最近要用到相似度,特转以下文章,个人感觉非常好:
来源:http://blog.csdn.net/eaglet
摘要
在数据挖掘的研究中,我们往往需要判断文章是否雷同,对类似文章或短句进行归类处理等,这其中就会遇到这样的问题:如何确定两个字符串之间的相似程度。
本文综合作者的实际工作经验和数据挖掘理论,结合中文字符串特性介绍一套相对完整的方法,以解决上述问题.。
分析
最简单的问题求解
字符串由一组不同含义的单词组成,它不同于数值型变量,可以用一个特定的数值来确定它的大小或位置,所以用何种方式来描述两个字符串之间的距离,成为了一个值得探讨的问题。
通常情况下,用于分析的数据类型有如下几种:区间标度遍历、二元变量、标称型变量、序数型变量、比例标度型变量、混合类型变量等。
综合这些变量类型,本文认为字符串变量更适合于归类于二元变量,我们可以利用分词技术将字符串分成若干个单词,每个独立的单词作为二元变量的一个属性。我们把所有单词设定为一个二元变量属性集合R,字符串1和字符串2的单词包含于这个集合R。设q是字符串1和字符串2中都存在的单词的总数,s是字符串1中存在,字符串2中不存在的单词总数,r是字符串2中存在,字符串1中不存在的单词总数,t是字符串1和字符串2中都不存在的单词总数。我们称 q,r,s,t为字符串比较中的4个状态分量。 如图1所示:
由于两个字符串都不存在的单词对两个字符串的比较没有任何作用,所以忽略t,于是我们采用非恒定的相似度评价系数(Jaccard系数)来描述两个字符串见的相异度表示公式为
相异度 = r+s / (q+r+s),不难推断,他们的形似度公式为
相似度=q/(q+r+s) 公式1
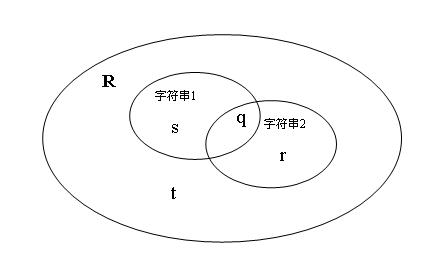
图1 字符串关系描述
例如如下两个字符串串:
字符串1:非对称变量
字符串2:非对称空间
他们的二元属性关系表为:
|
字符串/属性 |
非 |
对称 |
变量 |
空间 |
|
非对称变量 |
Y |
Y |
Y |
N |
|
非对称空间 |
Y |
Y |
N |
Y |
Y 表示存在该单词属性,N表示不存在该单词属性
那么对应的
s = 1; q = 2; r = 1
两个字符串的相似度为 2/(1+2+1) = 50%
单词重复问题求解
前面讨论的问题是最简单的字符串比较问题,这个问题中单个字符串不存在重复的单词,然而如果字符串中出现重复单词,采用上一节的公式套用后得到的结果往往不够理想,比如
字符串1:前进前进
字符串2:前进
公式1相似度=q/(q+r+s) 来计算,
q = 1 , r=s=0 ,得到的相似度为100%,而实际上这两个字符串并不完全相同。为解决这个问题,我们必须将在不同位置出现的相同单词假设为不同单词,以其在字符串中出现的次序作为区分,这样其二元属性关系表如下:
|
字符串/属性 |
前进1 |
前进2 |
|
前进前进 |
Y |
Y |
|
前进 |
Y |
N |
相应的 q = 1, s=1, r= 0
其相似度为 1/(1+1+0) = 50%
状态分量权重
在实际应用中,q,r,s三种状态分量并不一定是同等价值的,它们往往根据实际应用的需要存在不同的权重,比如对于某些应用来说,两个字符串中相同单词数量比不同单词数量更能说明字符串的相似程度,那么我们必须将q的权重提高,重新计算相似程度。
我们设对应q,r,s三个变量的权重分别是Kq, Kr, Ks ,则公式1 演进为
相似度=Kq*q/(Kq*q+Kr*r+Ks*s) (Kq > 0 , Kr>=0,Ka>=0) 公式2
回到上面问题,对于上一节的两个字符串,如果我们设置Kq = 2 ,Kr=Ks=1,则更加公式2
它们的相似度为 2*1/ (2*1+1*1+1*0) = 66.7%
同义词问题
在语言中,同义词是经常遇到的问题,如果两个字符串中存在同义词,其相似度又如何计算呢。
对于同义词问题,我们要从分词过程中来解决。首先我们需要构建一个同义词对照表,将同义词对应到一个等价单词,在对字符串分词后对字符串中的所有单词到同义词表中查找,如果存在,则替换为对应的等价单词,这样分词后,两个字符串中的同义词就指向了相同的单词。
比如存在同义词表如下:
|
单词 |
等价词 |
|
也许 |
也许 |
|
或许 |
也许 |
|
可能 |
也许 |
字符串1:他也许不来了
字符串2:他可能不来了
分词后二元属性关系表如下:
|
字符串/属性 |
他 |
也许 |
不来 |
了 |
|
他也许不来了 |
Y |
Y |
Y |
Y |
|
他可能不来了 |
Y |
Y |
Y |
Y |
不难看出,两个字符串的相似度为 100%
同音不同义
在中文网络环境中,由于大多数网络文章的作者都是采用拼音输入法输入汉字,经常会出现输入同音不同义的文字错误,为了纠正这种错误,我们可以考虑采用汉语拼音的方式进行分词,也可以综合分词,也就是先正常分词,在拼音分词,字符串的分词结果去两者的并集。
小节
确定字符串相似度的方法很多,本文根据作者多年从事数据挖掘工作的经验结合数据挖掘理论提出的相关解决方案,可以较好的解决中文字符串分析中的相似度比较问题。但技术的发展是不断前进的,相信未来还会有更好的方法来解决中文字符串相似度比较问题。读者如果有更好的想法或者发现本文算法中的不足,非常欢迎和本文作者联系。