1. MapReduce 编程模型理论
采用的是“分而治之”的理念,把大规模的数据集分成若干个小的数据集来进行并行处理,然后通过整合各个小的数据集的结果合并成一个最终结果。简单来说MapReduce就是“对任务的分解与结果的汇总”。
在Hadoop中,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,即map函数和reduce函数。map函数接收一个<key,value>形式的输入,然后同样产生一个<key,value>形式的中间输出,Hadoop函数接收一个如<key,(list of values)>形式的输入,然后对这个value集合进行处理,每个reduce产生0或1个输出,reduce的输出也是<key,value>形式的。这样的计算框架最大的好处是对于海量数据的数据集进行处理时能够更高效的对数据进行分析,处理,调度,负载均衡,容错均衡,容错处理及网络通信等复杂问题。
2. MapReduce WordCount程序
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版"Hello World",该程序的完整代码可以在Hadoop安装包的"src/examples"目录下找到。单词计数主要完成功能是:统计一系列文本文件中每个单词出现的次数,如下图所示。

接下来我们通过一个WordCount程序案例一起来看一下MapReduce是如何对数据进行数据分析处理的。
准备工作
1. 在本地创建一个Hadoop_wordcount.txt文件,记录些内容。(文件名随意,我是为了方便这个wordcount程序而命的名)
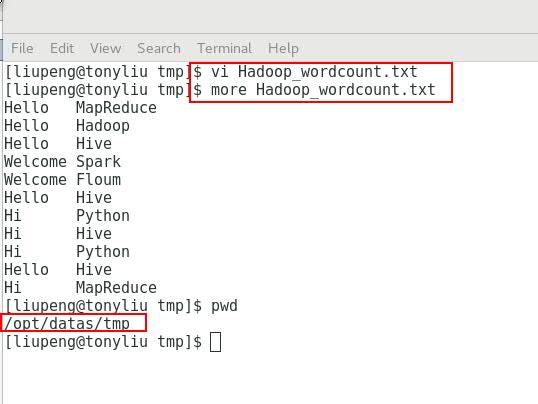
2. 在HDFS文件系统上创建input目录
关于HDFS命令行的使用,本章节不作具体描述。如果感兴趣的话可以百度一下或者通过 bin/hdfs dfs 查看一下下面所有命令的使用方法。基本跟Linux的命令行一样。
[liupeng@tonyliu hadoop-2.5.0]$ bin/hdfs dfs -mkdir -p /user/liupeng/wordcount/input //注意在使用命令行时一定要在前面加一个 - 。 17/11/13 15:10:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable

3. 把文档上传到我们的HDFS分布式文件系统之上
[liupeng@tonyliu hadoop-2.5.0]$ bin/hdfs dfs -put /opt/datas/tmp/Hadoop_wordcount.txt /user/liupeng/wordcount/input //-put 代表上传 后面跟本地文件路径 再跟HDFS上要上传的目标地址 17/11/13 15:16:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
4. 查看文件是否上传成功,并查看文件内容
[liupeng@tonyliu hadoop-2.5.0]$ bin/hdfs dfs -text /user/liupeng/wordcount/input/* // -text 代表查看 -cat 也可以查看文件内容但是不如-text的功能强大。 *我因为偷懒因此我选择*代表查看所有。如果文件多的情况下请指定具体文件名 17/11/13 15:18:32 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Hello MapReduce Hello Hadoop Hello Hive Welcome Spark Welcome Floum Hello Hive Hi Python Hi Hive Hi Python Hello Hive Hi MapReduce [liupeng@tonyliu hadoop-2.5.0]$
5. 运行wordcount程序
注意事项:/user/liupeng/wordcount/input目录是我们自己创建的,而output目录我们并没有创建也不允许创建。因为wordcount过程中需要对文件中的数据进行拆分,分组,统计,合并等操作把最终的结果输出出来。如果提前做好output目录的话会因此目录重覆等问题导致程序出错。output目录只允许存在一个,因此如果多次手动运行mapreduce时建议把输出结果名变更成例如output1,output2等方式。
在运行wordcount程序时需要提前进行编译,我们在安装Hadoop时默认share/hadoop/mapreduce/下就有一个编译好的hadoop-mapreduce-examples-2.5.0.jar包(不同版本名字不同),我们直接拿来用就好了。因此我们通过下面命令直接引用这个jar包来运行我们的wordcount程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/liupeng/wordcount/input /user/liupeng/wordcount/output /hadoop目录下指定 jar包 再告诉系统运行的是什么程序(wordcount)然后input路径 output路径
6. wordcount程序运行过程中的进度展示


[liupeng@tonyliu hadoop-2.5.0]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/liupeng/wordcount/input /user/liupeng/wordcount/output 17/11/13 15:24:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 17/11/13 15:24:16 INFO client.RMProxy: Connecting to ResourceManager at tonyliu.localhost.com/192.168.122.233:8032 17/11/13 15:24:16 INFO input.FileInputFormat: Total input paths to process : 1 17/11/13 15:24:17 INFO mapreduce.JobSubmitter: number of splits:1 17/11/13 15:24:17 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1510537204380_0003 17/11/13 15:24:17 INFO impl.YarnClientImpl: Submitted application application_1510537204380_0003 17/11/13 15:24:17 INFO mapreduce.Job: The url to track the job: http://tonyliu.localhost.com:8088/proxy/application_1510537204380_0003/ 17/11/13 15:24:17 INFO mapreduce.Job: Running job: job_1510537204380_0003 17/11/13 15:24:22 INFO mapreduce.Job: Job job_1510537204380_0003 running in uber mode : false 17/11/13 15:24:22 INFO mapreduce.Job: map 0% reduce 0% 17/11/13 15:24:29 INFO mapreduce.Job: map 100% reduce 0% 17/11/13 15:24:36 INFO mapreduce.Job: map 100% reduce 100% 17/11/13 15:24:37 INFO mapreduce.Job: Job job_1510537204380_0003 completed successfully 17/11/13 15:24:37 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=118 FILE: Number of bytes written=194439 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=279 HDFS: Number of bytes written=76 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=4263 Total time spent by all reduces in occupied slots (ms)=4433 Total time spent by all map tasks (ms)=4263 Total time spent by all reduce tasks (ms)=4433 Total vcore-seconds taken by all map tasks=4263 Total vcore-seconds taken by all reduce tasks=4433 Total megabyte-seconds taken by all map tasks=4365312 Total megabyte-seconds taken by all reduce tasks=4539392 Map-Reduce Framework Map input records=11 Map output records=22 Map output bytes=219 Map output materialized bytes=118 Input split bytes=148 Combine input records=22 Combine output records=9 Reduce input groups=9 Reduce shuffle bytes=118 Reduce input records=9 Reduce output records=9 Spilled Records=18 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=70 CPU time spent (ms)=1370 Physical memory (bytes) snapshot=388440064 Virtual memory (bytes) snapshot=1760473088 Total committed heap usage (bytes)=275251200 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=131 File Output Format Counters Bytes Written=76
doop命令会启动一个JVM来运行这个MapReduce程序,并自动获得Hadoop的配置,同时把类的路径(及其依赖关系)加入到Hadoop的库中。以上就是Hadoop Job的运行记录,从这里可以看到,这个Job被赋予了一个ID号:job_1510537204380_0003,而且得知输入文件有两个(Total input paths to process : 1),同时还可以了解map的输入输出记录(record数及字节数),以及reduce输入输>出记录。比如说,在本例中,map的task数量是1个,reduce的task数量是一个。map的输入record数是11个,输出record数是22个等信息。
7. 查询MapReduce WordCount程序汇总结果
查看方式分为2种,1 是通过web界面查看,2是通过dfs -text 命令行查看。下图中_SUCCESS文件代表程序运行成功,内容实际存储在part-r-00000文件中。
方式1:
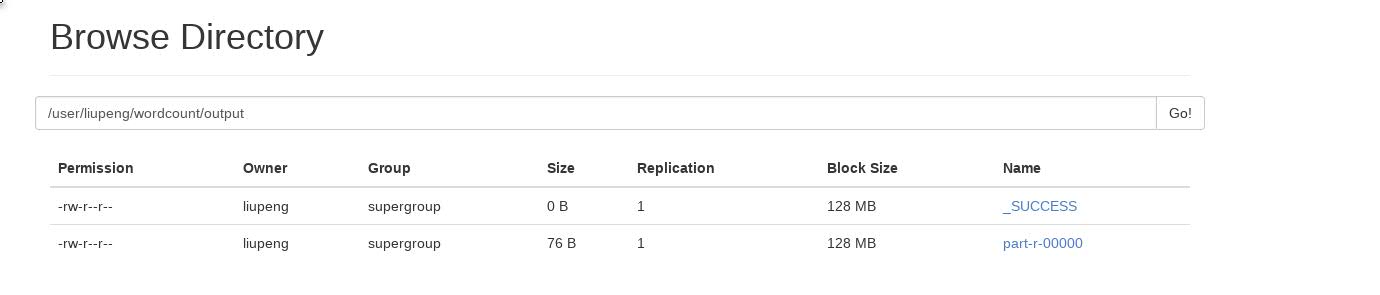
方式2:
[liupeng@tonyliu hadoop-2.5.0]$ bin/hdfs dfs -text /user/liupeng/wordcount/output/* 17/11/13 16:00:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Floum 1 Hadoop 1 Hello 5 Hi 4 Hive 4 MapReduce 2 Python 2 Spark 1 Welcome 2 [liupeng@tonyliu hadoop-2.5.0]$
3. WordCount 处理过程
本节将对WordCount进行更详细的讲解。详细执行步骤如下:
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,如图4-1所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。

图3-1 分割过程
2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如图4-2所示。

图3-2 执行map方法
3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如图4-3所示。

图3-3 Map端排序及Combine过程
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如图4-4所示。

图3-4 Reduce端排序及输出结果
补充:本文大部分内容是参考了下面虾米工作室的总结而写成的。也同时感谢虾米工作室的具体总结让我对MapReduce计算框架有了更深刻的了解。另外关于MapReduce API在link中也有具体的提到。我打算另外写一片属于自己理解的API博客。
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html