required=False)
image = ImageField(allow_null=True, label='图片', max_length=100, required=False)
8 指定字段
1) 使用fields来明确字段,__all__表名包含所有字段,也可以写明具体哪些字段,如
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date')
2) 使用exclude可以明确排除掉哪些字段
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
exclude = ('image',)
3) 显示指明字段,如:
class HeroInfoSerializer(serializers.ModelSerializer):
hbook = BookInfoSerializer()
class Meta:
model = HeroInfo
fields = ('id', 'hname', 'hgender', 'hcomment', 'hbook')
4) 指明只读字段
可以通过read_only_fields指明只读字段,即仅用于序列化输出的字段
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
read_only_fields = ('id', 'bread', 'bcomment')
9 添加额外参数
我们可以使用extra_kwargs
class BookInfoSerializer(serializers.ModelSerializer):
"""图书数据序列化器"""
class Meta:
model = BookInfo
fields = ('id', 'btitle', 'bpub_date', 'bread', 'bcomment')
extra_kwargs = {
'bread': {'min_value': 0, 'required': True},
'bcomment': {'min_value': 0, 'required': True},
}
# BookInfoSerializer():
# id = IntegerField(label='ID', read_only=True)
# btitle = CharField(label='名称', max_length=20)
# bpub_date = DateField(allow_null=True, label='发布日期', required=False)
# bread = IntegerField(label='阅读量', max_value=2147483647, min_value=0, required=True)
# bcomment = IntegerField(label='评论量', max_value=2147483647, min_value=0, required=True)
---恢复内容结束---