1. multiprocessing像线程一样管理进程
multiprocessing模块包含一个API,它基于threadingAPI,可以把工作划分到多个进程。有些情况下,multiprocessing可以作为临时替换取代threading来利用多个CPU内核,相应地避免Python全局解释器锁所带来的计算瓶颈。
由于multiprocessing与threading模块的这种相似性,这里的前几个例子都是从threading例子修改得来。后面会介绍multiprocessing中有但threading未提供的特性。
1.1 multiprocessing基础
要创建第二个进程,最简单的方法是用一个目标函数实例化一个Process对象,然后调用start()让它开始工作。
import multiprocessing def worker(): """worker function""" print('Worker') if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process(target=worker) jobs.append(p) p.start()
输出中单词“Worker”将打印5次,不过取决于具体的执行顺序,无法清楚地看出孰先孰后,这是因为每个进程都在竞争访问输出流。

大多数情况下,更有用的做法是,在创建一个进程时提供参数来告诉它要做什么。与threading不同,要向一个multiprocessing Process传递参数,这个参数必须能够用pickle串行化。下面这个例子向各个工作进程传递一个要打印的数。
import multiprocessing def worker(num): """thread worker function""" print('Worker:', num) if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process(target=worker, args=(i,)) jobs.append(p) p.start()
现在整数参数会包含在各个工作进程打印的消息中。

1.2 可导入的目标函数
threading与multiprocessing例子之间有一个区别,multiprocessing例子中对main使用了额外的保护。基于启动新进程的方式,要求子进程能够导入包含目标函数的脚本。可以把应用的主要部分包装在一个__main_检查中,确保模块导入时不会在各个子进程中递归地运行。另一种方法是从一个单独的脚本导入目标函数。
import multiprocessing def worker(): """worker function""" print('Worker') return if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process( target=worker, ) jobs.append(p) p.start()
调用主程序会生成与第一个例子类似的输出。

1.3 确定当前进程
通过传递参数来标识或命名进程很麻烦,也没有必要。每个Process实例都有一个名,可以在创建进程时改变它的默认值。对进程命名对于跟踪进程很有用,特别是如果应用中有多种类型的进程在同时运行。
import multiprocessing import time def worker(): name = multiprocessing.current_process().name print(name, 'Starting') time.sleep(2) print(name, 'Exiting') def my_service(): name = multiprocessing.current_process().name print(name, 'Starting') time.sleep(3) print(name, 'Exiting') if __name__ == '__main__': service = multiprocessing.Process( name='my_service', target=my_service, ) worker_1 = multiprocessing.Process( name='worker 1', target=worker, ) worker_2 = multiprocessing.Process( # default name target=worker, ) worker_1.start() worker_2.start() service.start()
调试输出中,每行都包含当前进程的名。进程名列为Process-3的行对应未命名的
进程worker_1。

1.4 守护进程
默认地,在所有子进程退出之前主程序不会退出。有些情况下,可能需要启动一个后台进程,它可以一直运行而不阻塞主程序退出,如果一个服务无法用一种容易的方法中断进程,或者希望进程工作到一半时中止而不损失或破坏数据(例如为一个服务监控工具生成“心跳”的任务),那么对于这些服务,使用守护进程就很有用。
要标志一个进程为守护进程,可以将其daemon属性设置为True。默认情况下进程不作为守护进程。
import multiprocessing import time import sys def daemon(): p = multiprocessing.current_process() print('Starting:', p.name, p.pid) sys.stdout.flush() time.sleep(2) print('Exiting :', p.name, p.pid) sys.stdout.flush() def non_daemon(): p = multiprocessing.current_process() print('Starting:', p.name, p.pid) sys.stdout.flush() print('Exiting :', p.name, p.pid) sys.stdout.flush() if __name__ == '__main__': d = multiprocessing.Process( name='daemon', target=daemon, ) d.daemon = True n = multiprocessing.Process( name='non-daemon', target=non_daemon, ) n.daemon = False d.start() time.sleep(1) n.start()
输出中没有守护进程的“Exiting”消息,因为在守护进程从其2秒的睡眠时间唤醒之前,所有非守护进程(包括主程序)已经退出。

守护进程会在主程序退出之前自动终止,以避免留下“孤”进程继续运行。要验证这一点,可以查找程序运行时打印的进程ID值,然后用一个类似ps的命令检查该进程。
1.5 等待进程
要等待一共进程完成工作并退出,可以使用join()方法。
import multiprocessing import time def daemon(): name = multiprocessing.current_process().name print('Starting:', name) time.sleep(2) print('Exiting :', name) def non_daemon(): name = multiprocessing.current_process().name print('Starting:', name) print('Exiting :', name) if __name__ == '__main__': d = multiprocessing.Process( name='daemon', target=daemon, ) d.daemon = True n = multiprocessing.Process( name='non-daemon', target=non_daemon, ) n.daemon = False d.start() time.sleep(1) n.start() d.join() n.join()
由于主进程使用join()等待守护进程退出,所以这一次会打印“Exiting”消息。

默认地,join()会无限阻塞。可以向这个模块传入一个超时参数(这是一个浮点数,表示在进程变为不活动之前所等待的秒数)。即使进程在这个超时期限内没有完成,join()也会返回。
import multiprocessing import time def daemon(): name = multiprocessing.current_process().name print('Starting:', name) time.sleep(2) print('Exiting :', name) def non_daemon(): name = multiprocessing.current_process().name print('Starting:', name) print('Exiting :', name) if __name__ == '__main__': d = multiprocessing.Process( name='daemon', target=daemon, ) d.daemon = True n = multiprocessing.Process( name='non-daemon', target=non_daemon, ) n.daemon = False d.start() n.start() d.join(1) print('d.is_alive()', d.is_alive()) n.join()
由于传入的超时值小于守护进程睡眠的时间,所以join()返回之后这个进程仍"活着"。

1.6 终止进程
尽管最好使用“毒药”(poison pill)方法向进程发出信号,告诉它应当退出,但是如果一个进程看起来经挂起或陷入死锁,那么能够强制性地将其结束会很有用。对一个进程对象调用terminate()会结束子进程。
import multiprocessing import time def slow_worker(): print('Starting worker') time.sleep(0.1) print('Finished worker') if __name__ == '__main__': p = multiprocessing.Process(target=slow_worker) print('BEFORE:', p, p.is_alive()) p.start() print('DURING:', p, p.is_alive()) p.terminate() print('TERMINATED:', p, p.is_alive()) p.join() print('JOINED:', p, p.is_alive())

1.7 进程退出状态
进程退出时生成的状态码可以通过exitcode属性访问。下表列出了这个属性的可取值范围。
| 退出码 | 含义 |
|---|---|
== 0 |
没有产生错误 |
> 0 |
进程有一个错误,并以该错误码退出 |
< 0 |
进程以一个-1 * exitcode |
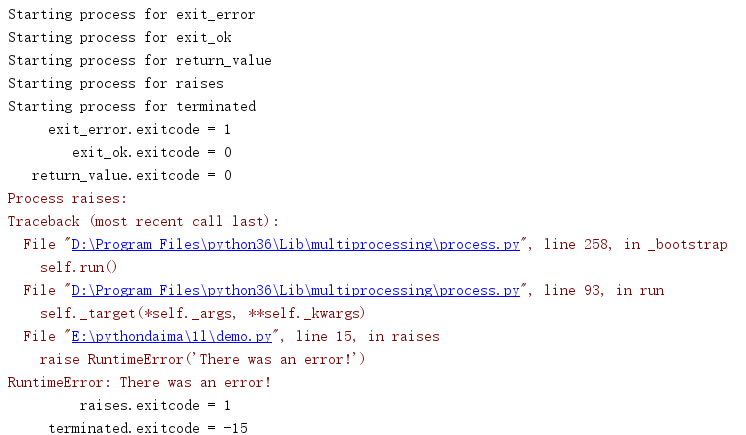
import multiprocessing import sys import time def exit_error(): sys.exit(1) def exit_ok(): return def return_value(): return 1 def raises(): raise RuntimeError('There was an error!') def terminated(): time.sleep(3) if __name__ == '__main__': jobs = [] funcs = [ exit_error, exit_ok, return_value, raises, terminated, ] for f in funcs: print('Starting process for', f.__name__) j = multiprocessing.Process(target=f, name=f.__name__) jobs.append(j) j.start() jobs[-1].terminate() for j in jobs: j.join() print('{:>15}.exitcode = {}'.format(j.name, j.exitcode))
产生异常的进程会自动得到exitcode为1。
1.8 日志
调试并发问题时,如果能够访问multiprocessing所提供对象的内部状态,那么这会很有用。可以使用一个方便的模块级函数启用日志记录,名为log_to_stderr()。它使用logging建立一个日志记录器对象,并增加一个处理器,使日志消息被发送到标准错误通道。
import multiprocessing import logging import sys def worker(): print('Doing some work') sys.stdout.flush() if __name__ == '__main__': multiprocessing.log_to_stderr(logging.DEBUG) p = multiprocessing.Process(target=worker) p.start() p.join()
默认的,日志级别被设置为NOTSET,即不产生任何消息。通过传入一个不同的日志级别,可以初始化日志记录器并指定所需的详细程度。

若要直接处理日志记录器(修改其日志级别或增加处理器),可以使用get_logger()。
import multiprocessing import logging import sys def worker(): print('Doing some work') sys.stdout.flush() if __name__ == '__main__': multiprocessing.log_to_stderr() logger = multiprocessing.get_logger() logger.setLevel(logging.INFO) p = multiprocessing.Process(target=worker) p.start() p.join()
使用名multiprocessing,还可以通过logging配置文件API来配置日志记录器。

1.9 派生进程
要在一个单独的进程中开始工作,尽管最简单的方法是使用Process并传人一个目标函数,但也可以使用一个定制子类。
import multiprocessing class Worker(multiprocessing.Process): def run(self): print('In {}'.format(self.name)) return if __name__ == '__main__': jobs = [] for i in range(5): p = Worker() jobs.append(p) p.start() for j in jobs: j.join()
派生类应当覆盖run()以完成工作。

1.10 向进程传递消息
类似于线程,对于多个进程,一种常见的使用模式是将一个工作划分到多个工作进程中并行地运行。要想有效地使用多个进程,通常要求它们之间有某种通信,这样才能分解工作,并完成结果的聚集。利用multiprocessing完成进程间通信的一种简单方法是使用一个Queue来回传递消息。能够用pickle串行化的任何对象都可以通过Queue传递。
import multiprocessing class MyFancyClass: def __init__(self, name): self.name = name def do_something(self): proc_name = multiprocessing.current_process().name print('Doing something fancy in {} for {}!'.format( proc_name, self.name)) def worker(q): obj = q.get() obj.do_something() if __name__ == '__main__': queue = multiprocessing.Queue() p = multiprocessing.Process(target=worker, args=(queue,)) p.start() queue.put(MyFancyClass('Fancy Dan')) # Wait for the worker to finish queue.close() queue.join_thread() p.join()
这个小例子只是向一个工作进程传递一个消息,然后主进程等待这个工作进程完成。

来看一个更复杂的例子,这里展示了如何管理多个工作进程,它们都消费一个JoinableQueue的数据,并把结果传递回父进程。这里使用“毒药”技术来停止工作进程。建立具体任务后,主程序会在作业队列中为每个工作进程增加一个“stop”值。当一个工作进程遇到这个特定值时,就会退出其处理循环。主进程使用任务队列的join()方法等待所有任务都完成后才开始处理结果。
import multiprocessing import time class Consumer(multiprocessing.Process): def __init__(self, task_queue, result_queue): multiprocessing.Process.__init__(self) self.task_queue = task_queue self.result_queue = result_queue def run(self): proc_name = self.name while True: next_task = self.task_queue.get() if next_task is None: # Poison pill means shutdown print('{}: Exiting'.format(proc_name)) self.task_queue.task_done() break print('{}: {}'.format(proc_name, next_task)) answer = next_task() self.task_queue.task_done() self.result_queue.put(answer) class Task: def __init__(self, a, b): self.a = a self.b = b def __call__(self): time.sleep(0.1) # pretend to take time to do the work return '{self.a} * {self.b} = {product}'.format( self=self, product=self.a * self.b) def __str__(self): return '{self.a} * {self.b}'.format(self=self) if __name__ == '__main__': # Establish communication queues tasks = multiprocessing.JoinableQueue() results = multiprocessing.Queue() # Start consumers num_consumers = multiprocessing.cpu_count() * 2 print('Creating {} consumers'.format(num_consumers)) consumers = [ Consumer(tasks, results) for i in range(num_consumers) ] for w in consumers: w.start() # Enqueue jobs num_jobs = 10 for i in range(num_jobs): tasks.put(Task(i, i)) # Add a poison pill for each consumer for i in range(num_consumers): tasks.put(None) # Wait for all of the tasks to finish tasks.join() # Start printing results while num_jobs: result = results.get() print('Result:', result) num_jobs -= 1
尽管作业按顺序进入队列,但它们的执行却是并行的,所以不能保证它们完成的顺序。


1.11 进程间信号传输
Event类提供了一种简单的方法,可以在进程之间传递状态信息。事件可以在设置状态和未设置状态之间切换。通过使用一个可选的超时值,事件对象的用户可以等待其状态从未设置变为设置。
import multiprocessing import time def wait_for_event(e): """Wait for the event to be set before doing anything""" print('wait_for_event: starting') e.wait() print('wait_for_event: e.is_set()->', e.is_set()) def wait_for_event_timeout(e, t): """Wait t seconds and then timeout""" print('wait_for_event_timeout: starting') e.wait(t) print('wait_for_event_timeout: e.is_set()->', e.is_set()) if __name__ == '__main__': e = multiprocessing.Event() w1 = multiprocessing.Process( name='block', target=wait_for_event, args=(e,), ) w1.start() w2 = multiprocessing.Process( name='nonblock', target=wait_for_event_timeout, args=(e, 2), ) w2.start() print('main: waiting before calling Event.set()') time.sleep(3) e.set() print('main: event is set')
wait()到时间时就会返回,而且没有任何错误。调用者负责使用is_set()检查事件的状态。

1.12 控制资源访问
如果需要在多个进程间共享一个资源,那么在这种情况下,可以使用一个Lock来避免访问冲突。
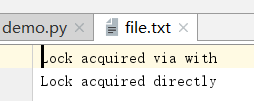
import multiprocessing def worker_with(lock, f): with lock: fs = open(f, "a+") fs.write('Lock acquired via with ') fs.close() def worker_no_with(lock, f): lock.acquire() try: fs = open(f, "a+") fs.write('Lock acquired directly ') fs.close() finally: lock.release() if __name__ == "__main__": f = "file.txt" lock = multiprocessing.Lock() w = multiprocessing.Process(target=worker_with, args=(lock, f)) nw = multiprocessing.Process(target=worker_no_with, args=(lock, f)) w.start() nw.start() w.join() nw.join()
在这个例子中,如果这两个进程没有用锁同步其输出流访问,那么打印到控制台的消息可能会纠结在一起。
1.13 同步操作
可以用Condition对象来同步一个工作流的各个部分,使其中一些部分并行运行,而另外一些顺序运行,即使它们在不同的进程中。
import multiprocessing import time def stage_1(cond): """perform first stage of work, then notify stage_2 to continue """ name = multiprocessing.current_process().name print('Starting', name) with cond: print('{} done and ready for stage 2'.format(name)) cond.notify_all() def stage_2(cond): """wait for the condition telling us stage_1 is done""" name = multiprocessing.current_process().name print('Starting', name) with cond: cond.wait() print('{} running'.format(name)) if __name__ == '__main__': condition = multiprocessing.Condition() s1 = multiprocessing.Process(name='s1', target=stage_1, args=(condition,)) s2_clients = [ multiprocessing.Process( name='stage_2[{}]'.format(i), target=stage_2, args=(condition,), ) for i in range(1, 3) ] for c in s2_clients: c.start() time.sleep(1) s1.start() s1.join() for c in s2_clients: c.join()
在这个例子,两个进程并行的运行一个作业的第二阶段,但前提是第一阶段已经完成。

1.14 控制资源的并发访问
有时可能需要允许多个工作进程同时访问一个资源,但要限制总数。这时候我们就可以使用Semaphore来管理。
import multiprocessing import time def worker(s, i): s.acquire() print(multiprocessing.current_process().name + " acquire") time.sleep(i) print(multiprocessing.current_process().name + " release") s.release() if __name__ == "__main__": s = multiprocessing.Semaphore(2) for i in range(5): p = multiprocessing.Process(target=worker, args=(s, i * 2)) p.start()

1.15 管理共享状态
Manager负责协调其所有用户之间共享的信息状态。
import multiprocessing def worker(d, key, value): d[key] = value if __name__ == '__main__': mgr = multiprocessing.Manager() d = mgr.dict() jobs = [ multiprocessing.Process( target=worker, args=(d, i, i * 2), ) for i in range(10) ] for j in jobs: j.start() for j in jobs: j.join() print('Results:', d)
因为这个列表是通过管理器创建的,所以它会由所有进程共享,所有进程都能看到这个列表的更新。除了列表,管理器还支持字典。
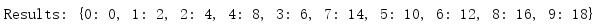
1.16 共享命名空间
除了字典和列表,Manager还可以创建一个共享Namespace。
import multiprocessing def producer(ns, event): ns.value = 'This is the value' event.set() def consumer(ns, event): try: print('Before event: {}'.format(ns.value)) except Exception as err: print('Before event, error:', str(err)) event.wait() print('After event:', ns.value) if __name__ == '__main__': mgr = multiprocessing.Manager() namespace = mgr.Namespace() event = multiprocessing.Event() p = multiprocessing.Process( target=producer, args=(namespace, event), ) c = multiprocessing.Process( target=consumer, args=(namespace, event), ) c.start() p.start() c.join() p.join()
增加到Namespace的所有命名值对所有接收Namespace实例的客户都可见。

对命名空间中可变值内容的更新不会自动传播。
import multiprocessing def producer(ns, event): # DOES NOT UPDATE GLOBAL VALUE! ns.my_list.append('This is the value') event.set() def consumer(ns, event): print('Before event:', ns.my_list) event.wait() print('After event :', ns.my_list) if __name__ == '__main__': mgr = multiprocessing.Manager() namespace = mgr.Namespace() namespace.my_list = [] event = multiprocessing.Event() p = multiprocessing.Process( target=producer, args=(namespace, event), ) c = multiprocessing.Process( target=consumer, args=(namespace, event), ) c.start() p.start() c.join() p.join()
要更新这个列表,需要将它再次关联到命名空间对象。

1.17 进程池
有些情况下,所要完成的工作可以分解并独立地分布到多个工作进程,对于这种简单的情况,可以用Pool类来管理固定数目的工作进程。会收集各个作业的返回值并作为一个列表返回。池(pool)参数包括进程数以及启动任务进程时要运行的函数(对每个子进程调用一次)。
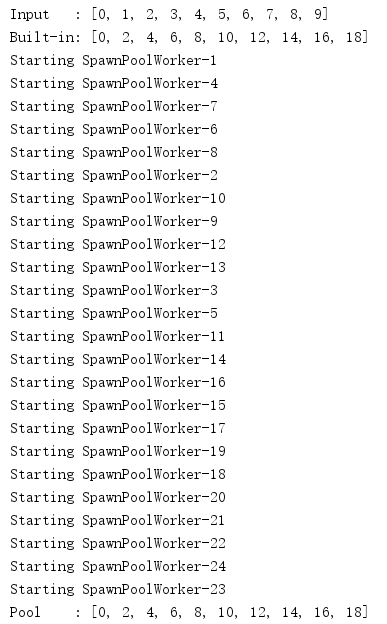
import multiprocessing def do_calculation(data): return data * 2 def start_process(): print('Starting', multiprocessing.current_process().name) if __name__ == '__main__': inputs = list(range(10)) print('Input :', inputs) builtin_outputs = list(map(do_calculation, inputs)) print('Built-in:', builtin_outputs) pool_size = multiprocessing.cpu_count() * 2 pool = multiprocessing.Pool( processes=pool_size, initializer=start_process, ) pool_outputs = pool.map(do_calculation, inputs) pool.close() # no more tasks pool.join() # wrap up current tasks print('Pool :', pool_outputs)
map()方法的结果在功能上等价于内置map()的结果,只不过各个任务会并行运行。由于进程池并行地处理输入,可以用close()和join()使任务进程与主进程同步,以确保完成适当的清理。
默认的,Pool会创建固定数目的工作进程,并向这些工作进程传递作业,直到再没有更多作业为止。设置maxtasksperchild参数可以告诉池在完成一些任务之后要重新启动一个工作进程,来避免长时间运行的工作进程消耗更多的系统资源。
import multiprocessing def do_calculation(data): return data * 2 def start_process(): print('Starting', multiprocessing.current_process().name) if __name__ == '__main__': inputs = list(range(10)) print('Input :', inputs) builtin_outputs = list(map(do_calculation, inputs)) print('Built-in:', builtin_outputs) pool_size = multiprocessing.cpu_count() * 2 pool = multiprocessing.Pool( processes=pool_size, initializer=start_process, maxtasksperchild=2, ) pool_outputs = pool.map(do_calculation, inputs) pool.close() # no more tasks pool.join() # wrap up current tasks print('Pool :', pool_outputs)
池完成其分配的任务时,即使并没有更多工作要做,也会重新启动工作进程。从下面的输出可以看到,尽管只有10个任务,而且每个工作进程一次可以完成两个任务,但是这里创建了8个工作进程。