1、概述
在之前的一篇文章《线程基础:多任务处理(13)——Fork/Join框架(解决排序问题)》中,我们使用了fork/join框架提高归并排序的性 能。那篇文章发布后,有的读者联系我,觉得单就归并排序的优化并不太能够说明fork/join框架对性能的提升,也不能说明多个典型排序算法的性能区别。所以本篇文章从单线程快速排序到多线程归并排序、再到多线程桶排序的方式,依次分析它的执行性能。
本篇文章并不侧重于算法详细过程的讲解,关于快速排序、桶排序、归并排序等排序算法的详细过程请读者参见其它专门介绍算法过程的资料,当然本文还是会讲解这些排序算法的大致过程。
2、性能分析
2-1、快速排序
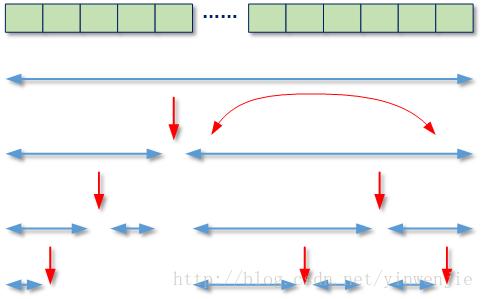
快速排序算法是冒泡排序算法的改进,是一种最基本的交换排序算法。上图中,展示了一个快速排序算法过程概要,最简要的描述是:在待排序的数组范围内,选择一个数值(通常是待排序数组的左侧第一个位置的数值)base。然后从待排序数组的两侧开始,向内侧进行搜索(分别记为索引位i和索引位j)。如果发现右侧索引位j的数值比base小,且发现左侧索引位i的数值比base大,则交换这两个索引位的数值。直到索引位i和索引位j重合(或者相交),最后将base数值交换到重合位置。最后递归进行交换后位置左侧的快速排序和交换后位置后侧的快速排序。以下是一个单线程的快速排序算法实现过程:
......
public class QuickSort {
// 测试是20个随机整数进行排序呢
// 对1亿条整型数据进行排序时,改这里就行了
private static int MAX = 20;
private static int resources[] = new int[MAX];
// 随机生成待排序的数组元素
static {
Random random = new Random();
for(int index = 0 ; index < MAX; index++) {
resources[index] = random.nextInt(MAX);
}
}
public static void main(String[] args) throws Exception {
System.out.println("开始计算===== ");
// 如果排序集合非常大,一定要把这个打印过程去掉
// System.out.println(Arrays.toString(resources));
long beginTime = System.currentTimeMillis();
QuickSort quickSort = new QuickSort();
quickSort.scan(resources , 0 , resources.length - 1);
long endTime = System.currentTimeMillis();
System.out.println("耗时=" + (endTime - beginTime) + " | ");
// 如果排序集合非常大,一定要把这个打印过程去掉
// System.out.println(Arrays.toString(resources));
// 开始检查
System.out.println("检查结果:" + SortResultCheck.scan(resources));
}
private void scan(int[] resources, int startIndexs , int endIndexs) {
/*
* 每次扫描的过程为:
* 0,确定一个base数值,这个数值是扫描数组的第一个元素
* 1、首先从endIndexs位置标记j,向左开始移动,一旦发现当前元素小于等于base,说明这个元素需要交换
* 2、然后再从startIndexs位置标记i,向右开始移动,一旦发现当前元素大于base,说明这个元素需要和之前的j位置进行交换
* 3、如果j的位置和i的位置已经相交,则按照当前j的位置和base的值交换
* 4、执行3完成后,按照交换后base的位置,分别递归排序左侧和右侧两部分
* */
if (endIndexs - startIndexs < 1) {
return;
}
// 以第startIndexs个元素为基准,进行扫描
int base = resources[startIndexs];
for (int i = startIndexs, j = endIndexs;;) {
boolean sawpBase = false;
// 1、=============================
for (;; j--) {
// 如果条件成立,说明j的位置找到一个比base小或者等于base的值
// 那么开始移动i
if (resources[j] <= base) {
break;
}
}
// 2、=============================
if (!sawpBase) {
for (;; i++) {
// 如果条件成立,说明i和j已经重合,开始移动基准数到指定位置
if (i >= j) {
sawpBase = true;
break;
}
// 如果条件成立,说明j的位置找到一个比base大的值
if (resources[i] > base) {
break;
}
}
// 3、=============================
if(i < j) {
swap(resources , i , j);
}
}
// 4、=============================
if (sawpBase) {
swap(resources , startIndexs , j);
// 开始进行递归计算,先计算左侧,再计算右侧
if(j != endIndexs) {
this.scan(resources, startIndexs, j);
this.scan(resources, j+1, endIndexs);
} else {
this.scan(resources, startIndexs, j - 1);
}
return;
}
}
}
// 该方法用于交换
private void swap(int[] arrays, int i, int j) {
int temp;
temp = arrays[i];
arrays[i] = arrays[j];
arrays[j] = temp;
}
}
......以下是一个可能的计算结果示例(你可以多运行几次,以测试算法是否正确):
开始计算=====
[105, 98, 218, 128, 141, 344, 292, 191, 329, 378, 272, 272, 125, 331, 109, 154, 296, 235, 321, 63]
耗时=0 |
[63, 98, 105, 109, 125, 128, 141, 154, 191, 218, 235, 272, 272, 292, 296, 321, 329, 331, 344, 378]另外在本文讲解的所有排序算法实例中,你都可以使用以下代码片段对排序后的结果正确性进行检查(因为数据量一旦大了,这样的方式总比用肉眼看效率高得多):
......
public class SortResultCheck {
public boolean scan(Integer[] resources) {
// 主要就是确定,下一个数字一定比上一个数字大或者相等
int len = resources.length;
for(int index = 0 ; index < len - 1 ; index++) {
if(resources[index] > resources[index + 1]) {
System.out.println("检测到错误!index = " + index);
return false;
}
}
return true;
}
}
......快速排序算法是一种不稳定的排序算法,所谓不稳定排序算法是指看似两个(或多个)相同的数值,在排序过程中是会发生变化的,且最终的相对位置顺序可能并不是它们原来的相对位置顺序。而且快速排序算法在最坏情况下的时间复杂度甚至可能会达到O(n2),所以快速排序法的应用在很多时候还停留在教材上用于向入门者讲述算法理论。但是快速排序算法也有其优点,例如快速排序算法是一种交换排序算法,它在运算时不需要更多的临时空间,所以它可以使用在一些待排序元素不多且存储空间又非常有限的场景下。下表展示了单线程情况下使用快速排序算法,对总数1亿条的整型数字集合进行排序操作所耗费的时间情况:
| 测试次数(单线程) | 所需时间(毫秒) |
|---|---|
| 1 | 13129 |
| 2 | 14407 |
| 3 | 14455 |
| 4 | 14238 |
| 5 | 13604 |
请注意运行过程并没有进行JVM优化,所以当你运行以上快速排序代码时,虽然也只有单线程在进行实际运算,但是运行过程会产生大量的GC回收运算,所以实际CPU使用情况会比较高——特别是你强行将基本类型int装箱为Integer类型时(这个现象你只需要打开jvisualvm就可以印证)。笔者相信在进行代码优化和JVM优化后,以上代码的运行性能会进一步提升,但这并不是本文的重点。
- JDK1.7+ 中使用的基本排序算法:
通过阅读Java JDK1.7+ 的官方文档和代码后你可以轻松的发现,Java中使用的主要基础排序算法是一种叫做TimSort的排序算法,TimSort算法是一种基于归并排序和插入排序的混合排序算法,并做了大量的细节优化。该算法最初由Tim Peters于2002年在Python语言中提出的,具体可参见http://svn.python.org/projects/python/trunk/Objects/listsort.txt。Java中使用的主要基础排序算法可不是什么快速排序算法。
你也可以参见java.util.Collections.sort方法、java.util.Arrays.sort方法或者其它相似的方法。
- JDK 1.7+ 中使用的排序算法,为什么比我自己写的排序过程慢?
那是因为你的测试过程写得有问题!使用java.util.Arrays.sort方法对1一亿条整型(int不是Integer)进行排序的性能时间分别是(毫秒):9525、 9803、 9529、 9836、9899。此外这只是单线程运行的情况下,如果使用后续介绍的桶排序 + TimSort的方式,那么排序操作完成的速度会更快。
2-3、归并排序——fork/join框架
归并排序算法已经在之前的文章中详细介绍过了,读者可以参见《线程基础:多任务处理(13)——Fork/Join框架(解决排序问题)》,这里我们直接列出基于fork/join pool进行多线程归并计算,对1亿个随机数进行多次排序运算后的计算性能情况:
- 使用单线程进行归并排序计算的耗时
| 测试次数 | 所需时间(毫秒) |
|---|---|
| 1 | 18812 |
| 2 | 18369 |
| 3 | 19101 |
| 4 | 18854 |
| 5 | 18710 |
- 使用fork/join pool运行归并排序计算的耗时
| 测试次数 | 所需时间(毫秒) |
|---|---|
| 1 | 14229 |
| 2 | 14665 |
| 3 | 14996 |
| 4 | 14456 |
| 5 | 15025 |
2-4、桶排序——fork/join框架
桶排序是一种针对多线程计算场景设计的排序算法,它的主要思路是先将一个无序的待排序的集合放入不同的集合(桶)中,并使用一种具体的排序算法,使用多个线程对这些桶中的元素进行排序。最后在这些桶中的元素都完成了排序后,再对这些桶进行一次遍历,最后合并成一个新的,已排序的结果集合:
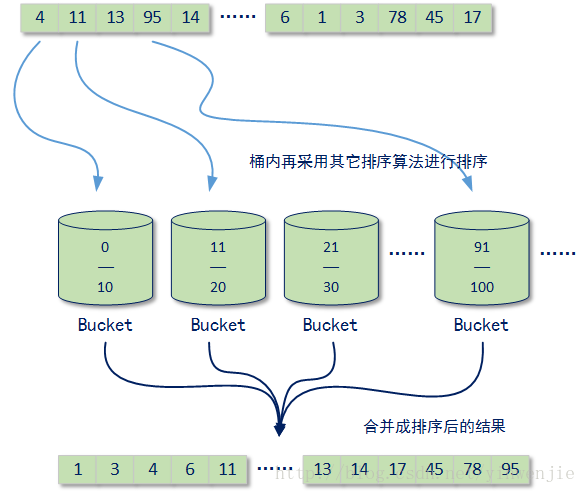
以上示意图是桶排序的基本过程。注意,每个桶都有自己承载的数值范围。例如上图所示的第一个桶,桶中的元素数值范围都在0-10(含)之间、第二个桶中的元素数值范围都在11-20(含)之间……
请看如下桶排序的代码示例:
......
public class Bucket {
private static final ForkJoinPool FORKJOIN_POOL = ForkJoinPool.commonPool();
// 单桶初始化大小
private static final int MAXINITPERBUCKET = 100000;
// 桶的数量
private static final int MAXBUCKET = 1000;
private static int resources[] = new int[MAXBUCKET *MAXINITPERBUCKET ];
static {
// 随机生成待排序的数组元素
Random random = new Random();
int len = MAXINITPERBUCKET * MAXBUCKET;
for(int index = 0 ; index < len; index++) {
resources[index] = random.nextInt(len);
}
}
public static void main(String[] args) throws Exception {
/*
* 操作步骤如下:
* 1、首先开始分桶
* 2、然后将这些桶放入fork/join pool中进行归并计算
* 3、待所有桶的排序完成后,再将这些有序集合,排列成一个新的有序集合
* */
// 1、==========
// 初始化分桶(还是单线程的)
System.out.println("开始计算===== ");
long beginTime = System.currentTimeMillis();
// 桶的大小是固定的,为了避免数组超界,在实际应用中单桶大小应设置一个合理的值
int[][] bucketArrays = new int[MAXBUCKET][MAXINITPERBUCKET *10];
// 单桶目前已存储的元素个数
int[] bucketIndexs = new int[MAXBUCKET];
int resourceLen = MAXBUCKET * MAXINITPERBUCKET;
for(int index = 0 ; index < resourceLen ; index++) {
int bucketIndex = resources[index] / MAXINITPERBUCKET;
// 放入相应的桶,并更新这个桶“已存储的元素个数”
bucketArrays[bucketIndex][bucketIndexs[bucketIndex]++] = resources[index];
}
System.out.println("完成分桶===== ");
// 2、==========
List<ForkJoinTask<int[]>> results = new ArrayList<>();
for(int index = 0 ; index < MAXBUCKET ; index++) {
int[] itemBucket = bucketArrays[index];
BucketSortTask bucketSortTask = new BucketSortTask(itemBucket , 0 , bucketIndexs[index] - 1);
ForkJoinTask<int[]> taskFeature = FORKJOIN_POOL.submit(bucketSortTask);
results.add(taskFeature);
}
// 3、==========
// 依次获得每个桶的结果就是一个有序集合了,这个步骤必须要算在时间内
System.out.println("开始最后排序===== ");
int[] resultAll = new int[MAXBUCKET * MAXINITPERBUCKET];
int destPos = 0;
for(int index = 0 ; index < MAXBUCKET ; index++) {
int[] bucketResults = results.get(index).get();
System.arraycopy(bucketResults, 0, resultAll,destPos , bucketIndexs[index]);
destPos += bucketIndexs[index];
}
long endTime = System.currentTimeMillis();
System.out.println("耗时=" + (endTime - beginTime) + " | ");
// 开始检查
System.out.println("检查结果:" + SortResultCheck.scan(resultAll));
}
// 桶排序任务,每个桶中采用快速排序法进行
static class BucketSortTask extends RecursiveTask<int[]> {
private int resources[];
private int startIndex , endIndex;
public BucketSortTask(int resources[] , int startIndex , int endIndex) {
this.resources = resources;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
@Override
protected int[] compute() {
QuickSortTask quickSortTask = new QuickSortTask(resources, this.startIndex, this.endIndex );
ForkJoinTask<int[]> result = quickSortTask.fork();
// 等待这个任务
int[] resultArrays;
try {
resultArrays = result.get();
return resultArrays;
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
return null;
}
}
// 快速排序任务(子任务)
static class QuickSortTask extends RecursiveTask<int[]> {
private int resources[];
private int beginIndex;
private int endIndex;
public QuickSortTask(int resources[] , Integer beginIndex , Integer endIndex) {
this.resources = resources;
this.beginIndex = beginIndex;
this.endIndex = endIndex;
}
@Override
protected int[] compute() {
this.scan(resources, beginIndex, endIndex);
return resources;
}
private void scan(Integer[] resources, int startIndexs , int endIndexs) {
// 这部分代码请参见之前的快速排序算法代码
......
}
}
}以上代码片段中,在重要的步骤位置已经注释的比较清楚了,可以看出我们将1亿个随机数(最大值100000000)分别放入1000个桶中,然后将这1000个桶让如fork/join pool中进行并行计算。待这些桶都完成计算后,再顺序遍历这些桶,将桶中的元素合并成一个新的最终排序的结果。下表反应了桶排序 + 快速排序多次运行后的计算性能情况:
| 测试次数 | 所需时间(毫秒) |
|---|---|
| 1 | 6755 |
| 2 | 6928 |
| 3 | 6827 |
| 4 | 6890 |
| 5 | 7046 |