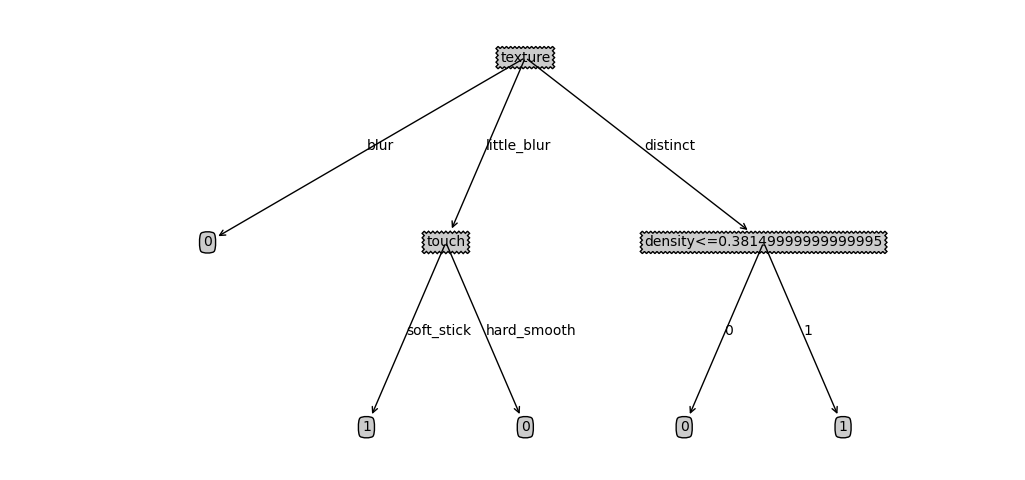
建立决策树
import numpy as np
import pandas as pd
import operator
from PlotTree import createPlot #调用绘图子程序
#计算数据集dataSe香农熵
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel=featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1
shannonEnt=0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt-=prob*np.log2(prob)
return shannonEnt
#求离散属性取某一值时数据集
def splitDataSet(dataSet,axis,value):
subDataSet=[]
for example in dataSet:
reducedExample = []
if example[axis] == value:
reducedExample = example[:axis]
reducedExample.extend(example[axis+1:])
subDataSet.append(reducedExample)
return subDataSet
#分割连续数据集,根据direction参数确定方向
def splitContinuousDataSet(dataSet,axis,value,direction):
reDataSet = []
for example in dataSet:
subDataSet=[]
if direction == 1:
if example[axis] <= value:
subDataSet = example[:axis]
subDataSet.extend(example[axis+1:])
reDataSet.append(subDataSet)
else:
if example[axis] > value:
subDataSet = example[:axis]
subDataSet.extend(example[axis+1:])
reDataSet.append(subDataSet)
return reDataSet
#求最佳划分属性
bestSplitDict={}
def chooseBestFeatureToSplit(dataSet,labels):
baseEntorpy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(len(labels)):
featureList = [example[i] for example in dataSet]
if type(featureList[0]).__name__ == 'float' or type(featureList[0]).__name__ == 'int':
sortedFeatureList = sorted(featureList)
splitList = []
for j in range(len(sortedFeatureList)-1):
splitList.append((sortedFeatureList[j]+sortedFeatureList[j+1])/2.0)
bestCotinuEnt = 10000
bestSplit = 0
#print(splitList,end='
')
for j in range(len(splitList)):
featureEnt = 0.0
#print(dataSet,end='
')
dataSet1=splitContinuousDataSet(dataSet,i,splitList[j],1)
#print(dataSet1,end='
')
prob1 = len(dataSet1)/float(len(dataSet))
featureEnt += prob1*calcShannonEnt(dataSet1)
dataSet0=splitContinuousDataSet(dataSet,i,splitList[j],0)
prob0 = len(dataSet0)/float(len(dataSet))
featureEnt += prob0*calcShannonEnt(dataSet0)
if featureEnt < bestCotinuEnt:
bestCotinuEnt = featureEnt
bestSplit = splitList[j]
bestSplitDict[labels[i]] = bestSplit
infoGain = baseEntorpy - bestCotinuEnt
#对于连续属性求信息熵
else:
uniqueValue = set(featureList)
featureEnt = 0.0
for value in uniqueValue:
subDataSet = splitDataSet(dataSet,i,value)
prob= len(subDataSet)/float(len(dataSet))
featureEnt += prob*calcShannonEnt(subDataSet)
infoGain = baseEntorpy - featureEnt
#
if infoGain > bestInfoGain:
bestFeature = i
bestInfoGain = infoGain
#若最佳划分属性为连续值,将其以划分点为界,进行二至处理
if type(dataSet[0][bestFeature]).__name__ == 'float' or
type(dataSet[0][bestFeature]).__name__ == 'int':
bestSplitValue = bestSplitDict[labels[bestFeature]]
#labels[bestFeature] = labels[bestFeature] + '<=' + str(bestSplitValue)
for i in range(len(dataSet)):
if dataSet[i][bestFeature] <= bestSplitValue:
dataSet[i][bestFeature] = 1
else:
dataSet[i][bestFeature] = 0
return bestFeature
#当不能划分时,投票选出分类
def majorityCnt(classList):
classCount={}
for i in classList:
if i not in classCount.keys():
classCount[i]=0
classCount[i]+=1
return max(classCount,key=classCount.get)
#生成决策树
def createTree(dataSet,labels,data_full,labels_full):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeature = chooseBestFeatureToSplit(dataSet,labels)
bestFeatureLabel = labels[bestFeature]
myTree = {bestFeatureLabel:{}}
featureVals = [example[bestFeature] for example in dataSet]
uniqueVals = set(featureVals)
if type(dataSet[0][bestFeature]).__name__ == 'str':
currentLabel = labels_full.index(labels[bestFeature])
featureVals_full = [example[currentLabel] for example in data_full]
uniqueVals_full = set(featureVals_full)
else:
bestSplitValue = bestSplitDict[labels[bestFeature]]
bestFeatureLabel = labels[bestFeature] + '<=' + str(bestSplitValue)
myTree = {bestFeatureLabel:{}}
del(labels[bestFeature])
for value in uniqueVals:
sublabels = labels[:]
if type(dataSet[0][bestFeature]).__name__ == 'str':
uniqueVals_full.remove(value)
myTree[bestFeatureLabel][value] = createTree(splitDataSet
(dataSet,bestFeature,value), sublabels,data_full,labels_full)
if type(dataSet[0][bestFeature]) == 'str':
for val in uniqueVals_full:
myTree[bestFeatureLabel][val] = majorityCnt(classList)
return myTree
#main function
df = pd.read_csv('WaterMelon_4_3.txt',sep=' ')
data_full = df.values[:,1:].tolist()
dataSet = data_full[:]
labels_full = df.columns[1:-1].tolist()
labels = labels_full[:]
myTree = createTree(dataSet,labels,data_full,labels_full)
createPlot(myTree)
参考:
ID3决策树
绘图子程序
python绘制决策树
效果