摘要:在平时工作中,TB车身的传递函数分析,涉及到大量重复行的工作,费时费力。在学习python基础后,希望通过代码解决这部分重复工作。基础入门级操作,但是能够解决很大一部分工作内容。日后,待python学习达到一定水平后,在寻找更优的解决方案。
NVH频响,接附点一般在30个左右,分x,y,z三个方向,激励工况在90个上下,每个工况对应DAREA,RLOAD,DLOAD;在实际项目中,习惯运用工况文本文件进行提交运算。NTF计算,90个工况,对应90个响应;VTF计算,90个工况对应270个响应;IPI计算90个工况对应270个响应。前处理工况加载事件费事费力的工作,结果处理更是重复繁杂,而且容易出错。基于这样的情况,以下运用python基础技巧,进行解决。
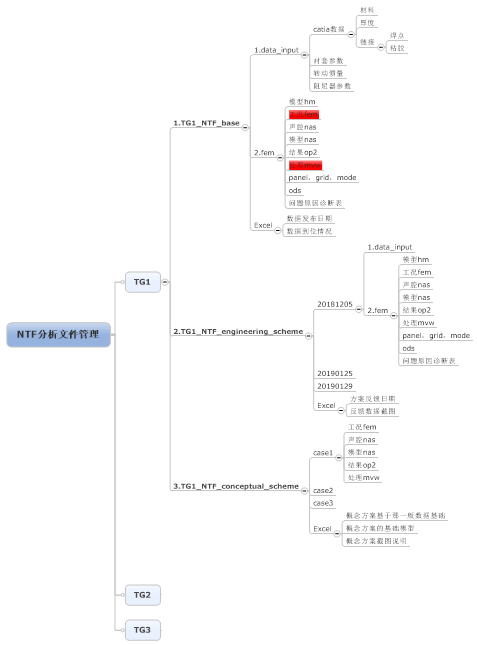
一.文件管理
1.项目阶段TG1,TG2,TG3;
1.1每一阶段(如TG1)分别用三个文件夹来存储计算模型和结果
1.TG1_base:文件夹存放该论分析的基础模型;备注好数据日期,数据输入缺失项,以及商定缺失数据处理方案;
2.TG1_Engineering_scheme:文件夹存放工程技术方案(由你向设计部分提供概念优化方案,并且认定为可实施的工程方案,设计部分修改后的数据,逐一替换到该模型之中,每一次替换保存一个hm),在该文件夹中创建以日期命名的文件夹,用于存储设计部分反馈数据并且替换好的模型,并且以Excel备注好反馈的简明信息,并且每版数据替换后保存好hm文件,以免connector丢失;如有必要,在对应的日期的工程反馈数据模型中,进行问题诊断。
3.TG1_conceptual_scheme:文件夹存放概念优化方案(case1代表第一个概念方案,case2代表第二个概念方案········;一旦方案被认定为可工程化方案,移交设计部分进行设计画数据),并且以Excel备注好,方案基于那一版工程数据,方案的截图;路径及文件夹命名最好不要用汉字,用字母、数字、下划线;】
1.2运用python处理的文件为工况文件fem及结果处理文件mvw
二.工况文件fem及结果处理文件mvw
2.1.NTF计算工况文件fem
30个这样的组合(甚至更多,后续默认30个接附点)
2.NTF后处理文件mvw
90个这样的图片,一个工况subcase对应一个page包含3条曲线,红色代表基础模型计算结果,绿色代表可工程化的优化方案,蓝色虚线代表概念优化方案。

三.运用python处理重复工作(工况文件fem,结果处理文件mvw)
1.计算工况文件及结果处理文件mvw的制作
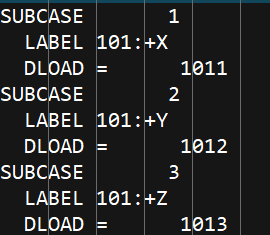
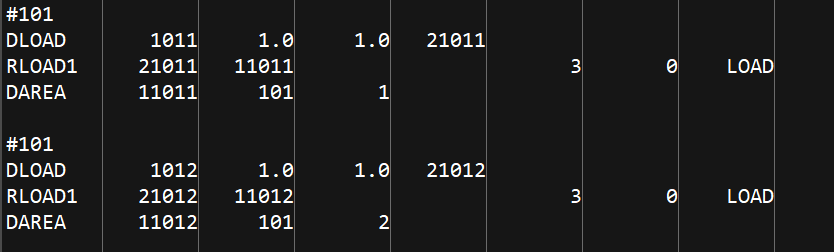
1.1subcase以及DAREA,RLOAD,DLOAD的编写
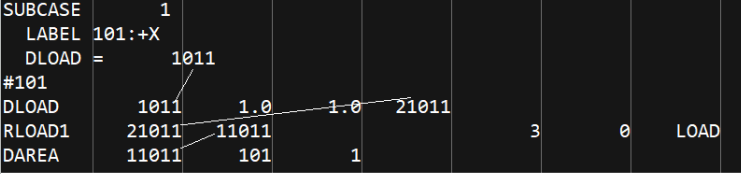
1.2所用到的python的命令
函数:def 函数定义好后,不调用就不会执行,当需要制作计算工况文件时,调用函数 header_sub();当需要制作后处理MVW文件时,调用NTF_result()
#coding=utf-8
#Version:python3.7.0
#tools:Pycharm 2017.3.2
##先通过hypergraph按自己要求制作出一张page,保存mvw格式文件作为需要重复的输入文件
mvw_onepage_input = "D:/NVH/NVH/NVH_scripts/TB_NTF/1.header_result/1.input_mvw/lne3_target3.mvw"
##python通过接收输入的文件,逐行读取,修改关键参数,在写入到后处理文件中
mvw_NTF_output = "D:/NVH/NVH/NVH_scripts/TB_NTF/1.header_result/2.output_mvw/Base_Engineering_conceptual.mvw"
##计算工况文件,内含在python代码中,直接输出即可。其他参数比较单一,直接复制粘贴即可
header_NTF_output = "D:/NVH/NVH/NVH_scripts/TB_NTF/1.header_result/3.output_header/NTF_header.fem"
##需要加载工况的接附点,制作成列表,方便代码调用
input_point = [101,102,103,201,202,203,204,205,206,301,302,303,304,305,306,307,308,309,310,311,312,401,402,403,404,405,406,501, 502,503,504,505,506,601,602,603,604]
##在工况文件中一个接附点(如101),对应3个方向的激励,定义方向列表
direc = ['X','Y','Z']
##定义后处理mvw文件制作,替换onepage中的所有SUBCASE 1 = 101:+X,p1w1,Page 1,page1,WindowIDs(2),然后逐行左对齐写入Base_Engineering_conceptual.mvw文件中
def NTF_result():
with open(mvw_NTF_output, 'a') as NTF_object: #以追加形式打开文件mvw_NTF_output,如果文件不存在,创建文件
NTF_object.write("{ safe_quotes_on } ") #写入文本
NTF_object.write('{ PLOT_FILE_1 = "TG1_base.op2"} ')
NTF_object.write('{ PLOT_FILE_2 = "TG1_Engineering_scheme.op2" } ')
NTF_object.write('{ PLOT_FILE_3 = "TG1_conceptual_scheme.op2" } ')
NTF_object.write('*Id("HyperWorks", "12.*") ')
NTF_object.write('*BeginPalette() ')
NTF_object.write('*EndPalette() ')
i = 0
while i < len(input_point): #开始处理重复page
j = 0
while j < 3:
with open(mvw_onepage_input) as file_object: #打开事先调试好的一页page文件mvw_onepage_input
for line in file_object:
sub_id = 3 * i + j + 1
if sub_id < 10 : #此处是因为前任制作的工况文件的sub是1-9 19-120,所以此处用if语句跳过10-18
s1 = line.replace('SUBCASE 1 = 101:+X',
'SUBCASE {n1} = {n2}:+{n3}'.format(n1=3 * i + j + 1, n2=input_point[i],
n3=direc[j]))
s2 = s1.replace('p1w1', 'p{n1}w1'.format(n1=3 * i + j + 1))
s3 = s2.replace('Page 1', 'Page {n1}'.format(n1=3 * i + j + 1))
s4 = s3.replace('WindowIDs(2)', 'WindowIDs({n1})'.format(n1=3 * i + j + 2))
s5 = s4.replace('page1', 'page{n1}'.format(n1=3 * i + j + 1))
with open(mvw_NTF_output, 'a') as NTF_object:
NTF_object.write(s5.rstrip())
NTF_object.write(' ')
else :
sub_id = 3 * i + j + 10
s1 = line.replace('SUBCASE 1 = 101:+X',
'SUBCASE {n1} = {n2}:+{n3}'.format(n1=sub_id, n2=input_point[i],
n3=direc[j]))
s2 = s1.replace('p1', 'p{n1}'.format(n1=3 * i + j + 1))
s3 = s2.replace('Page 1', 'Page {n1}'.format(n1=3 * i + j + 1))
s4 = s3.replace('WindowIDs(2)', 'WindowIDs({n1})'.format(n1=3 * i + j + 2))
s5 = s4.replace('page1', 'page{n1}'.format(n1=3 * i + j + 1))
with open(mvw_NTF_output, 'a') as NTF_object:
NTF_object.write(s5.rstrip())
NTF_object.write(' ')
j += 1
i += 1
def NTF_sub(): #定义工况文件,注意int数据类型转变为str
i = 0
while i < len(input_point): #写入sucase
j = 0
while j < 3:
with open(header_NTF_output, 'a') as header_object:
header_object.write('SUBCASE {n1} '.format(n1=3 * i + j + 1))
header_object.write(' LABEL {n1}:+{n2} '.format(n1=input_point[i],n2=direc[j]))
header_object.write(' DLOAD = {n1} '.format(n1=input_point[i]*10+j+1))
j += 1
i += 1
a = 0
while a < len(input_point): #写入DAREA,RLOAD,DLOAD
b = 0
while b < 3:
with open(header_NTF_output, 'a') as header_object:
dload_id = input_point[a]*10 + b+1
rLoad_id = 20000+input_point[a]*10 + b+1
darea_id = 10000+input_point[a]*10 + b+1
point = '#'+str(input_point[a])
xyz = b+1
header_object.write(' ')
header_object.write(point.ljust(8))
header_object.write(' ')
header_object.write('DLOAD'.ljust(8))
header_object.write(str(dload_id).rjust(8))
header_object.write('1.0'.rjust(8))
header_object.write('1.0'.rjust(8))
header_object.write(str(rLoad_id).rjust(8))
header_object.write(' ')
header_object.write('RLOAD1'.ljust(8))
header_object.write(str(rLoad_id).rjust(8))
header_object.write(str(darea_id).rjust(8))
header_object.write('3'.rjust(24))
header_object.write('0'.rjust(8))
header_object.write('LOAD'.rjust(8))
header_object.write(' ')
header_object.write('DAREA'.ljust(8))
header_object.write(str(darea_id).rjust(8))
header_object.write(str(input_point[a]).rjust(8))
header_object.write(str(xyz).rjust(8))
header_object.write(' ')
b += 1
a += 1
NTF_sub() #工况文件值写入了sub DAREA RLOAD DLOAD,其余相关设置复制粘贴即可
NTF_result() #调用定义的函数,不调用函数不执行
四.运用
1.NTF_header.fem
不重复的部分,python代码并没有写入;相关参数直接用复制以往计算文件,用NTF_header中的sub替换即可
2.Base_Engineering_conceptual.mvw
用UE打开,对应结果文件的路径及名称替换后就看可以用hypergraph打开,就出现三条曲线对比的图
{ PLOT_FILE_1 = "`````/TG1/1.TG1_NTF_base/TG1_base.op2"}
{ PLOT_FILE_2 = "`````/TG1/2.TG1_NTF_engineering_scheme/20190325/TG1_Engineering_scheme.op2" }
{ PLOT_FILE_3 = "`````/TG1/3.TG1_NTF_conceptual_scheme/case1/TG1_conceptual_scheme.op2" }
总结:该过程只能解决整个分析过程的一些片段,不能系统的解决工程问题。本人也在不断学习改进中,希望通过解决实际工作中的问题,来学习python。没错,是为了学习python,把工作问题拿来练习。
如果各位大神有更好的解决方案,欢迎邮件联系:liuhuacai@outlook.com