原文链接:https://www.sdnlab.com/20901.html
1.问题定义
ovs-dpdk datapath classifier是ovs-dpdk实现快速转发的核心功能模块。本文主要分析该模块的具体实现细节。
本文所述的流程,对应源码中各函数的调用层次关系如下图所示。这些函数调用层次的说明,可以参考链接:https://software.intel.com/en-us/articles/ovs-dpdk-datapath-classifier-part-2,这里不重点介绍。
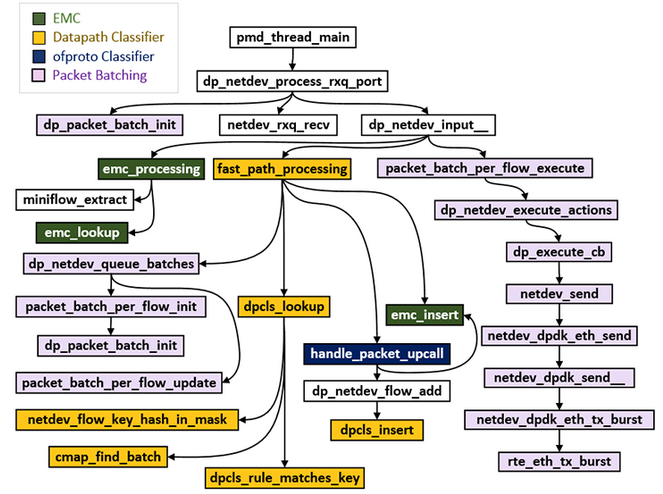
上图展示的是流表的匹配及更新(主要是新增)过程中函数调用层次。对于涉及EMC、DPCLS表项的删除过程对应的函数调用层次,如下两个图所示。
1)EMC表项删除

2)DPCLS表项删除

2.设计考虑
2.1.miniflow
dpdk网卡接收到的报文通常都包含几百字节大小,且在匹配流表的过程中并非使用报文的所有字段去比较匹配,通常只是使用部分字段。因此,ovs-dpdk中专门设计了一个巧妙的数据结构来缓存报文中需要匹配的字段信息,以此来提高匹配的效率。在ovs-dpdk中,相关的数据结构有struct netdev_flow_key、struct miniflow、struct flowmap、struct flow。这些结构个成员的意义如下所示。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
struct netdev_flow_key {
/* 根据报文5元组(源IP、目的IP、协议号、源端口、目的端口) 计算出的Hash值*/
uint32_t hash;
/* len = sizeof(mf) + buf中实际存储的字节数 */
uint32_t len;
/* 报文对应的miniflow信息 */
struct miniflow mf;
/* 报文具体匹配字段的数据值 */
uint64_t buf[FLOW_MAX_PACKET_U64S];
}
struct miniflow {
struct flowmap map;
}
struct flowmap {
/* 见下面解释 */
unsigned long long bits[FLOWMAP_UINTS];
}
|
对于FLOW_MAX_PACKET_U64S宏值,我们暂且不关心它具体有多大。而对于FLOWMAP_UINTS宏值,首先需要了解struct flowmap结构中的bits数组与struct flow结构之间的关系:bits数组中的每一个元素值,如bits[0]一共有64比特,当其某个比特位置1时,表示对应的struct flow结构中某个字段值有效。而这个有效值是存储在net_dev_flow_key结构中的buf中。struct flow大小有552字节,这样FLOWMAP_UINTS的计算方法如下:
1)确定struct flow有多少个8字节单元
units = sizeof(struct flow)/8=552/8=69
2)从上面1)计算出units=69。表明需要使用69个比特来表达这69个单元的数据是否有效。因此FLOWMAP_UINTS=units/sizeof(bits[0])=69/64,向上取整,最终结果为2,表明至少需要128比特才能完整表达这69个单元的数据有效性。
为了掌握netdev_flow_key 结构中的miniflow、buf和flow结构之间的关系,主要以flow结构中存储报文的五元组,即:源IP、目的IP、源端口、目的端口作为示例,来掌握这些信息如何在接收到的报文中提取到miniflow和buf中存储,以及如何从miniflow和buf中恢复这些信息到flow结构中。如下所示。
1)报文信息提取
报文五元组在struct flow结构中的偏移地址(相对0地址)如下表所示(给出的偏移值可能与实际的偏移值不相同,这里只是给出一个示例说明)。
|
报文成员 |
偏移地址/8 |
|
nw_src |
30 |
|
nw_dst |
30 |
|
nw_proto |
35 |
|
tp_src |
40 |
|
tp_dst |
40 |
根据上面五元组信息的偏移信息,flowmap结构中的bits数组相应的值更新为如下:
bits[0]共64比特,对应的各个比特值如下表(从上到下,从左到右,按照bit0到bit63的顺序存储)所示。
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
bits[1] = 全0;
bits数组中相应的比特位置1之后,只是标识flow结构中对应的五元组信息有效。而五元组的具体信息值是多少,是存储在netdev_flow_key结构中的buf数组中。具体如下所示:
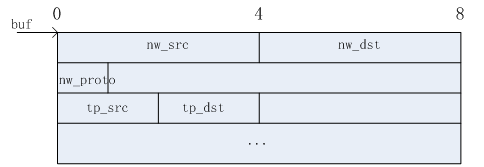
这样,报文中的五元组信息就成功提取完毕。
2)报文信息构造
报文在接收到之后,通过压缩,存储在netdev_flow_key结构中。在匹配的过程中,还需要从这个结构中恢复(读取)报文的具体信息。同样以报文的五元组信息为例,下面描述如何从netdev_flow_key结构中恢复出报文的五元组信息,并存储在flow结构中。
- 提取nw_src和nw_dst
根据前面偏移量的计算结果得知,nw_src和nw_dst在flow结构中偏移量都是30,而bits[30]已经置1了,表明nw_src和nw_dst信息有效。提取之前,检查bits[30]之前(不含bit30)置1的个数为0,则表明nw_src和nw_dst信息是存储在buf首地址,直接提取uint64_t data = *buf。提取出64位的data之后再分别取出nw_src = data & 0xffffffff, nw_dst = (data >>32) & 0xffffffff。 - 提取nw_proto
根据前面偏移量的计算结果得知,nw_proto在flow结构中的偏移量为35,而bits[35]已经置1了,表明nw_proto信息有效。提取之前,检查bits[35]之前置1的个数为1,即:只有bits[30]置1了,则表明nw_proto = (*(buf+1)) & 0xff。 - 提取tp_src和tp_dst
根据前面偏移量的计算结果得知,tp_src和tp_dst在flow结构中的偏移量都为40,而bits[40]已经置1了,表明tp_src和tp_dst信息有效。提取之前,检查bits[40]之前置1的个数为2,则表明tp_src和tp_dst信息值为uint64_t data = *(buf+2)。tp_src = data & 0xffffffff, tp_dst = (data >>32) & 0xffffffff。
根据前面三个实例可知,要提取报文的某个字段信息值,首先要计算出该字段在flow结构中的偏移量(8字节为单位),假设为offset,然后再检查bits[offset]是否已经置1,如果置1了表明该字段信息有效,可以进行提取。提取之前,确认bits[offset]之前置1的个数(不含offset这个位置),假设为n,则提取的数据为uint64_t data = *(buf + n)。提取出的data为64位的数值,需要再根据报文的字段大小进行计算,得出该字段的具体值。
2.2.三级流表
ovs-dpdk设计中采用的是三级流表的匹配过程。至于为什么要这样设计三级流表,这里暂时不给出原因。这三级流表的匹配过程总体流程如下图所示。

从上图可知,这三级流表分别是EMC -> DataPath Classifier(DPCLS) -> ofproto Classifier(OFPROTO)。下面将针对这三级流表如何匹配、如何更新表项作详细地描述。
2.2.1.EMC
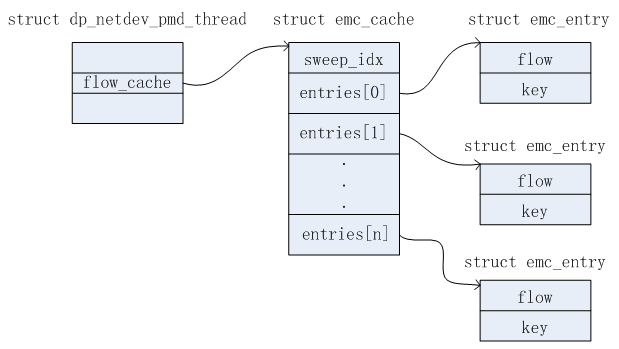
在描述这级流表之前,先给出相关的数据结构。在ovs-dpdk源码中,涉及的相关数据结构主要有如下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
#define EM_FLOW_HASH_SHIFT 13
#define EM_FLOW_HASH_ENTRIES (1 << EM_FLOW_HASH_SHIFT)
#define EM_FLOW_HASH_MASK (EM_FLOW_HASH_ENTRIES - 1)
#define EM_FLOW_HASH_SEGS 2
struct emc_cache {
/* EMC表项,总数为EM_FLOW_HASH_ENTRIES=1 << 13,即: 8192个表项 */
struct emc_entry[EM_FLOW_HASH_ENTRIES];
int sweep_idx;
}
struct emc_entry {
/* 表示一条流表项.立面包含了匹配域及对应的Actions */
struct dp_netdev_flow *flow;
/* 匹配EMC表项的关键字 */
struct netdev_flow_key key;
}
|
这个EMC表项对于每个DPDK PMD线程都有一个。在pmd线程数据结构中dp_netdev_pmd_thread,有一个名称为flow_cache的成员指向了对应的emc表项。这些数据结构的关系如下图所示。
2.2.1.1.查找过程
根据接收的报文计算netdev_flow_key信息
首先从dpdk网卡接收到报文,将报文的信息进行压缩,存储在netdev_flow_key结构中的miniflow和buf中。这个过程见2.1节,这里不再赘述。完成报文信息压缩之后,需要计算netdev_flow_key结构中的hash值,这个hash是根据报文中的五元组,即:源IP、目的IP、协议号、源端口、目的端口计算出来的。具体使用什么样的hash算法,怎样计算,这里不给出细节。假设这一步得出的结果保存在struct netdev_flow_key key变量中。
查找emc_entry
根据上一步计算出的key.hash值,遍历所有的emc_entry,命中的条件如下:
1)emc_entry中的key.hash与计算出的hash值相等。
2)emc_entry.flow->dead为false,表明该流表项仍然保活着。
3)key.mf和emc_entry.key.mf完全相同。
同时满足上述3个条件,则表明命中一条EMC表项,结果为Match。否则在EMC匹配过程中,结果为Miss。
需要注意的是:上一步中计算出的key.hash值是32比特,而emc_cache中一共只有1<<13=8192个表项。因此匹配的过程需要分两段,这也就是在2.2.1节中,宏值EM_FLOW_HASH_SEGS为2的原因。第一段的hash1=key.hash & EM_FLOW_HASH_MASK。第二段的hash2 = (key.hash >> EM_FLOW_HASH_SHIFT) & EM_FLOW_HASH_MASK。这样在查找的过程中,只要在某段中匹配成功,则无需继续下一段的匹配。
处理匹配结果
如果在上一步中,结果为Match,则返回emc_entry.flow所指向的流表项。用于后续执行对应的Actions。这个过程请参考下面2.3节。
如果在上一步中,结果为Miss,则将报文上送给DPCLS继续执行匹配流程。这个过程请参考下面2.2.2节。
2.2.1.2.更新过程
在上一步EMC查找过程中,如果查找结果为Miss,则会将报文上送给DPCLS继续做匹配流程。如果在这级流表中匹配成功了,则需要根据匹配的结果,更新EMC表项。即:插入一个新的EMC表项。更新的过程如下:
找到合适的entry用于存储新表项
怎样才算是合适的entry,判断的标准如下:
1)使用第一段的hash1找到emc_entry,如果对应的emc_entry.flow->dead为true,即:该表项非alive,则认为这个emc_entry是合适的。查找结束。
2)如果第一段的hash1找到的emc_entry.flow->dead为false,即:该表项还是alive,则继续使用第二段的hash2查找。如果找到的emc_entry.flow->dead为true,即:该表项非alive,则认为这个emc_entry是合适的。查找结束。
3)假设在1)中使用第一段hash1找到的表项为emc_entry1,在2)中使用第二段hash2找到的表项为emc_entry2。且这两个表项都是alive的,则通过对比二者的hash值,即:emc_entry1.key.hash和emc_entry2.key.hash,选择其hash值较小的表项作为合适的表项。
更新表项
假设根据上一步,找到了合适的emc_entry。则将报文对应的netdev_dev_flow key信息存储到该表项中。而对于这个表项,原有的emc_entry.flow有可能还有指向一条旧的流表,需要将这条流表的引用计数减1,如果减1后达到0,则释放该流表空间。同时更新emc_entry.flow重新指向新的流表。到此为止,EMC表项更新完毕。
2.2.1.3.删除过程
pmd_thread_main函数是dpdk pmd线程的主函数,里面存在一个无条件for循环,每隔一定的时间去调用emc_cache_slow_sweep(当然并非是无条件地去调用,而是通过相关的信号检查,这点不重点介绍,暂时没细看)。
在emc_cache_slow_sweep函数中,判断某个emc_entry存储的flow是否非alive,即:检查emc_entry.flow->dead是否为true。如果为true,则表明该流信息已经无效。这里读取出emc_entry.flow->dead为true,这个是在dpcls删除表项的过程中设置的,具体细节请参考如下2.2.2.3节。此时需要将emc_entry.flow置为NULL,不再引用之前的流信息了,因为流信息在dpcls删除表项过程中最终会释放其内存空间,如果这里的emc_entry.flow继续引用的话,则会存在野指针的bug。
EMC表项固定一共有8192个表项。将对应entry中的flow成员置NULL就完成了其表项的删除过程。
2.2.2.DPCLS
在描述这级流表之前,先给出相关的数据结构。在ovs-dpdk源码中,涉及的相关数据结构主要有如下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
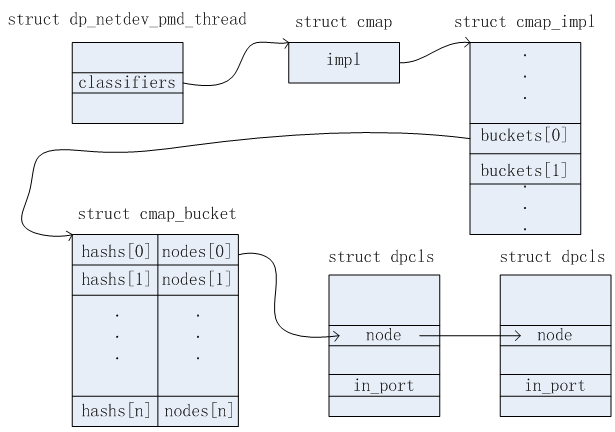
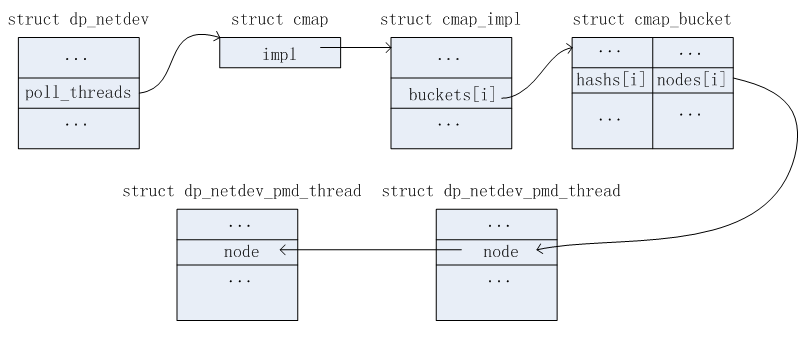
struct cmap {
struct cmap_impl *impl;
}
struct cmap_node {
struct cmap_node *next;
}
struct cmap_impl {
unsigned int n; /* Number of in-use elements */
unsigned int max_n; /* Max elements before enlarging */
unsigned int min_n; /* Min elements before shrinking */
uint32_t mask; /* Number of buckets -1 */
uint32_t basis; /* Basis for rehashing client’s hash values */
uint8_t pad[64-4*5]; /* Pad to 64bit */
struct cmap_bucket buckets[1]; /* 有可能不止1个 */
}
struct cmap_bucket {
atomic_uint32_t counter;
/* 桶,桶中的每个槽用(hashs[i],nodes[i] )元组来表示 */
uint32_t hashs[CMAP_K];
struct cmap_node nodes[CMAP_K];
}
/* 二级匹配表.每个报文接收端口对应一个 */
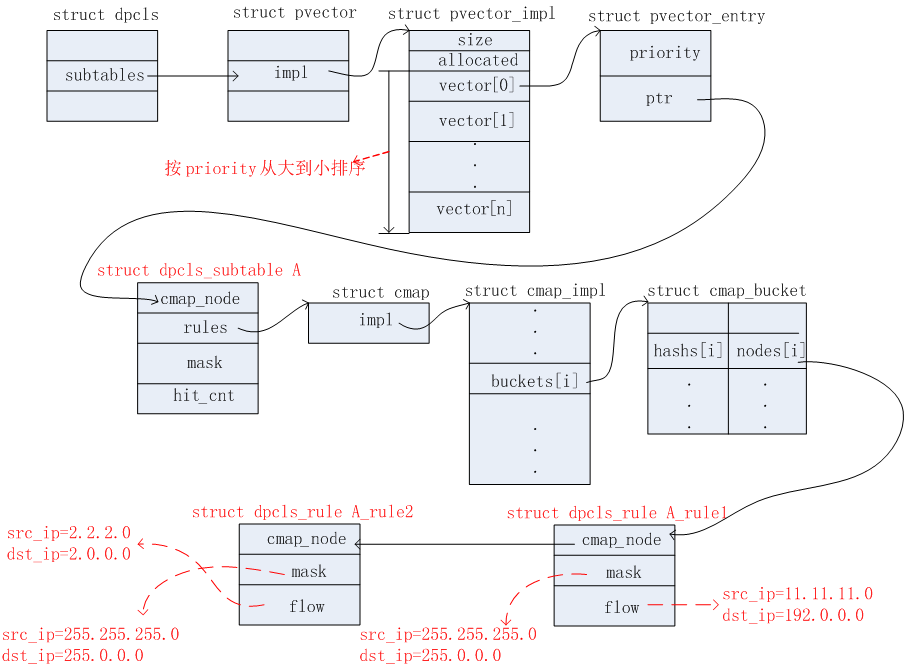
struct dpcls {
struct cmap_node node; /* 链表节点 */
odp_port_t in_port; /* 报文接收端口 */
struct cmap subtables_map; /* 所包含的子表信息 */
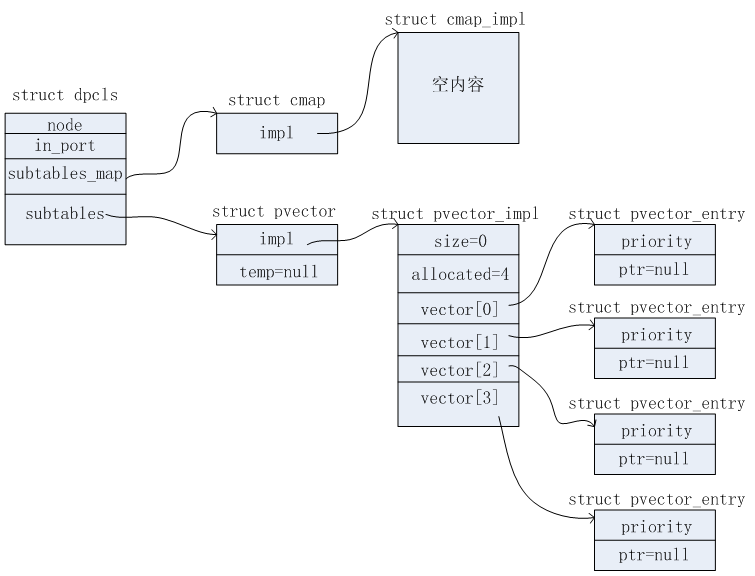
struct pvector subtables; /* 所包含的子表信息 */
}
struct pvector {
/* 指向具体子表信息 */
struct pvector_impl *impl;
/* 平时,temp都是为NULL.只有当pvector扩充时,temp才用来临时缓存数据.待排好序后,再拷贝到impl中,temp再置NULL */
struct pvector_impl *temp;
}
struct pvector_impl {
size_t size; /* Number of entries in the vector */
size_t allocated; /* Number allocted entries */
/* 初始化的时候只有4个元素.后续可能会扩充 */
struct pvector_entry vector[];
}
struct pvector_entry {
/* pvector_impl中的vector是按照priority从小到大排序的 */
int priority;
/* 实际指向了struct dpcls_subtable结构 */
void *ptr;
}
/* 子表信息 */
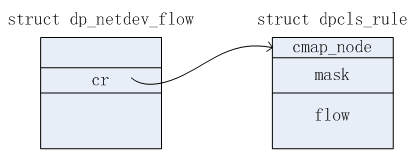
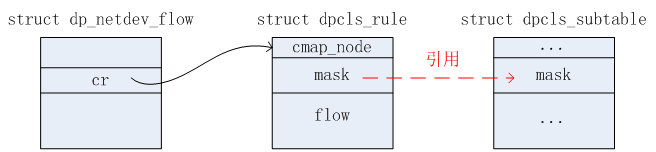
struct dpcls_subtable {
struct cmap_node cmap_node;
/* 每个子表都可以包含多条流规则. */
struct cmap rules;
/* 命中该子表的统计计数 */
uint32_t hit_cnt;
/* 子表中的掩码信息 */
struct netdev_flow_key mask;
}
|
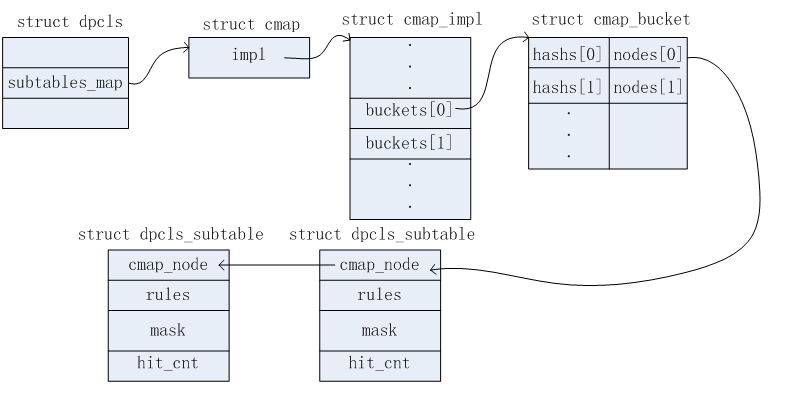
上述涉及的数据结构相对比较多。可以从三条链表分别分析。这三条链表结构示意图如下所示。
链表一
链表二
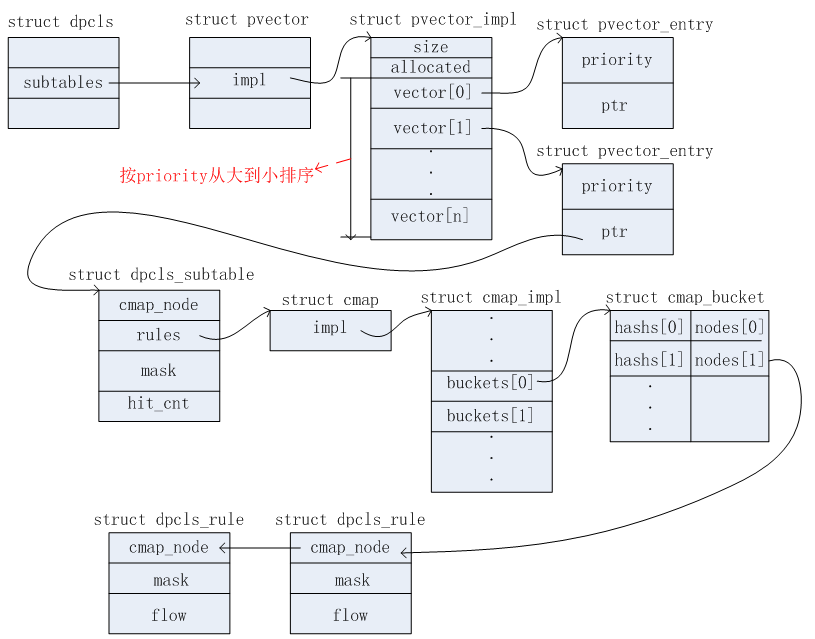
链表三
2.2.2.1.查找过程
链表一的查找
1)根据收报文的端口in_port值,通过一定的hash算法(这里不重点介绍)算出一个hash值,假设为in_port_hash。
2)同时根据in_port值,通过一定的hash算法(这里不重点介绍)分别算出两个hash值,记为hash1和hash2。利用这两个hash1和hash2分别在cmap_impl中的buckets数组中查找。如果利用hash1查找成功,则无需用hash2再进行查找了。查找成功的条件是通过比较bucket中的hashs[i]和in_port_hash值,相等则认为找到合适的bucket了。
3)成功找到bucket之后,遍历该bucket中的node链表查找合适的dpcls结构。查找的条件是通过比较dpcls结构中的in_port值和收报文的in_port值,相等则认为查找成功。
链表二的查找
通过在上述链表一找到对应的dpcls之后。则开始这它的所有subtable(子表)中进行查找匹配。可以有多个subtable,这些subtable是按照priority从大到小的顺序进行组织的。对应的subtable有对应的dpcls_subtable数据结构,表达了一个子表的信息,其中mask成员表示的是这个subtable的掩码(都知道DPCLS这个缓存表其实是一个通配符匹配表)。rules成员包含了这个subtable中所包含的流规则信息。hit_cnt成员则统计命中该subtable的数目。查找过程如下:
1)首先对接收到的报文计算出netdev_flow_key信息,记为pkt_key。
2)遍历每一个dpcls_subtable,根据其mask成员(也是netdev_flow_key结构),与1)计算出来的pkt_key做逻辑与操作,通过相关的hash算法(这里不重点介绍),计算出一个hash值,记为subtable_hash。
3)在dpcls_subtable结构中的rule查找每一个bucket,根据subtable_hash和bucket中的hash值做比较,相等则认为找到合适的bucket了。
4)找到合适的bucket之后,遍历它的node链表。将接收到的报文和每个node节点中的flow信息作比较:报文在1)已经计算出了pkt_key。根据pkt_key.mf和pkt_key.buf,再和掩码mask做逻辑与计算后,对应的每个匹配字段值都和node中flow记录的字段值相同,则认为匹配成功了。返回对应的dpcls_rule结构。
链表三的查找
通过分析ovs-dpdk源码,并没有通过这条链表去查找匹配。
上述查找的过程中,只要过程中的某一步匹配失败,则都认为在DPCLS表中匹配失败,返回Miss的结果,反之则返回Match的结果。对于匹配成功的报文,缓存在批量缓冲区中,等待一次处理。这个过程请参考2.3节。
2.2.2.2.更新过程
如果2.2.2.1查找过程中,返回Miss的结果,则需要将报文上送给OFPROTO进行查找对应的Actions。查找到之后,返回Actions信息。这个过程的具体细节请参考2.2.3节。
通过上送给OFPROTO,得到相应的Actions之后。对于这些报文,无需缓存在批量缓冲区中,而是直接执行对应的Actions,发送出去。
同时,从OFPROTO得到相应的Actions之后,需要相应地更新DPCLS和EMC缓存表。
更新DPCLS表
首先这里需要掌握一个辅助的数据结构,如下所示:
|
1
2
3
4
5
6
7
|
struct match {
/* 在上送给OFPROTO查找匹配时,该成员记录了报文的相关匹配字段信息 */
struct flow flow;
/* 这个成员主要用来缓存报文在DPCLS匹配Miss的时候,上送给OFPROTO时,由OFPROTO填充的相关掩码信息值 */
struct flow_wildcards wc;
struct tun_metadata_allocation tun_md; /* 暂时忽略 */
}
|
执行更新的过程主要有如下:
1)报文在前面已经计算出了netdev_flow_key信息,记为pkt_key。
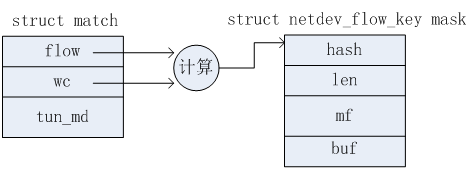
2)根据pkt_key的信息(主要是miniflow和buf信息),将报文的匹配字段值(之前已经压缩存储在了pkt_key中的mf和buf中)恢复到match结构中的flow成员存储。如下图所示。

3)将报文信息(match结构)上送给OFPROTO,由OFPROTO返回相应的Actions,同时返回的掩码信息存在在match结构中的wc成员。
4)根据match中的wc成员构造掩码信息。该掩码信息是一个netdev_flow_key结构类型。记为mask。如下图所示。其中mf和buf记录的只是掩码的信息,与具体流信息无关。
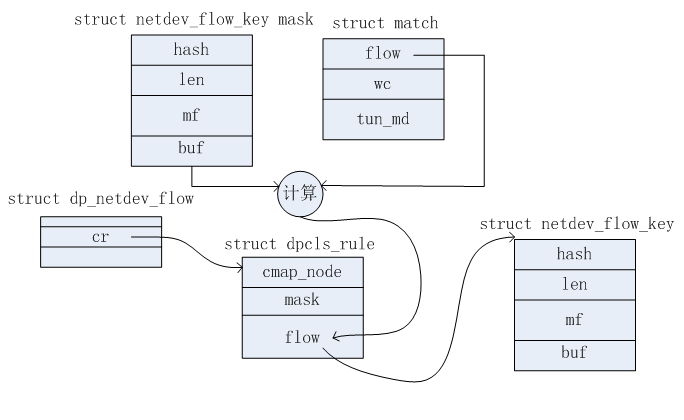
5)分配dp_netdev_flow结构,假设为flow。初始化flow,如下:
flow->stats=初始化全0
flow->dead = false;
flow->batch = null;
flow->pmd_id = pmd_id;
flow->flow = match->flow;
flow->ufid=ufid;
flow->ref_cnt=1;
flow->actions=在上面3)步返回的Actions;
flow->cr.flow的初始化如下图所示:其中flow->cr.flow.len=mask->len,flow->cr.flow.mf=mask->mf。flow->cr.flow.hash是根据match->flow和mask共同计算出来的。flow->cr.flow.buf也是根据match->flow和mask共同计算出来的。
6)根据收报文端口in_port去查找对应的dpcls结构,这个过程可以参考上述2.2.2.1节链表一的查找过程。如果找不到合适的dpcls结构,则需要插入一个新的dpcls结构。流程如下:
首先初始化一个dpcls结构(对应的in_port值填入),如下图所示:
接着根据in_port值计算出对应的hash值,在2.2.2节描述的链表一中,根据这个hash值找到合适的bucket,再将这个新的dpcls节点插入到对应bucket中的node链表首部。这个过程可能会遇到cmap_impl扩充的情况,这里不重点讲述扩充的情况。扩充的主要思想是:重新申请内存空间,遍历每个bucket,将旧bucket上对应的node链表重新插入到新的bucket中(插入到头部)。最终释放掉旧空间。
7)无论在6)步是否新创建了dpcls结构还是找到了合适的dpcls结构,这里都假设为cls。这步中要在这个cls中,根据掩码mask(上面第4)步中生成的),在cls->subtables_map链表中,即:2.2.2节所述的链表三,找到合适的dpcls_subtable。查找的过程如下:
首先根据mask->hash找到合适的bucket;然后在该bucket对应的node链表中,继续找到dpcls_subtable。查找的匹配条件是:遍历的node->mask.hash和mask->hash相等,且node->mask.mf和mask->mf相等。
如果找不到匹配的dpcls_subtable,则需要创建一个新的dpcls_subtable结构,插入到cls->subtables_map链表(2.2.2节所述的链表三)中去。新的dpcls_subtable结构信息如下图所示:

8)如果在上述第7)步中创建了新的dpcls_subtable,除了需要插入到cls->subtables_map链表中(2.2.2节所述的链表三),还需要插入到cls->subtables链表中(2.2.2节所述的链表二),插入的位置是放置在最后一个vector,这里可能会涉及到vector位置不足以存储新的dpcls_subtable,这时需要扩充vector的空间,以存储新的节点。扩充的细节暂时跳过,不详细描述(扩充过程就需要用到vector里面的temp指针,用完后释放掉。除此之外,在重现安排priority顺序时,也需要用到temp指针,重现安排好priority顺序之后,释放掉temp空间)。
9)在上述5)中创建的dp_netdev_flow变量:flow->cr.mask赋值为掩码mask。接着将flow->cr插入到dpcls_subtable结构中的rules链表中。到此为止,完成DPCLS所有表项的更新。
更新EMC表
上面更新完DPCLS表项之后,返回了dp_netdev_flow结构的流表信息。需要将这个具体的流表信息添加到EMC表中。这部分可以参考上述的2.2.1.2节。这里不再赘述。
2.2.2.3.删除过程
目前从源码分析到的删除触发有两个方面,如下:
1)指定删除某条流表时,触发DPCLS表项的删除流程。
2)销毁一个PMD线程时,需要将该PMD所拥有的流表信息删除,进而触发DPCLS表项的删除流程。
删除指定某条流表
涉及的相关数据结构如下所示。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
enum dpif_op_type {
DPIF_OP_FLOW_PUT=1,
DPIF_OP_FLOW_DEL, /* 我们主要关注这个 */
DPIF_OP_EXECUTE,
DPIF_OP_FLOW_GET
}
struct dpif_op {
enum dpif_op_type type;
int error;
union {
…
struct dpif_flow_del flow_del; /* 我们主要关注这个 */
…
} u;
}
struct dpif_flow_del {
/* input */
const struct nlattr *key; /* 需要删除流表对应的匹配关键字信息 */
size_t key_len;
const ovs_128 ufid; /* 如果没有ufid的话,则需要根据上面的key信息计算出ufid,再根据这个ufid去找到需要删除流表的dp_netdev_flow信息 */
bool terse;
unsigned pmd_id; /* dpdk pmd线程id,如果没有,则表明需要在所有的pmd线程上删除这条流表.如果有指定,则只在指定的pmd线程删除这条流表 */
/* output */
struct dpif_flow_stats; /* 统计使用,暂时忽略 */
}
|
流程如下:
1)根据dpif_flow_del,简称del->ufid找到对应的pmd信息。如果del->ufid未设置,则找到当前所有的pmd线程。在dp_netdev结构中,成员poll_threads用于组织当前所有的pmd线程信息链表。如下图所示。
2)假设找到pmd信息,记为pmd。在下面的2.2.4节,我们知道每个PMD都存储了其所有流表信息(dp_netdev_flow结构),因此,在删除之前,需要从这条链表中找到需要删除的流表。查找的过程是使用del->ufid。但是存在del->ufid未指定的情况,因此,对于ufid未指定时,需要从del->key信息中计算出ufid值。简单的思路是:从del->key恢复各个流匹配字段信息值,存储在struct flow结构中,在根据一定的hash算法与flow值,最终计算出ufid。这里不详细讲述如何计算ufid的过程。计算出ufid之后,在pmd流表链中找到需要删除的流信息。匹配的条件是用del->ufid或刚计算出的ufid和pmd流表链中每个节点中的ufid对比,相同则匹配成功。
3)假设在上一步找到了需要删除的流信息,记为flow。根据下图dp_netdev_flow和dpcls_rule的关系。可以从flow中得知需要删除哪个dpcls_rule,即:某个subtable下的dpcls_rule信息。
4)上一步找到dpcls_rule信息,记为rule。通过flow->flow.in_port.odp_port在上述2.2.2节所述的链表一中找到对应的dpcls信息(节点),记为cls。现在的工作就演变成了在cls下删除rule。从下图可知,rule中的mask其实引用的是cls中的mask值。因此,通过rule->mask可以找到对应的dpcls_subtable,记为subtable。这样工作的范围缩小到了在subtable中删除rule。因此首先将rule节点从subtable->rule链表(见2.2.2节链表二)中删除掉(注意:这里的删除只是将rule节点从subtable->rule链表中移除掉,rule的内存空间并未释放,后续操作依然还需要使用到)。如果删除的这个rule是subtable最后一个rule,则删除掉rule之后,还需要将对应的subtable节点从cls->subtables和cls->subtables_map中删除掉。最后释放subtable->rule、subtable的内存空间。(在cls->subtables删除subtable节点时,会涉及到重新安排其对应的pvector,这里不详细展开)
5)处理完DPCLS之后,需要将对应的flow(dp_netdev_flow结构)从pmd->flow_table链表中(见2.2.4节)移除掉。将flow->dead置上true,触发EMC的删除过程(见2.2.1.3节)。
销毁一个PMD线程
销毁一个PMD线程时,首先需要将该PMD拥有的所有流表(PMD流表链,见2.2.4节)都删除掉。这个过程最终会走到” 删除指定某条流表”。这里不再赘述。
除此之外,还会将pmd->classifiers指向的所有资源都释放掉。
2.2.3.OFPROTO
在DPCLS匹配过程中,得到Miss结果,需要继续将报文上送给OFPROTO,由它负责查找该报文匹配哪些openflow流表,返回相应的Actions。这部分的细节暂时还没看明白如何查找这些Actions,暂时先跳过。
2.2.4.PMD流表链
这节并不属于三级流表中的某个表项。这里描述的是某个PMD线程所包含的所有流表项信息。结构如下图所示。其中查找bucket时,是根据dp_netdev_flow结构中的uifd成员值,通过一定的hash算法来找到合适的bucket。
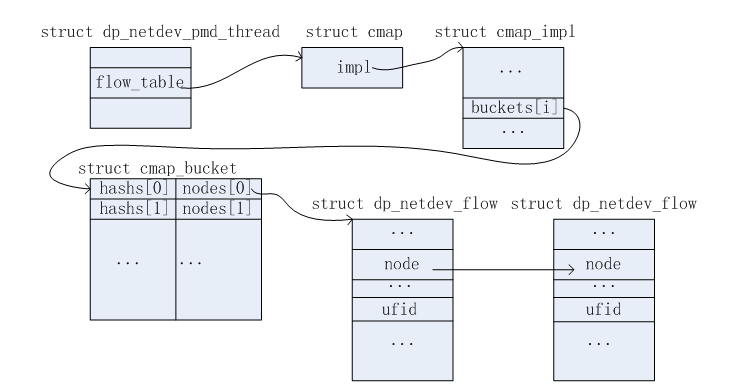
对于删除过程,请参考上述2.2.2.3节。
2.2.5.示例
上述已经对三级流表的匹配及更新流程做了详细的描述。这里给出一个简单的示例,以更具体的例子来反映上述匹配及更新的流程,加深理解。为了简单起见,下面都假设报文的收端口都是从固定某个端口接收的,假设in_port=1。同时只关注报文中的源IP和目的IP两个匹配域,暂时忽略其他的匹配域信息。
数据结构的初始化状态如下图所示:

OFPROTO存储的OpenFlow流表信息
假设这里存储的OpenFlow流表信息如下所示:
|
1
2
3
|
table=0, src_ip=11.11.11.0/24, dst_ip=192.0.0.0/8, actions=output:1
table=0, src_ip=2.2.2.0/24, dst_ip=2.0.0.0/8, actions=output:2
table=0, dst_ip=8.0.0.0/8, actions=drop
|
收到第一个报文:src_ip=11.11.11.25, dst_ip=192.1.1.1
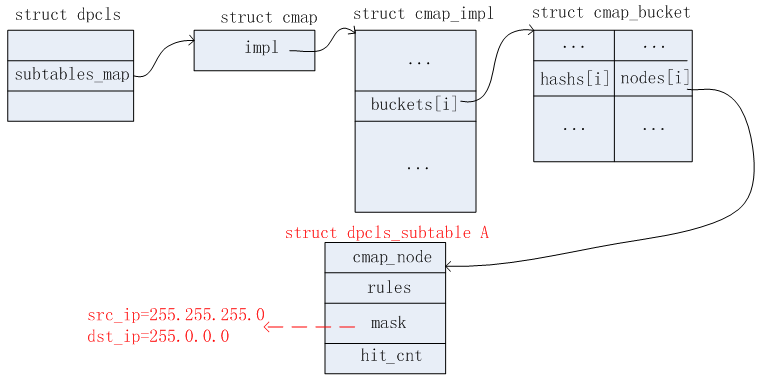
首次收到报文,毫无疑问,在EMC和DPCLS表中都是Miss的。因此需要上送给OFPROTO去查具体的Actions。根据上面给出的OpenFlow流表信息,得知,这个报文需要执行的Actions为output:1,掩码信息为src_ip=255.255.255.0, dst_ip=255.0.0.0。因此得到这些信息之后,需要新增的数据结构有:dpcls、dpcls_subtable、dpcls_rule。添加完毕后,相关的数据结构如下几个图所示。
1)DPCLS链表一
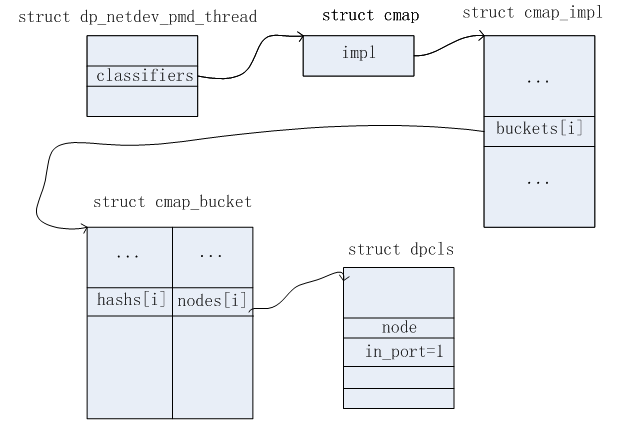
2)DPCLS链表二
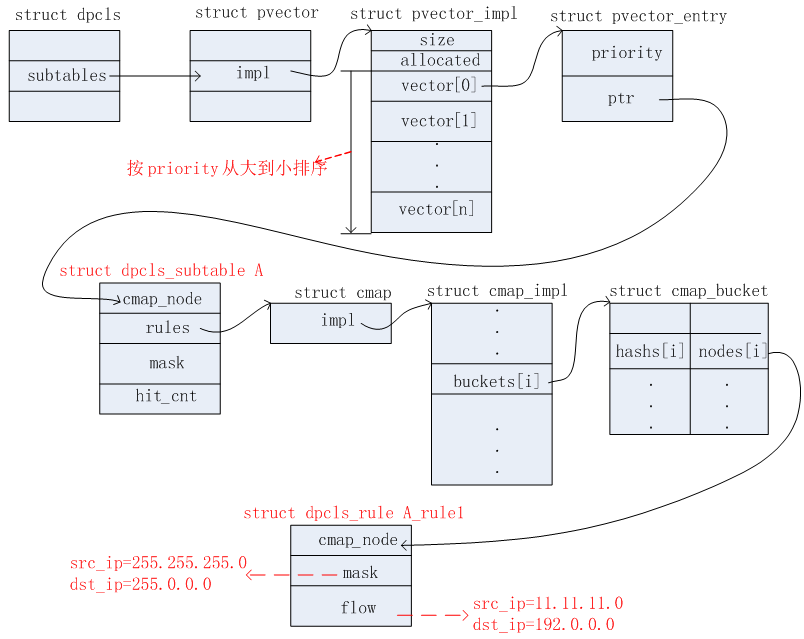
3)DPCLS链表三
4)EMC表
上面三个链表更新完毕之后,需要更新EMC表,更新后如下图所示:
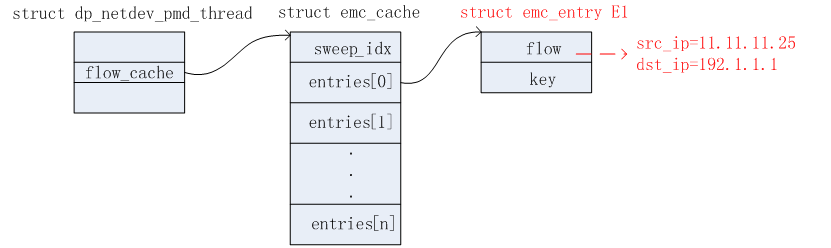
收到第二个报文:src_ip=11.11.11.63, dst_ip=192.168.7.8
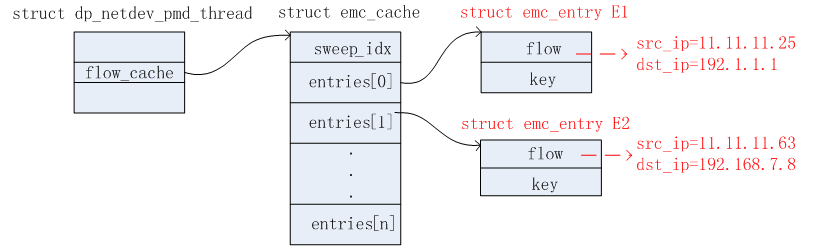
收到第二个报文时,此时在EMC表中是Miss的。接着继续在DPCLS表中查找匹配。此时,DPCLS中已经有一个subtable A了。该subtable的掩码信息为src_ip=255.255.255.0,dst_ip=255.0.0.0。将第二个报文的src_ip和dst_ip与这个subtable的掩码进行逻辑与运算,得出src_ip_masked=11.11.11.0,dst_ip_masked=192.0.0.0。根据上述DPCLS链表二,成功匹配上A_rule1。匹配成功。此时只需要更新EMC表项即可,更新后的EMC表如下图所示。
收到第三个报文:src_ip=2.2.2.4, dst_ip=2.7.7.7
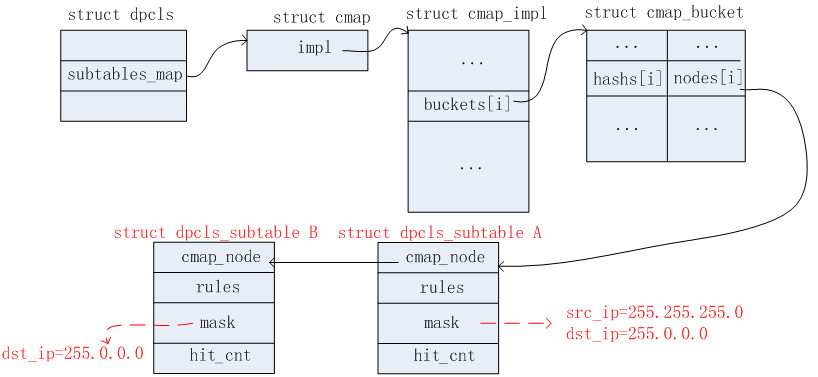
收到第三个报文时,此时在EMC表中是Miss的。接着继续在DPCLS表中查找匹配。此时,DPCLS中已经有一个subtable A了。该subtable的掩码信息为src_ip=255.255.255.0,dst_ip=255.0.0.0。将第二个报文的src_ip和dst_ip与这个subtable的掩码进行逻辑与运算,得出src_ip_masked=2.2.2.0,dst_ip_masked=2.0.0.0。根据上述DPCLS链表二,无法匹配,因此继续上送给OFPROTO,根据前面OFPROTO存储的OpenFlow流表中得知,该报文需要执行的Actions为output:2,掩码信息为src_ip=255.255.255.0, dst_ip=255.0.0.0。根据这个掩码信息,首先在上述的DPCLS链表三中可以找到合适的dpcls_subtable A。因为有相同的掩码信息。因此只需要在这个dpcls_subtable中新增相应的dpcls_rule信息即可。这里假设和前面添加的A_rule1处于相同的bucket中,因此更新后的DPCLS链表二如下图所示。
1)DPCLS链表二
2)同时更新EMC表项,如下图所示:

收到第四个报文:dst_ip=8.12.34.56
收到第四个报文,根据前面的方法,在EMC和DPCLS表中都是Miss的。因此上送给OFPROTO,得知这个报文需要执行的Actions为drop。掩码信息为dst_ip=255.0.0.0。因此需要在DPCLS链表三中新增dpcls_subtable节点。
1)DPCLS链表三
2)DPCLS链表二
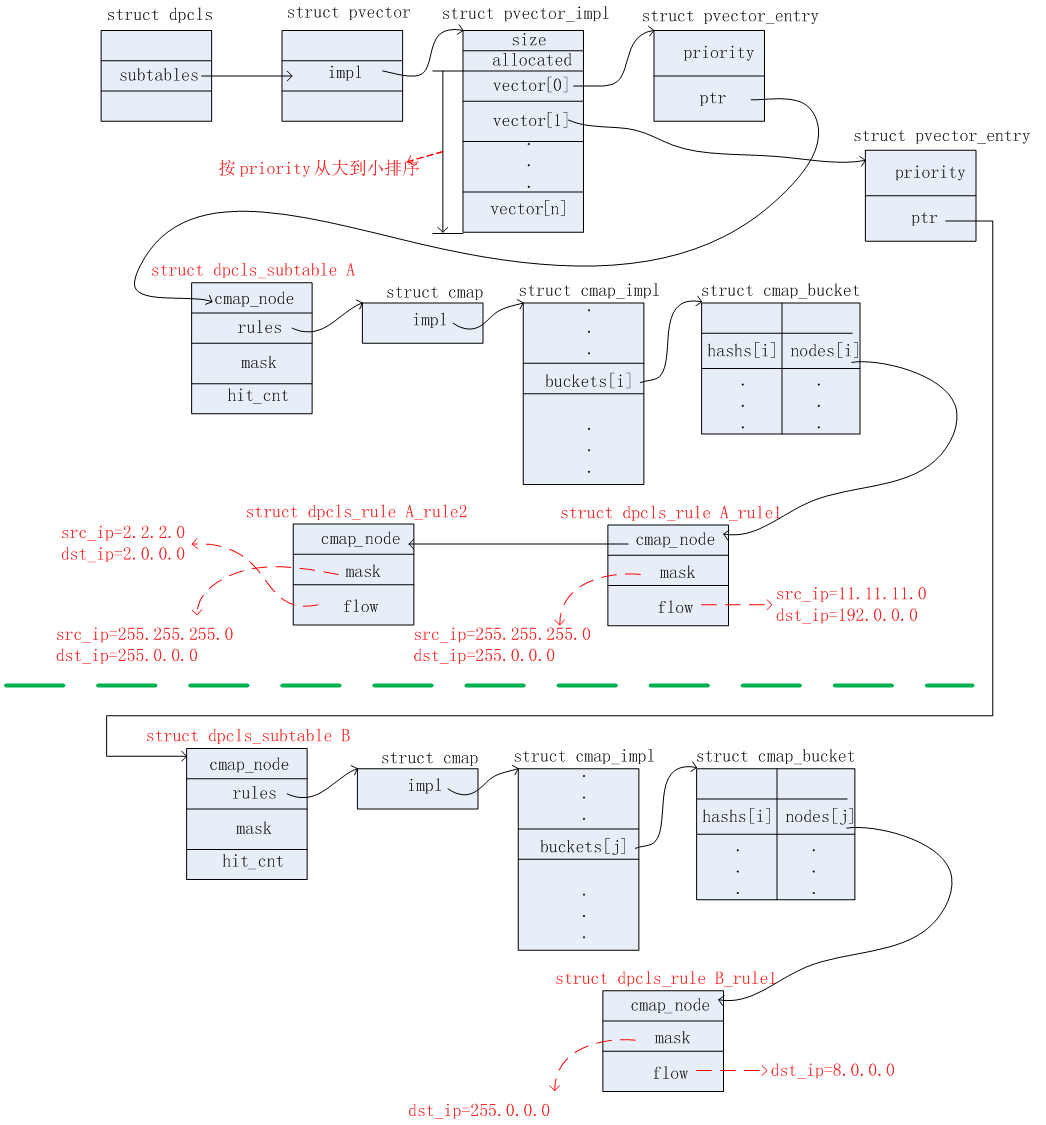
3)EMC表

收到第五个报文:src_ip=11.11.11.63, dst_ip=192.168.7.8
EMC表命中,直接执行Actions。
到此为止,这个实例结束。
2.3.批量接收和发送
2.3.1.批量接收
首先需要掌握如下一个数据结构。
|
1
2
3
4
5
|
sturct dp_packet_batch {
int count; /* 指示当前有多少个报文 */
boolean trunk; /* 暂时忽略 */
struct dp_packets[32]; /* 一次批量可以接收32个报文 */
}
|
从dpdk网卡接收报文时,一次可以批量接收32个报文,这些报文的信息都存储在dp_patch_batch数据结构中。
2.3.2.批量发送
首先需要掌握如下一个数据结构。
|
1
2
3
4
5
6
7
|
/* 用于缓存匹配某个流表项的多个报文.最多缓存32个报文 */
struct packet_batch_per_flow {
unsigned int byte_count; /* 缓冲区中报文的总字节数 */
uint16_t tcp_flag; /* 暂时忽略 */
struct dp_netdev_flow *flow; /* 指向所匹配的流表项信息 */
struct dp_packet_batch array; /* 见2.3.1节 */
}
|
在EMC查找过程中,如果某个报文命中了表项,则将这个报文先缓存在批量缓冲区中。
如果在EMC查找失败,但是在DPCLS中报文命中了表项,则也将这个报文先缓存在批量缓冲区中。
如果在EMC和DPCLS表中都Miss,通过上送给OFPROTO得知具体的Actions,无需缓存,立即发送出去。
在上述2.2.2.2节的第5)步新增dp_netdev_flow流表项信息时,其成员batch置NULL。表明该流表项还为赋予批量缓冲区用于缓存匹配这条流表项的报文信息。当后续有报文命中该流表项(无论是在EMC还是在DPCLS表中),这个batch成员会指向一个缓冲区,用于缓存命中该流表项的多个报文信息。
从接收到报文到匹配再到将报文缓存起来的过程如下图所示。
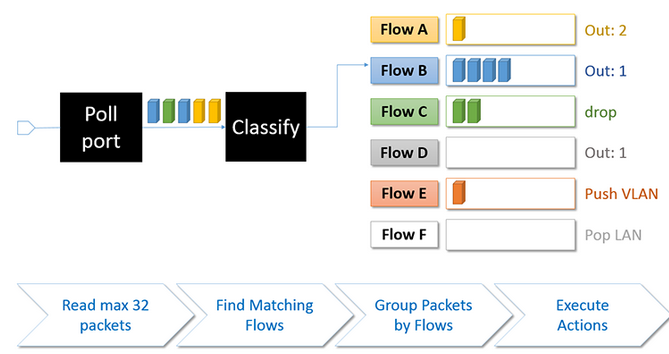
多个报文命中同一条流表项,缓存起来,再一起执行相同的Actions。这样做的好处是能够提高报文的转发性能。
在执行Actions时,遍历每一个批量缓冲区,每个缓冲区可能存储了多个报文,这些报文都需要执行相同的Actions。因此,对于具体某些Actions,这些报文都需要有相同的添加或修改效果。比如push_vlan的Actions,对于批量缓冲区中的所有报文,都需要打上相应的vlan id,再发送出去。