Apache Kafka 消息怎么写?
kafka是一个分布式的流消息队列
生产者将消息发布到某个主题
broker 进行存储
消费者 订阅+读数据 从该主题中
消息(记录)以序列化字节存储,
消费者负责反序列化消息,
消息可以具有任何格式,最常见的是字符串,JSON和Avro。
JSON 格式的好处与坏处!? √
1.消息始终具有键值结构,键或值可以为null。
当键为null时,将使用循环分发来分发消息。
如何根据 自定义设定 key 来保证全局局部有序!? √
比如说现在有两条消息,一个是支付消息,一个是发货消息,如果这两个消息的key是一样的,
比如是同一个订单id就可以让这两条消息都走同一个partition,保证消息消费的顺序
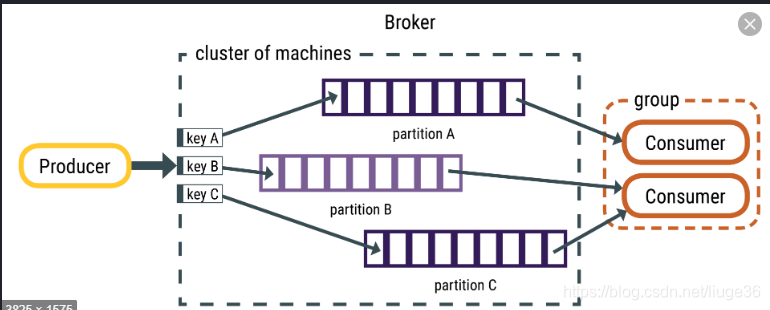
2.主题分区包含一组有序的消息,并且分区中的每个消息都有唯一的偏移量。
0.8 kafka 需要自定义管理offset,这里可以存储在hdfs,zk,mysql...!? √
0.10+ 不需要
默认情况下,Kafka将数据保留7天。
重点场景 mysql的数据–>通过canal–>发送到kafka–>mysql、hive
在做canal集成kafka的时候,发现一个问题,多分区的情况下,跨分区的数据消费是无序的。
这时候就会出现问题,如果消费端消费的更新日志在插入日志之前,就会因为数据缺失导致异常(这
样的情况随着并发出现的概率会增大),所以,需要保证新增的日志和更新的日志是有序的被消费。
kafka发送数据是支持指定分区的,这时候,只要把同一个表的同一个主键的数据发到同一个分区即
可(如果多数据库得加入数据库名)
分区定义如下:
private int partitionDefine(String keyToPartition) {
if (keyToPartition == null) {
return new Random().nextInt(numPartitions);
} else {
return Math.abs(keyToPartition.hashCode()) % numPartitions;
}
}
传入的参数 tableName+主键
这样,消费到的数据就是有序的。不同的场景灵活运用即可。