1 为什么使用消息队列?
六个字: 解耦、异步、消峰。
2 使用消息队列有什么缺点?
消息队列挂了,系统就不能用了,系统可用性降低。
3 消息队列的高可用?
kafka使用zookeeper,master/slave,保证高可用;
Kafka通过Zookeeper管理集群配置,选举leader,以及在Consumer Group发生变化时进行rebalance
4 如何保证消息不被重复消费(幂等性)?
kafka有offset的概念,就是每一个消息都有一个offset,kafka消费过消息后,需要提交offset,让消息队列知道自己已经消费过了;
造成重复消费的原因:因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将该消息分发给其他的消费者。如何避免:
- insert操作,主键唯一性可以保证。
- update, 不会有问题。
- 其他情况下,可以用第三方工具做消费记录(比如redis),给消息分配全局ID。将<id,message>以K-V形式写入redis。消费前,先去redis中查询有没有消费记录。
5 如何保证消费的可靠性传输?
我们在使用消息队列的过程中,应该做到消息不能多消费,也不能少消费。
其实这个可靠性传输,每种MQ都要从三个角度来分析:生产者弄丢数据、消息队列弄丢数据、消费者弄丢数据
(1)生产者弄丢数据:
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication Factor为多少(也即该Partition有 多少个Replica),Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader中pull数据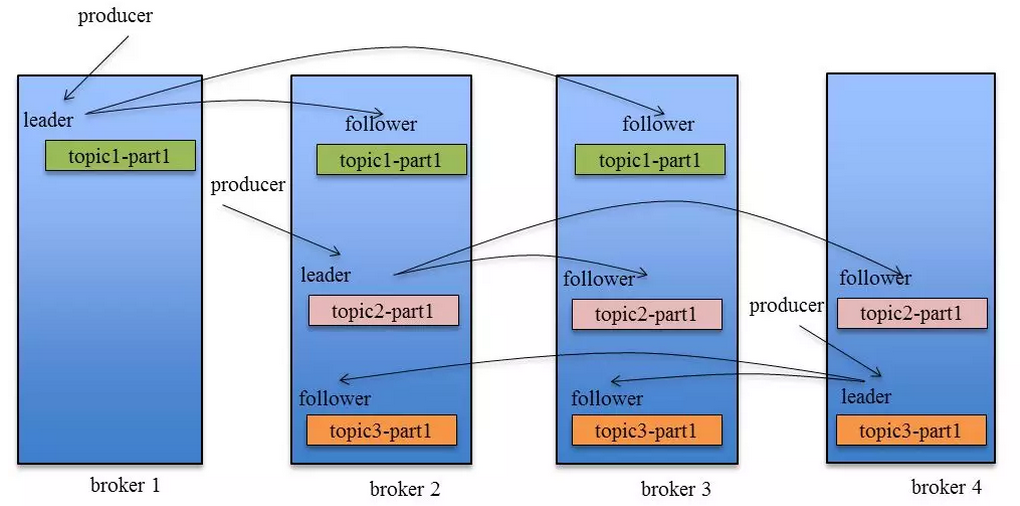
在kafka生产中,基本都有一个leader和多个follwer。follwer会去同步leader的信息。
因此,为了避免生产者丢数据,做如下两点配置:
1. 第一个配置要在producer端设置acks=all。这个配置保证了,follwer同步完成后,才认为消息发送成功。
2. 在producer端设置retries=MAX,一旦写入失败,这无限重试;
(2) 消息队列丢数据:
针对消息队列丢数据的情况,无外乎就是,数据还没同步,leader就挂了,这时zookpeer会将其他的follwer切换为leader,那数据就丢失了。针对这种情况,应 该做两个配置。
1. replication.factor参数,这个值必须大于1,即要求每个partition必须有至少2个副本
2. min.insync.replicas参数,这个值必须大于1,这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系
这两个配置加上上面生产者的配置联合起来用,基本可确保kafka不丢数据。
(3)消费者弄丢数据:消费者丢数据一般是因为采用了自动确认消息模式,至于解决方案,采用手动确认消息即可。
6 如何保证消息的顺序性?
针对这个问题,通过某种算法,将需要保持先后顺序的消息放到同一个消息队列中(kafka中就是partition,rabbitMq中就是queue)。然后只用一个消费者去消费该队列(kafka中,一个partition只能被一个consumer Group中的一个consumer消费)。