原文:https://zhuanlan.zhihu.com/p/343747724
Python的集合(collections)模块,为很多用其他方法很难实现的场景提供了解决方案。本文我们将会学习该模块的抽象概念是如何产生的,日后处理不同问题的过程中迟早会用得到这些知识。
免责声明:这篇文章是关于Python的一个相当高级的特性。如果你刚入门,建议先收藏,请等一等再学!
一、模块概述
1、模块作用
官方说法:collections模块实现了特定目标的容器,以提供Python标准内建容器dict ,list , set , 和tuple的替代选择。
通俗说法:Python内置的数据类型和方法,collections模块在这些内置类型的基础提供了额外的高性能数据类型,比如基础的字典是不支持顺序的,collections模块的OrderedDict类构建的字典可以支持顺序,collections模块的这些扩展的类用处非常大,熟练掌握该模块,可以大大简化Python代码,提高Python代码逼格和效率,高手入门必备。
2、模块资料
关于该模块,官方的参考资料写的非常详细,也很有价值,大家可以参考
中文文档:https://docs.python.org/zh-cn/3/library/collections.html#module-collections
英文文档:https://docs.python.org/3/library/collections.html#module-collections
3、模块子类
用collections.__all__查看所有的子类,一共包含9个
import collections
print(collections.__all__)
['deque', 'defaultdict', 'namedtuple', 'UserDict', 'UserList',
'UserString', 'Counter', 'OrderedDict', 'ChainMap']这个模块实现了特定目标的容器,以提供Python标准内建容器dict , list , set , 和tuple 的替代选择。
| namedtuple() | 创建命名元组子类的工厂函数,生成可以使用名字来访问元素内容的tuple子类 |
| deque | 类似列表(list)的容器,实现了在两端快速添加(append)和弹出(pop) |
| ChainMap | 类似字典(dict)的容器类,将多个映射集合到一个视图里面 |
| Counter | 字典的子类,提供了可哈希对象的计数功能 |
| OrderedDict | 字典的子类,保存了他们被添加的顺序,有序字典 |
| defaultdict | 字典的子类,提供了一个工厂函数,为字典查询提供一个默认值 |
| UserDict | 封装了字典对象,简化了字典子类化 |
| UserList | 封装了列表对象,简化了列表子类化 |
| UserString | 封装了字符串对象,简化了字符串子类化(中文版翻译有误) |
二、计数器-Counter
1、基础介绍
一个计数器工具提供快速和方便的计数,Counter是一个dict的子类,用于计数可哈希对象。它是一个集合,元素像字典键(key)一样存储,它们的计数存储为值。计数可以是任何整数值,包括0和负数,Counter类有点像其他语言中的bags或multisets。简单说,就是可以统计计数,来几个例子看看就清楚了,比如
#计算top10的单词
from collections import Counter
import re
text = 'remove an existing key one level down remove an existing key one level down'
words = re.findall(r'\w+', text)
Counter(words).most_common(10)
[('remove', 2),('an', 2),('existing', 2),('key', 2),('one', 2)('level', 2),('down', 2)]
#计算列表中单词的个数
cnt = Counter()
for word in ['red', 'blue', 'red', 'green', 'blue', 'blue']:
cnt[word] += 1
cnt
Counter({'red': 2, 'blue': 3, 'green': 1})
#上述这样计算有点嘛,下面的方法更简单,直接计算就行
L = ['red', 'blue', 'red', 'green', 'blue', 'blue']
Counter(L)
Counter({'red': 2, 'blue': 3, 'green': 1}元素从一个iterable 被计数或从其他的mapping (or counter)初始化:
from collections import Counter
#字符串计数
Counter('gallahad')
Counter({'g': 1, 'a': 3, 'l': 2, 'h': 1, 'd': 1})
#字典计数
Counter({'red': 4, 'blue': 2})
Counter({'red': 4, 'blue': 2})
#是个啥玩意计数
Counter(cats=4, dogs=8)
Counter({'cats': 4, 'dogs': 8})
Counter(['red', 'blue', 'red', 'green', 'blue', 'blue'])
Counter({'red': 2, 'blue': 3, 'green': 1})计数器对象除了字典方法以外,还提供了三个其他的方法:
1、elements()
描述:返回一个迭代器,其中每个元素将重复出现计数值所指定次。 元素会按首次出现的顺序返回。 如果一个元素的计数值小于1,elements() 将会忽略它。
语法:elements( )
参数:无
c = Counter(a=4, b=2, c=0, d=-2)
list(c.elements())
['a', 'a', 'a', 'a', 'b', 'b']
sorted(c.elements())
['a', 'a', 'a', 'a', 'b', 'b']
c = Counter(a=4, b=2, c=0, d=5)
list(c.elements())
['a', 'a', 'a', 'a', 'b', 'b', 'd', 'd', 'd', 'd', 'd']2、most_common()
返回一个列表,其中包含n个最常见的元素及出现次数,按常见程度由高到低排序。 如果 n 被省略或为None,most_common() 将返回计数器中的所有元素,计数值相等的元素按首次出现的顺序排序,经常用来计算top词频的词语。
Counter('abracadabra').most_common(3)
[('a', 5), ('b', 2), ('r', 2)]
Counter('abracadabra').most_common(5)
[('a', 5), ('b', 2), ('r', 2), ('c', 1), ('d', 1)]3、subtract()
从迭代对象或映射对象减去元素。像dict.update() 但是是减去,而不是替换。输入和输出都可以是0或者负数。
c = Counter(a=4, b=2, c=0, d=-2)
d = Counter(a=1, b=2, c=3, d=4)
c.subtract(d)
c
Counter({'a': 3, 'b': 0, 'c': -3, 'd': -6})
#减去一个abcd
str0 = Counter('aabbccdde')
str0
Counter({'a': 2, 'b': 2, 'c': 2, 'd': 2, 'e': 1})
str0.subtract('abcd')
str0
Counter({'a': 1, 'b': 1, 'c': 1, 'd': 1, 'e': 1}4、字典方法
通常字典方法都可用于Counter对象,除了有两个方法工作方式与字典并不相同。
fromkeys(iterable)
这个类方法没有在Counter中实现。
update([iterable-or-mapping])
从迭代对象计数元素或者从另一个映射对象 (或计数器) 添加。 像 dict.update() 但是是加上,而不是替换。另外,迭代对象应该是序列元素,而不是一个 (key, value) 对。
sum(c.values()) # total of all counts
c.clear() # reset all counts
list(c) # list unique elements
set(c) # convert to a set
dict(c) # convert to a regular dictionary
c.items() # convert to a list of (elem, cnt) pairs
Counter(dict(list_of_pairs)) # convert from a list of (elem, cnt) pairs
c.most_common()[:-n-1:-1] # n least common elements
+c # remove zero and negative counts5、数学操作
这个功能非常强大,提供了几个数学操作,可以结合 Counter 对象,以生产 multisets (计数器中大于0的元素)。 加和减,结合计数器,通过加上或者减去元素的相应计数。交集和并集返回相应计数的最小或最大值。每种操作都可以接受带符号的计数,但是输出会忽略掉结果为零或者小于零的计数。
c = Counter(a=3, b=1)
d = Counter(a=1, b=2)
c + d # add two counters together: c[x] + d[x]
Counter({'a': 4, 'b': 3})
c - d # subtract (keeping only positive counts)
Counter({'a': 2})
c & d # intersection: min(c[x], d[x])
Counter({'a': 1, 'b': 1})
c | d # union: max(c[x], d[x])
Counter({'a': 3, 'b': 2})单目加和减(一元操作符)意思是从空计数器加或者减去。
c = Counter(a=2, b=-4)
+c
Counter({'a': 2})
-c
Counter({'b': 4})写一个计算文本相似的算法,加权相似
def str_sim(str_0,str_1,topn):
topn = int(topn)
collect0 = Counter(dict(Counter(str_0).most_common(topn)))
collect1 = Counter(dict(Counter(str_1).most_common(topn)))
jiao = collect0 & collect1
bing = collect0 | collect1
sim = float(sum(jiao.values()))/float(sum(bing.values()))
return(sim)
str_0 = '定位手机定位汽车定位GPS定位人定位位置查询'
str_1 = '导航定位手机定位汽车定位GPS定位人定位位置查询'
str_sim(str_0,str_1,5)
0.75 二、双向队列-deque
双端队列,可以快速的从另外一侧追加和推出对象,deque是一个双向链表,针对list连续的数据结构插入和删除进行优化。它提供了两端都可以操作的序列,这表示在序列的前后你都可以执行添加或删除操作。双向队列(deque)对象支持以下方法:
1、append()
添加 x 到右端。
d = deque('ghi')
d.append('j')
d
deque(['g', 'h', 'i', 'j'])2、appendleft()
添加 x 到左端。
d.appendleft('f')
d
deque(['f', 'g', 'h', 'i', 'j'])3、clear()
移除所有元素,使其长度为0.
d = deque('ghi')
d.clear()
d
deque([])4、copy()
创建一份浅拷贝。
d = deque('xiaoweuge')
y = d.copy()
print(y)
deque(['x', 'i', 'a', 'o', 'w', 'e', 'u', 'g', 'e'])5、count()
计算 deque 中元素等于 x 的个数。
d = deque('xiaoweuge-shuai')
d.count('a')
26、extend()
扩展deque的右侧,通过添加iterable参数中的元素。
a = deque('abc')
b = deque('cd')
a.extend(b)
a
deque(['a', 'b', 'c', 'c', 'd'])
与append 的区别
a = deque('abc')
b = deque('cd')
a.append(b)
deque(['a', 'b', 'c', deque(['c', 'd'])])7、extendleft()
扩展deque的左侧,通过添加iterable参数中的元素。注意,左添加时,在结果中iterable参数中的顺序将被反过来添加。
a = deque('abc')
b = deque('cd')
a.extendleft(b)
a
deque(['d', 'c', 'a', 'b', 'c'])8、index()
返回 x 在 deque 中的位置(在索引 start 之后,索引 stop 之前)。 返回第一个匹配项,如果未找到则引发 ValueError。
d = deque('xiaoweuge')
d.index('w')
49、insert()
在位置 i 插入 x 。
如果插入会导致一个限长 deque 超出长度 maxlen 的话,就引发一个 IndexError。
a = deque('abc')
a.insert(1,'X')
deque(['a', 'X', 'b', 'c'])10、pop()
移去并且返回一个元素,deque 最右侧的那一个。 如果没有元素的话,就引发一个 IndexError。
d.pop()
'j'11、popleft()
移去并且返回一个元素,deque 最左侧的那一个。 如果没有元素的话,就引发 IndexError。
d.popleft()
'f'12、remove(value)
移除找到的第一个 value。 如果没有的话就引发 ValueError。
a = deque('abca')
a.remove('a')
a
deque(['b', 'c', 'a'])13、reverse()
将deque逆序排列。返回 None 。
#逆序排列
d = deque('ghi') # 创建一个deque
list(reversed(d))
['i', 'h', 'g']
deque(reversed(d))
deque(['i', 'h', 'g'])14、rotate(n=1)
向右循环移动 n 步。 如果 n 是负数,就向左循环。
如果deque不是空的,向右循环移动一步就等价于 d.appendleft(d.pop()) , 向左循环一步就等价于 d.append(d.popleft()) 。
# 向右边挤一挤
d = deque('ghijkl')
d.rotate(1)
d
deque(['l', 'g', 'h', 'i', 'j', 'k'])
# 向左边挤一挤
d.rotate(-1)
d
deque(['g', 'h', 'i', 'j', 'k', 'l'])
#看一个更明显的
x = deque('12345')
x
deque(['1', '2', '3', '4', '5'])
x.rotate()
x
deque(['5', '1', '2', '3', '4'])
d = deque(['12','av','cd'])
d.rotate(1)
deque(['cd', '12', 'av'15、maxlen
Deque的最大尺寸,如果没有限定的话就是 None 。
from collections import deque
d=deque(maxlen=10)
for i in range(20):
d.append(i)
d
deque([10, 11, 12, 13, 14, 15, 16, 17, 18, 19])除了以上操作,deque还支持迭代、封存、len(d)、reversed(d)、copy.deepcopy(d)、copy.copy(d)、成员检测运算符 in 以及下标引用例如通过 d[0] 访问首个元素等。 索引访问在两端的复杂度均为 O(1) 但在中间则会低至 O(n)。 如需快速随机访问,请改用列表。
Deque从版本3.5开始支持 __add__(), __mul__(), 和 __imul__() 。
from collections import deque
d = deque('ghi') # 创建一个deque
for elem in d:
print(elem.upper())
G
H
I
#从右边添加一个元素
d.append('j')
d
deque(['g', 'h', 'i', 'j'])
#从左边添加一个元素
d.appendleft('f')
d
deque(['f', 'g', 'h', 'i', 'j'])
#右边删除
d.pop()
'j'
#左边边删除
d.popleft()
'f'
#看看还剩下啥
list(d) #
['g', 'h', 'i']
#成员检测
'h' in d
True
#添加多个元素
d.extend('jkl')
d
deque(['g', 'h', 'i', 'j', 'k', 'l'])
d.clear() # empty the deque
d.pop() # cannot pop from an empty deque
Traceback (most recent call last):
File "<pyshell#6>", line 1, in -toplevel-
d.pop()
IndexError: pop from an empty deque
d.extendleft('abc') # extendleft() reverses the input order
d
deque(['c', 'b', 三、有序字典-OrderedDict
有序词典就像常规词典一样,但有一些与排序操作相关的额外功能,popitem() 方法有不同的签名。它接受一个可选参数来指定弹出哪个元素。move_to_end() 方法,可以有效地将元素移动到任一端。
有序词典就像常规词典一样,但有一些与排序操作相关的额外功能。由于内置的 dict 类获得了记住插入顺序的能力(在 Python 3.7 中保证了这种新行为),它们变得不那么重要了。
一些与 dict 的不同仍然存在:
- 常规的 dict 被设计为非常擅长映射操作。 跟踪插入顺序是次要的。
- OrderedDict 旨在擅长重新排序操作。 空间效率、迭代速度和更新操作的性能是次要的。
- 算法上, OrderedDict 可以比 dict 更好地处理频繁的重新排序操作。 这使其适用于跟踪最近的访问(例如在 LRU cache 中)。
- 对于 OrderedDict ,相等操作检查匹配顺序。
- OrderedDict 类的 popitem() 方法有不同的签名。它接受一个可选参数来指定弹出哪个元素。
- OrderedDict 类有一个 move_to_end() 方法,可以有效地将元素移动到任一端。
- Python 3.8之前, dict 缺少 __reversed__() 方法。
| 传统字典方法 | OrderedDict方法 | 差异 |
| clear | clear | |
| copy | copy | |
| fromkeys | fromkeys | |
| get | get | |
| items | items | |
| keys | keys | |
| pop | pop | |
| popitem | popitem | OrderedDict 类的 popitem() 方法有不同的签名。它接受一个可选参数来指定弹出哪个元素。 |
| setdefault | setdefault | |
| update | update | |
| values | values | |
| move_to_end | 可以有效地将元素移动到任一端。 |
1、popitem
语法:popitem(last=True)
功能:有序字典的 popitem() 方法移除并返回一个 (key, value) 键值对。 如果 last 值为真,则按 LIFO 后进先出的顺序返回键值对,否则就按 FIFO 先进先出的顺序返回键值对。
from collections import OrderedDict
d = OrderedDict.fromkeys('abcde')
d.popitem()
('e', None)
d
OrderedDict([('a', None), ('b', None), ('c', None), ('d', None)])
#last=False时,弹出第一个
d = OrderedDict.fromkeys('abcde')
''.join(d.keys())
'abcde'
d.popitem(last=False)
''.join(d.keys())
'bcde'2、move_to_end
from collections import OrderedDict
d = OrderedDict.fromkeys('abcde')
d.move_to_end('b')
''.join(d.keys())
'acdeb'
d
OrderedDict([('a', None), ('c', None), ('d', None), ('e', None), ('b', None)])
d.move_to_end('b', last=False)
''.join(d.keys())
'bacde'3、reversed()
相对于通常的映射方法,有序字典还另外提供了逆序迭代的支持,通过reversed() 。
d = OrderedDict.fromkeys('abcde')
list(reversed(d))
['e', 'd', 'c', 'b', 'a']四、可命名元组-namedtuple
生成可以使用名字来访问元素内容的tuple子类,命名元组赋予每个位置一个含义,提供可读性和自文档性。它们可以用于任何普通元组,并添加了通过名字获取值的能力,通过索引值也是可以的。
1、参数介绍
namedtuple(typename,field_names,*,verbose=False, rename=False, module=None)
1)typename:该参数指定所创建的tuple子类的类名,相当于用户定义了一个新类。
2)field_names:该参数是一个字符串序列,如 ['x','y']。此外,field_names 也可直接使用单个字符串代表所有字段名,多个字段名用空格、逗号隔开,如 'x y' 或 'x,y'。任何有效的 Python 标识符都可作为字段名(不能以下画线开头)。有效的标识符可由字母、数字、下画线组成,但不能以数字、下面线开头,也不能是关键字(如 return、global、pass、raise 等)。
3)rename:如果将该参数设为 True,那么无效的字段名将会被自动替换为位置名。例如指定 ['abc','def','ghi','abc'],它将会被替换为 ['abc', '_1','ghi','_3'],这是因为 def 字段名是关键字,而 abc 字段名重复了。
4)verbose:如果该参数被设为 True,那么当该子类被创建后,该类定义就被立即打印出来。
5)module:如果设置了该参数,那么该类将位于该模块下,因此该自定义类的 __module__ 属性将被设为该参数值。
2、应用案例
1)水族箱案例
Python元组是一个不可变的,或不可改变的,有序的元素序列。元组经常用来表示纵列数据;例如,一个CSV文件中的行数或一个SQL数据库中的行数。一个水族箱可以用一系列元组来记录它的鱼类的库存。
一个单独的鱼类元组:

这个元组由三个字符串元素组成。
虽然在某些方面很有用,但是这个元组并没有清楚地指明它的每个字段代表什么。实际上,元素0是一个名称,元素1是一个物种,元素2是一个饲养箱。
鱼类元组字段说明:

这个表清楚地表明,该元组的三个元素都有明确的含义。
来自collections模块的namedtuple允许你向一个元组的每个元素添加显式名称,以便在你的Python程序中明确这些元素的含义。
让我们使用namedtuple来生成一个类,从而明确地命名鱼类元组的每个元素:

from collections import namedtuple 可以让你的Python程序访问namedtuple工厂函数。namedtuple()函数调用会返回一个绑定到名称Fish的类。namedtuple()函数有两个参数:我们的新类“Fish”的期望名称和命名元素["name"、"species”、“tank"]的一个列表。
我们可以使用Fish类来表示前面的鱼类元组:

如果我们运行这段代码,我们将看到以下输出:

sammy是使用Fish类进行实例化的。sammy是一个具有三个明确命名元素的元组。
sammy的字段可以通过它们的名称或者一个传统的元组索引来访问:

如果我们运行这两个print调用,我们将看到以下输出:

访问.species会返回与使用[1]访问sammy的第二个元素相同的值。
使用collections模块中的namedtuple可以在维护元组(即它们是不可变的、有序的)的重要属性的同时使你的程序更具可读性。
此外,namedtuple工厂函数还会向Fish实例添加几个额外的方法。
使用._asdict()将一个实例转换为字典:

如果我们运行print,你会看到如下输出:

在sammy上调用.asdict()将返回一个字典,该字典会将三个字段名称分别映射到它们对应的值。
大于3.8的Python版本输出这一行的方式可能略有不同。例如,你可能会看到一个OrderedDict,而不是这里显示的普通字典。
2)加法器案例
from collections import namedtuple
# 定义命名元组类:Point
Point = namedtuple('Point', ['x', 'y'])
# 初始化Point对象,即可用位置参数,也可用命名参数
p = Point(11, y=22)
# 像普通元组一样用根据索引访问元素
print(p[0] + p[1])
33
#执行元组解包,按元素的位置解包
a, b = p
print(a, b)
11, 22
#根据字段名访问各元素
print(p.x + p.y)
33
print(p)
Point(x=11, y=22)3、三个方法
备注: 在Python中,带有前导下划线的方法通常被认为是“私有的”。但是,namedtuple提供的其他方法(如._asdict()、._make()、._replace()等)是公开的。
除了继承元组的方法,命名元组还支持三个额外的方法和两个属性。为了防止字段名冲突,方法和属性以下划线开始。
_make(iterable)
类方法从存在的序列或迭代实例创建一个新实例。
t = [14, 55]
Point._make(t)_asdict()
返回一个新的 dict ,它将字段名称映射到它们对应的值:
p = Point(x=11, y=22)
p._asdict()
OrderedDict([('x', 11), ('y', 22)])_replace(**kwargs)
返回一个新的命名元组实例,并将指定域替换为新的值
p = Point(x=11, y=22)
p._replace(x=33)
Point(x=33, y=22)4、两个属性
_fields
字符串元组列出了字段名。用于提醒和从现有元组创建一个新的命名元组类型。
p._fields # view the field names
('x', 'y')
Color = namedtuple('Color', 'red green blue')
Pixel = namedtuple('Pixel', Point._fields + Color._fields)
Pixel(11, 22, 128, 255, 0)
Pixel(x=11, y=22, red=128, green=255, blue=0)_field_defaults
字典将字段名称映射到默认值。
Account = namedtuple('Account', ['type', 'balance'], defaults=[0])
Account._field_defaults
{'balance': 0}
Account('premium')
Account(type='premium', balance=0)5、其他函数
getattr()
要获取这个名字域的值,使用 getattr() 函数 :
getattr(p, 'x')
11转换一个字典到命名元组,使用 ** 两星操作符
d = {'x': 11, 'y': 22}
Point(**d)
Point(x=11, y=22)因为一个命名元组是一个正常的Python类,它可以很容易的通过子类更改功能。这里是如何添加一个计算域和定宽输出打印格式:
class Point(namedtuple('Point', ['x', 'y'])):
__slots__ = ()
@property
def hypot(self):
return (self.x ** 2 + self.y ** 2) ** 0.5
def __str__(self):
return 'Point: x=%6.3f y=%6.3f hypot=%6.3f' % (self.x, self.y, self.hypot)
for p in Point(3, 4), Point(14, 5/7):
print(p)
Point: x= 3.000 y= 4.000 hypot= 5.000
Point: x=14.000 y= 0.714 hypot=14.018五、默认字典-defaultdict
在Python字典中收集数据通常是很有用的。
在字典中获取一个 key 有两种方法, 第一种 get , 第二种 通过 [] 获取.
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict。
当我使用普通的字典时,用法一般是dict={},添加元素的只需要dict[element] =value即,调用的时候也是如此,dict[element] = xxx,但前提是element字典里,如果不在字典里就会报错
这时defaultdict就能排上用场了,defaultdict的作用是在于,当字典里的key不存在但被查找时,返回的不是keyError而是一个默认值,这个默认值是什么呢,下面会说
1、基础介绍
defaultdict([default_factory[, ...]])
返回一个新的类似字典的对象。 defaultdict是内置dict类的子类。它重载了一个方法并添加了一个可写的实例变量。其余的功能与dict类相同,此处不再重复说明。
本对象包含一个名为default_factory的属性,构造时,第一个参数用于为该属性提供初始值,默认为 None。所有其他参数(包括关键字参数)都相当于传递给 dict 的构造函数。
defaultdict 对象除了支持标准 dict 的操作,还支持以下方法作为扩展:
__missing__(key)
如果 default_factory 属性为 None,则调用本方法会抛出 KeyError 异常,附带参数 key。
如果 default_factory 不为 None,则它会被(不带参数地)调用来为 key 提供一个默认值,这个值和 key 作为一对键值对被插入到字典中,并作为本方法的返回值返回。
如果调用 default_factory 时抛出了异常,这个异常会原封不动地向外层传递。
在无法找到所需键值时,本方法会被 dict 中的 __getitem__() 方法调用。无论本方法返回了值还是抛出了异常,都会被 __getitem__() 传递。
注意,__missing__() 不会 被 __getitem__() 以外的其他方法调用。意味着 get() 会像正常的 dict 那样返回 None,而不是使用 default_factory。
2、示例介绍
使用 list 作为 default_factory,很轻松地将(键-值对组成的)序列转换为(键-列表组成的)字典
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d = defaultdict(list)
for k, v in s:
d[k].append(v)
sorted(d.items())
[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]当每个键第一次遇见时,它还没有在字典里面,所以自动创建该条目,即调用default_factory方法,返回一个空的 list。 list.append() 操作添加值到这个新的列表里。当再次存取该键时,就正常操作,list.append() 添加另一个值到列表中。这个计数比它的等价方法dict.setdefault()要快速和简单:
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d = {}
for k, v in s:
d.setdefault(k, []).append(v)
sorted(d.items())
[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]设置 default_factory为int,使defaultdict用于计数(类似其他语言中的 bag或multiset):
s = 'mississippi'
d = defaultdict(int)
for k in s:
d[k] += 1
sorted(d.items())
[('i', 4), ('m', 1), ('p', 2), ('s', 4)]设置 default_factory 为 set 使 defaultdict 用于构建 set 集合:
s = [('red', 1), ('blue', 2), ('red', 3), ('blue', 4), ('red', 1), ('blue', 4)]
d = defaultdict(set)
for k, v in s:
d[k].add(v)
sorted(d.items())
[('blue', {2, 4}), ('red', {1, 3})]defaultdict绝不会引发一个KeyError。如果一个键不存在,defaultdict会插入并返回一个占位符值来代替:

如果我们运行这段代码,我们将看到如下输出:

defaultdict会插入并返回一个占位符值,而不是引发一个KeyError。在本例中,我们将占位符值指定为一个列表。
相比之下,常规字典会在缺失的键上引发一个KeyError:

如果我们运行这段代码,我们将看到如下输出:
当我们试图访问一个不存在的键时,常规字典my_regular_dict会引发一个KeyError。
defaultdict的行为与常规字典不同。defaultdict会不带任何参数调用占位符值来创建一个新对象,而不是在缺失的键上引发一个KeyError。在本例中,是调用list()创建一个空列表。
继续我们虚构的水族箱示例,假设我们有一个表示水族箱清单的鱼类元组列表:

水族箱中有三种鱼——它们的名字、种类和饲养箱在这三个元组中都有指出。
我们的目标是按饲养箱组织我们的清单—我们想知道每个饲养箱中存在的鱼的列表。换句话说,我们需要一个能将“tank-a”映射到["Jamie", "Mary"] ,并且将“tank-b”映射到["Jamie"]的字典。
我们可以使用defaultdict来按饲养箱对鱼进行分组:

运行这段代码,我们将看到以下输出:
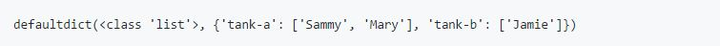
fish_names_by_tank被声明为一个defaultdict,它默认会插入list()而不是引发一个KeyError。由于这保证了fish_names_by_tank中的每个键都将指向一个list,所以我们可以自由地调用.append()来将名称添加到每个饲养箱的列表中。
这里,defaultdict帮助你减少了出现未预期的KeyErrors的机会。减少未预期的KeyErrors意味着你可以用更少的行更清晰地编写你的程序。更具体地说,defaultdict习惯用法让你避免了手动地为每个饲养箱实例化一个空列表。
如果没有 defaultdict, for循环体可能看起来更像这样:
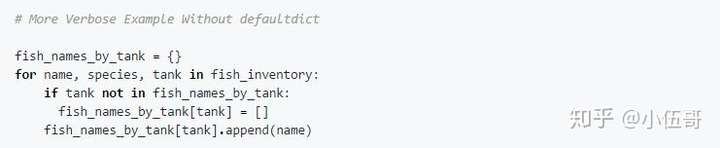
使用常规字典(而不是defaultdict)意味着for循环体总是必须检查fish_names_by_tank中给定的tank是否存在。只有在验证了fish_names_by_tank中已经存在tank,或者已经使用一个[]初始化了tank之后,我们才可以添加鱼类名称。
在填充字典时,defaultdict可以帮助我们减少样板代码,因为它从不引发KeyError。
六、映射链-ChainMap
1、ChainMap是什么
ChainMap最基本的使用,可以用来合并两个或者更多个字典,当查询的时候,从前往后依次查询。
ChainMap:将多个字典视为一个,解锁Python超能力。
ChainMap是由Python标准库提供的一种数据结构,允许你将多个字典视为一个。换句话说:ChainMap是一个基于多dict的可更新的视图,它的行为就像一个普通的dict。
ChainMap类用于快速链接多个映射,以便将它们视为一个单元。它通常比创建新字典和多次调用update()快得多。
你以前可能从来没有听说过ChainMap,你可能会认为ChainMap的使用情况是非常特定的。坦率地说,你是对的。
我知道的用例包括:
- 通过多个字典搜索
- 提供链缺省值
- 经常计算字典子集的性能关键的应用程序
2、特性
1)找到一个就不找了:这个列表是按照第一次搜索到最后一次搜索的顺序组织的,搜索查询底层映射,直到一个键被找到。
2)更新原始映射:不同的是,写,更新和删除只操作第一个映射。
3)支持所有常用字典方法。
简而言之ChainMap:将多个字典视为一个,解锁Python超能力。
Python标准库中的集合模块包含许多为性能而设计的实用的数据结构。著名的包括命名元组或计数器。
今天,通过实例,我们来看看鲜为人知的ChainMap。通过浏览具体的示例,我希望给你一个提示,关于在更高级的Python工作中使用ChainMap将如何从中受益。
3、应用案例-基础案例
from collections import ChainMap
baseline = {'music': 'bach', 'art': 'rembrandt'}
adjustments = {'art': 'van gogh', 'opera': 'carmen'}
ChainMap(adjustments, baseline)
ChainMap({'art': 'van gogh', 'opera': 'carmen'}, {'music': 'bach', 'art': 'rembrandt'})
list(ChainMap(adjustments, baseline))
['music', 'art', 'opera']
#存在重复元素时,也不会去重
dcic1 = {'label1': '11', 'label2': '22'}
dcic2 = {'label2': '22', 'label3': '33'}
dcic3 = {'label4': '44', 'label5': '55'}
last = ChainMap(dcic1, dcic2,dcic3)
last
ChainMap({'label1': '11', 'label2': '22'}, {'label2': '22', 'label3': '33'}, {'label4': '44', 'label5': '55'})new_child()方法
用法:new_child(m=None)
返回一个新的ChainMap类,包含了一个新映射(map),后面跟随当前实例的全部映射map。如果m被指定,它就成为不同新的实例,就是在所有映射前加上 m,如果没有指定,就加上一个空字典,这样的话一个 d.new_child() 调用等价于ChainMap({}, *d.maps) 。这个方法用于创建子上下文,不改变任何父映射的值。
last.new_child(m={'key_new':888})
ChainMap({'key_new': 888}, {'label1': '11', 'label2': '22'}, {'label2': '22', 'label3': '33'}, {'label4': '44', 'label5': '55'})parents属性
属性返回一个新的ChainMap包含所有的当前实例的映射,除了第一个。这样可以在搜索的时候跳过第一个映射。使用的场景类似在 nested scopes 嵌套作用域中使用nonlocal关键词。用例也可以类比内建函数super() 。一个d.parents 的引用等价于ChainMap(*d.maps[1:]) 。
last.parents
ChainMap({'label2': '22', 'label3': '33'}, {'label4': '44', 'label5': '55'})4、应用案例-购物清单
作为使用ChainMap的第一个例子,让我们考虑一张购物清单。我们的清单可能包含玩具,电脑,甚至衣服。所有这些条目都有价格,所以我们将把我们的条目存储在名称价格映射中。
toys = {'Blocks':30,'Monopoly':20}
computers = {'iMac':1000,'Chromebook':1000,'PC':400}
clothing = {'Jeans':40,'T-shirt':10}现在我们可以使用ChainMap在这些不同的集合上建立一个单一的视图:
from collections import ChainMap
inventory = ChainMap(toys,computers,clothing)这使得我们可以查询清单,就像它是一个单一的字典:
inventory['Monopoly']
20
inventory['Jeans']40正如官方文档所述,ChainMap支持所有常用的字典方法。我们可以使用.get()来搜索可能不存在的条目,或者使用 .pop()删除条目。
inventory.get('Blocks-1')
None
inventory.get('Chromebook')
1000
inventory.pop('Blocks')
inventory
ChainMap({'Monopoly': 20}, {'iMac': 1000, 'Chromebook': 1000, 'PC': 400}, {'Jeans': 40, 'T-shirt': 10})如果我们现在把玩具添加到toys字典里,它也将在清单中可用。这是ChainMap的可更新的方面。
toys['Nintendo'] = 20
inventory['Nintendo']
20Oh和ChainMap有一个恰当的字符串表示形式:
str(inventory)
"ChainMap({'Monopoly': 20, 'Nintendo': 20}, {'iMac': 1000, 'Chromebook': 1000, 'PC': 400}, {'Jeans': 40, 'T-shirt': 10})"一个很好的特点是,在我们的例子中,toys, computers和clothing都是在相同的上下文中(解释器),它们可以来自完全不同的模块或包。这是因为ChainMap通过引用存储底层字典。
第一个例子是使用ChainMap一次搜索多个字典。
事实上,当构建ChainMap时,我们所做的就是有效地构建一系列字典。当查找清单中的一个项时,toys首先被查找,然后是computers,最后是clothing。

ChainMap真的只是一个映射链!
实际上,ChainMap的另一个任务是维护链的默认值。
我们将以一个命令行应用程序的例子来说明这是什么意思。
5、应用案例-CLI配置
让我们面对现实,管理命令行应用程序的配置可能是困难的。配置来自多个源:命令行参数、环境变量、本地文件等。
我们通常实施优先级的概念:如果A和B都定义参数P,A的P值将被使用,因为它的优先级高于B。
例如,如果传递了命令行参数,我们可能希望在环境变量上使用命令行参数。如何轻松地管理配置源的优先级?
一个答案是将所有配置源存储在ChainMap中。
因为ChainMap中的查找是按顺序连续地对每个底层映射执行的(按照他们传给构造函数的顺序),所以我们可以很容易地实现我们寻找的优先级。
下面是一个简单的命令行应用程序。调试参数从命令行参数、环境变量或硬编码默认值中提取:
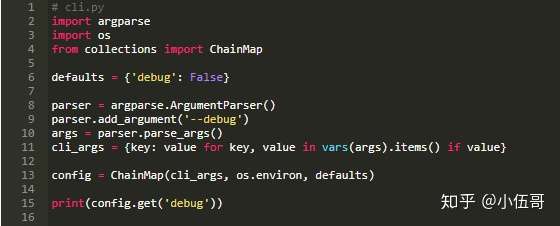
在执行脚本时,我们可以检查是否首先在命令行参数中查找debug,然后是环境变量,最后是默认值:
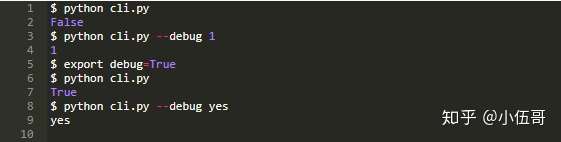
这样看上去就非常整洁,对吧?
6、我为什么关心?
坦率地说,ChainMap是那些你可以忽略的Python特性之一。
还有其他ChainMap的替代方案。例如,使用更新循环—例如创建一个dict并用字典update()它—可能奏效。但是,这只有在您不需要跟踪项目的起源时才有效,就像我们的多源CLI配置示例中的情况一样。但是,当你知道ChainMap存在的时候,ChainMap可以让你更轻松,你的代码更优雅。
7、总结
总而言之,我们一起看了ChainMap是什么,一些具体的使用示例,以及如何在现实生活中,性能关键的应用程序中使用ChainMap。如果您想了解更多关于Python的高性能数据容器的信息,请务必从Python的标准库中collections模块中查看其他出色类和函数。
七、UserDict
UserDict类是用作字典对象的外包装。对这个类的需求已部分由直接创建dict的子类的功能所替代;不过这个类处理起来更容易,因为底层的字典可以作为属性来访问。
模拟一个字典类。这个实例的内容保存为一个正常字典,可以通过UserDict实例的data属性存取。如果提供了initialdata 值, data 就被初始化为它的内容,注意一个 initialdata 的引用不会被保留作为其他用途。
UserDict 实例提供了以下属性作为扩展方法和操作的支持:data一个真实的字典,用于保存 UserDict 类的内容。
八、UserList
这个类封装了列表对象。它是一个有用的基础类,对于你想自定义的类似列表的类,可以继承和覆盖现有的方法,也可以添加新的方法。这样我们可以对列表添加新的行为。
对这个类的需求已部分由直接创建 list 的子类的功能所替代;不过,这个类处理起来更容易,因为底层的列表可以作为属性来访问。
模拟一个列表。这个实例的内容被保存为一个正常列表,通过 UserList 的 data 属性存取。实例内容被初始化为一个 list 的copy,默认为 [] 空列表。 list可以是迭代对象,比如一个Python列表,或者一个UserList 对象。
UserList 提供了以下属性作为可变序列的方法和操作的扩展:data
一个 list 对象用于存储 UserList 的内容。
子类化的要求: UserList 的子类需要提供一个构造器,可以无参数调用,或者一个参数调用。返回一个新序列的列表操作需要创建一个实现类的实例。它假定了构造器可以以一个参数进行调用,这个参数是一个序列对象,作为数据源。
如果一个分离的类不希望依照这个需求,所有的特殊方法就必须重写;请参照源代码进行修改。
九、UserString
UserString类是用作字符串对象的外包装。对这个类的需求已部分由直接创建str的子类的功能所替代,不过这个类处理起来更容易,因为底层的字符串可以作为属性来访问。
模拟一个字符串对象。这个实例对象的内容保存为一个正常字符串,通过UserString的data属性存取。实例内容初始化设置为seq的copy。seq 参数可以是任何可通过内建str()函数转换为字符串的对象。
UserString 提供了以下属性作为字符串方法和操作的额外支持:data一个真正的str对象用来存放 UserString 类的内容。