参考:http://www.52nlp.cn/%e7%90%86%e8%ae%ba-%e6%9c%b4%e7%b4%a0%e8%b4%9d%e5%8f%b6%e6%96%af%e6%a8%a1%e5%9e%8b%e7%ae%97%e6%b3%95%e7%a0%94%e7%a9%b6%e4%b8%8e%e5%ae%9e%e4%be%8b%e5%88%86%e6%9e%90#more-10451
一、理论
朴素贝叶斯法是基于贝叶斯定理和特征条件独立假设的分类方法,‘朴素’之名来源于特征条件独立的假设,这是一个很强,很简单的假设,因为它意味着不同特征之间不会相互影响,这大大简化了计算。
首先,从给定的数据集出发,(这些数据集包括用多个特征描述的输入x,以及x对应的类别标记y,X是定义在输入空间上的随机变量,而Y是定义在输出空间上的随机变量,P(X,Y)是X,Y的联合概率分布)求出P(X,Y);然后根据贝叶斯定理,对给定的输入x,求出后验概率最大的输出y。

如上式,左边是我们要求的,即当给一个要预测的输入x=(x1,x2...,xn)时,要求x的类别y的概率,我们希望有这样一个y值,使得左边的概率最大;右边是可以根据数据集估计出来的概率,且分母是与类别无关的常数,不管y是多少,分母都不变,它只与初始数据集有关,所以当我们只想判断不同y取值下的大小时,可以省去。
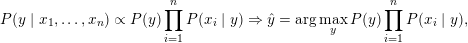
现在将问题简单了一些,只求argmax[y],右边可以根据数据集统计结果得出,即我们选择不同类别的输入x,计算它们的类别概率与给定类别下的特征组合的条件概率的乘积,然后比较大小即可,最大的就是要预测的类别值。
那么朴素贝叶斯是在学什么呢,可以知道,我们不需要去精确的计算P(X,Y)的参数,(朴素贝叶斯法是一种生成方法,同时考虑X和Y的随机性,就算想计算也不能直接计算P(X,Y),必须要通过下面两种方法估计后,再相乘得到联合概率分布)朴素贝叶斯的学习只要通过足够多的数据集估计出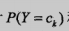 和
和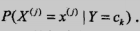 即可。
即可。
极大似然估计方法如下,就是比较简单的计数法:
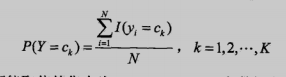
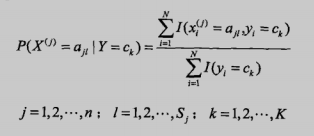
还有一种是贝叶斯估计,考虑到有时候可能因为数据集很少,某个特征出现分子为0的情况,然后导致后验概率也为0,造成全盘皆输的局面,简单来说就是为了防止出现0的情况使用了平滑:
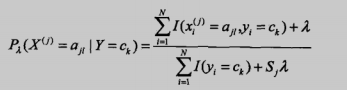
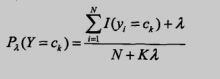
二、项目:识别留言板侮辱性评论
参考:http://www.52nlp.cn/%e5%ae%9e%e7%8e%b0-%e6%9c%b4%e7%b4%a0%e8%b4%9d%e5%8f%b6%e6%96%af%e6%a8%a1%e5%9e%8b%e7%ae%97%e6%b3%95%e7%a0%94%e7%a9%b6%e4%b8%8e%e5%ae%9e%e4%be%8b%e5%88%86%e6%9e%90
- 收集数据: 可以是文本数据、数据库数据、网络爬取的数据、自定义数据等等
- 数据预处理: 对采集数据进行格式化处理,文本数据的格式一致化,网络数据的分析抽取等,包括中文分词、停用词处理、词袋模型、构建词向量等。
- 分析数据: 检查词条确保解析的正确性,根据特征进行模型选择、特征抽取等。
- 训练算法: 从词向量计算概率
- 测试算法: 根据现实情况修改分类器
- 使用算法: 对社区留言板言论进行分类
1 #加载数据集,这里的postingList刚好模拟了评论加载进来然后分词后的结果,其中每一个子列表都代表着一条评论信息,这里一共有6条评论,作为我们的训练集;然后返回文档列表和文档类别列表 2 def loadDataSet(): 3 postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], 4 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], 5 ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], 6 ['stop', 'posting', 'stupid', 'worthless', 'garbage'], 7 ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], 8 ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] 9 classVec = [0, 1, 0, 1, 0, 1] # 1代表侮辱性文字,0代表非侮辱文字 10 return postingList, classVec 11 12 #提取出所有单词(不重复) 13 def createVocabList(dataSet): 14 vocabSet = set([]) 15 for document in dataSet: 16 vocabSet = vocabSet | set(document) # 操作符 | 用于求两个集合的并集 17 return list(vocabSet) 18 19 #查找输入数据,即我们要判断类别的句子的单词是否在词汇表中(上一个函数提取出来的是词汇表) 20 def setOfWords2Vec(vocabList, inputSet): 21 # 创建一个和词汇表等长的向量,并将其元素都设置为0 22 returnVec = [0] * len(vocabList) 23 # 遍历文档中的所有单词,如果出现了词汇表中的单词,则将输出的文档向量中的对应值设为1 24 for word in inputSet: 25 if word in vocabList: 26 returnVec[vocabList.index(word)] = 1 27 else: 28 print("单词: %s 不在词汇表之中!" % word) 29 print(returnVec) 30 return returnVec
上述代码是默认已经抓取好评论(我们的训练集),并且做好了分词。然后做一个词汇表,和一个全为0的且长度与词汇表相同的列表,对于新的句子,进行分词后看一下这些词在不在词汇表里,在的话,就把0列表中对应单词位置的0改为1,这样的缺点就是如果词汇表很大,那新句子得到的列表表示,和词汇表一样大。
运行一下看看:
1 postingList,classVec=loadDataSet() 2 voc=createVocabList(postingList) 3 print(postingList[0]) 4 print(voc) 5 setOfWords2Vec(voc, postingList[0])

第一个列表是我们将要进行转化的列表(将单词转化成0 1表示),这里直接取的是原来做词汇表其中的一个句子。第二个列表就是词汇表。第三个列表是转化得到的词向量,它和词袋模型不太一样的地方是其中的1表示的是“出现过”,而不是“出现的次数”。
现在已经知道了一个词是否出现在一篇文档中,也知道该文档所属的类别。接下来我们重写贝叶斯准则,将之前的 x, y 替换为 w. 粗体的 w 表示这是一个向量,即它由多个值组成。在这个例子中,数值个数与词汇表中的词个数相同。
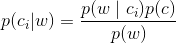
其中,C表示类别,W表示特征,在这个例子里就是【某词是否出现过】,体现在词向量上面就是【该单词的位置是否为1】。
首先可以通过类别 i (侮辱性留言或者非侮辱性留言)中的文档数除以总的文档数来计算概率 ,也就是【数据集中类别的概率】。接下来计算
,这里就要用到朴素贝叶斯假设。如果将 w 展开为一个个独立特征,那么就可以将上述概率写作
。这里假设所有词都互相独立,该假设也称作条件独立性假设,它意味着可以使用
来计算上述概率,那么具体的要怎么计算条件特征概率呢?我们先看句子(词向量)的类别,再把这类句子的词向量进行位置的加和,再除以这个类别的下的句子的所有单词数。就可以得到在每个类别下,每个单词出现的概率是多少。具体代码实现如下:
def _trainNB0(trainMatrix, trainCategory): numTrainDocs = len(trainMatrix) # 文件数 numWords = len(trainMatrix[0]) # 第一句话词向量的长度,也就是词汇表的长度 # 侮辱性文件的出现概率,即trainCategory中所有的1的个数, # 代表的就是多少个侮辱性文件,与文件的总数相除就得到了侮辱性文件的出现概率 pAbusive = sum(trainCategory) / float(numTrainDocs) # 构造单词出现次数列表 p0Num = np.zeros(numWords) # [0,0,0,.....] p1Num = np.zeros(numWords) # [0,0,0,.....] p0Denom = 0.0;p1Denom = 0.0 # 整个数据集单词出现总数 for i in range(numTrainDocs): # 遍历所有的文件,如果是侮辱性文件,就计算此侮辱性文件中出现的侮辱性单词的个数 if trainCategory[i] == 1: p1Num += trainMatrix[i] #[0,1,1,....]->[0,1,1,...] p1Denom += sum(trainMatrix[i]) else: # 如果不是侮辱性文件,则计算非侮辱性文件中出现的侮辱性单词的个数 p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) # 类别1,即侮辱性文档的[P(F1|C1),P(F2|C1),P(F3|C1),P(F4|C1),P(F5|C1)....]列表 # 即 在1类别下,每个单词出现次数的占比 p1Vect = p1Num / p1Denom# [1,2,3,5]/90->[1/90,...] # 类别0,即正常文档的[P(F1|C0),P(F2|C0),P(F3|C0),P(F4|C0),P(F5|C0)....]列表 # 即 在0类别下,每个单词出现次数的占比 p0Vect = p0Num / p0Denom return p0Vect, p1Vect, pAbusive
postingList,classVec=loadDataSet() voc=createVocabList(postingList) print(voc) pos=[] for i in range(0,6): pos.append(setOfWords2Vec(voc, postingList[i])) print(pos) p0V,p1V,pAb=_trainNB0(pos,classVec) print('类别1的每个单词出现次数占比:',p0V) print('类别0的每个单词出现次数占比:',p1V) print('侮辱评论出现次数占比:',pAb)
运行结果为:
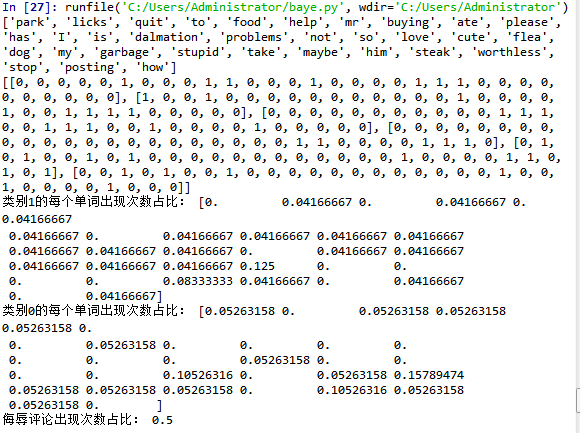
voc是词汇表;pos是将词汇表转化为词向量,它是包含五个子列表的列表,其中每一个子列表都是词向量表示的句子的分词结果;可以看到,词汇表的长度有32,即这五个句子的构成使用到了32个句子,词汇表不会有重复单词。侮辱评论次数占比是一个具体的数值,因为我们只要数一下句子中有几个侮辱性评论就可以了,因为我们的句子类别是[0, 1, 0, 1, 0, 1],显然为0.5。类别0/1的每个单词数显次数占比可以看出也是一个32维的向量,其中有一些位置的元素为0,表示在这个类别中,没有出现过这个单词。
在利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,即计算 。如果其中一个概率值为 0,那么最后的乘积也为 0。为降低这种影响,可以将所有词的出现数初始化为 1,并将分母初始化为 2 (取1 或 2 的目的主要是为了保证分子和分母不为0,大家可以根据业务需求进行更改)。
另一个遇到的问题是下溢出,这是由于太多很小的数相乘造成的。当计算乘积 时,由于大部分因子都非常小,所以程序会下溢出或者得到不正确的答案。(用 Python 尝试相乘许多很小的数,最后四舍五入后会得到 0)。一种解决办法是对乘积取自然对数。在代数中有 ln(a * b) = ln(a) + ln(b), 于是通过求对数可以避免下溢出或者浮点数舍入导致的错误。同时,采用自然对数进行处理不会有任何损失。
函数 f(x) 与 ln(f(x)) 的曲线。可以看出,它们在相同区域内同时增加或者减少,并且在相同点上取到极值。它们的取值虽然不同,但不影响最终结果。
根据朴素贝叶斯公式,我们观察分子进行条件概率连乘时候,由于有条件概率极小或者为0,最后导致结果为0 ,显然不符合我们预期结果,因此对训练模型进行优化,其优化代码如下:
def trainNB0(trainMatrix, trainCategory): numTrainDocs = len(trainMatrix) # 总文件数 numWords = len(trainMatrix[0]) # 总单词数 pAbusive = sum(trainCategory) / float(numTrainDocs) # 侮辱性文件的出现概率 # 构造单词出现次数列表,p0Num 正常的统计,p1Num 侮辱的统计 # 避免单词列表中的任何一个单词为0,而导致最后的乘积为0,所以将每个单词的出现次数初始化为 1 p0Num = np.ones(numWords)#[0,0......]->[1,1,1,1,1.....],ones初始化1的矩阵 p1Num = np.ones(numWords) # 整个数据集单词出现总数,2.0根据样本实际调查结果调整分母的值(2主要是避免分母为0,当然值可以调整) # p0Denom 正常的统计 # p1Denom 侮辱的统计 p0Denom = 2.0 p1Denom = 2.0 for i in range(numTrainDocs): if trainCategory[i] == 1: p1Num += trainMatrix[i] # 累加辱骂词的频次 p1Denom += sum(trainMatrix[i]) # 对每篇文章的辱骂的频次 进行统计汇总 else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) # 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表,取对数避免下溢出或浮点舍入出错 p1Vect = np.log(p1Num / p1Denom) # 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表 p0Vect = np.log(p0Num / p0Denom) return p0Vect, p1Vect, pAbusive
postingList,classVec=loadDataSet() voc=createVocabList(postingList) print(voc) pos=[] for i in range(0,6): pos.append(setOfWords2Vec(voc, postingList[i])) print(pos) p0V,p1V,pAb=trainNB0(pos,classVec) print('类别1的每个单词出现次数占比:',p0V) print('类别0的每个单词出现次数占比:',p1V) print('侮辱评论出现次数占比:',pAb)

为什么会是负数,主要是因为log(小于1的概率)的结果都是负,概率越小就代表这个负数越小而已。
概率都算出来了之后,那么就可以开始相乘,比较了:
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): # 计算公式 log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C)) # 使用 NumPy 数组来计算两个向量相乘的结果,这里的相乘是指对应元素相乘,即先将两个向量中的第一个元素相乘,然后将第2个元素相乘,以此类推。这里的 vec2Classify * p1Vec 的意思就是将每个词与其对应的概率相关联起来 p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1) if p1 > p0: return 1 else: return 0
全代码如下:
import numpy as np #加载数据集,这里的postingList刚好模拟了评论加载进来然后分词后的结果,其中每一个子列表都代表着一条评论信息,这里一共有6条评论,作为我们的训练集;然后返回文档列表和文档类别列表 def loadDataSet(): postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0, 1, 0, 1, 0, 1] # 1代表侮辱性文字,0代表非侮辱文字 return postingList, classVec #提取出所有单词(不重复) def createVocabList(dataSet): vocabSet = set([]) for document in dataSet: vocabSet = vocabSet | set(document) # 操作符 | 用于求两个集合的并集 return list(vocabSet) #查找输入数据,即我们要判断类别的句子的单词是否在词汇表中(上一个函数提取出来的是词汇表) def setOfWords2Vec(vocabList, inputSet): # 创建一个和词汇表等长的向量,并将其元素都设置为0 returnVec = [0] * len(vocabList) # 遍历文档中的所有单词,如果出现了词汇表中的单词,则将输出的文档向量中的对应值设为1 for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print("单词: %s 不在词汇表之中!" % word) return returnVec def trainNB0(trainMatrix, trainCategory): numTrainDocs = len(trainMatrix) # 总文件数 numWords = len(trainMatrix[0]) # 总单词数 pAbusive = sum(trainCategory) / float(numTrainDocs) # 侮辱性文件的出现概率 # 构造单词出现次数列表,p0Num 正常的统计,p1Num 侮辱的统计 # 避免单词列表中的任何一个单词为0,而导致最后的乘积为0,所以将每个单词的出现次数初始化为 1 p0Num = np.ones(numWords)#[0,0......]->[1,1,1,1,1.....],ones初始化1的矩阵 p1Num = np.ones(numWords) # 整个数据集单词出现总数,2.0根据样本实际调查结果调整分母的值(2主要是避免分母为0,当然值可以调整) # p0Denom 正常的统计 # p1Denom 侮辱的统计 p0Denom = 2.0 p1Denom = 2.0 for i in range(numTrainDocs): if trainCategory[i] == 1: p1Num += trainMatrix[i] # 累加辱骂词的频次 p1Denom += sum(trainMatrix[i]) # 对每篇文章的辱骂的频次 进行统计汇总 else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) # 类别1,即侮辱性文档的[log(P(F1|C1)),log(P(F2|C1)),log(P(F3|C1)),log(P(F4|C1)),log(P(F5|C1))....]列表,取对数避免下溢出或浮点舍入出错 p1Vect = np.log(p1Num / p1Denom) # 类别0,即正常文档的[log(P(F1|C0)),log(P(F2|C0)),log(P(F3|C0)),log(P(F4|C0)),log(P(F5|C0))....]列表 p0Vect = np.log(p0Num / p0Denom) return p0Vect, p1Vect, pAbusive def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): # 计算公式 log(P(F1|C))+log(P(F2|C))+....+log(P(Fn|C))+log(P(C)) # 使用 NumPy 数组来计算两个向量相乘的结果,这里的相乘是指对应元素相乘,即先将两个向量中的第一个元素相乘,然后将第2个元素相乘,以此类推。这里的 vec2Classify * p1Vec 的意思就是将每个词与其对应的概率相关联起来 p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1) if p1 > p0: return 1 else: return 0 def testingNB(): # 1. 加载数据集 dataSet, Classlabels = loadDataSet() # 2. 创建单词集合 myVocabList = createVocabList(dataSet) # 3. 计算单词是否出现并创建数据矩阵 trainMat = [] for postinDoc in dataSet: # 返回m*len(myVocabList)的矩阵, 记录的都是0,1信息 trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) # print('test',len(array(trainMat)[0])) # 4. 训练数据 p0V, p1V, pAb = trainNB0(np.array(trainMat), np.array(Classlabels)) # 5. 测试数据 testEntry = ['love', 'my', 'dalmation'] thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) print(testEntry, '分类结果是: ', classifyNB(thisDoc, p0V, p1V, pAb)) testEntry = ['stupid', 'garbage'] thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) print(testEntry, '分类结果是: ', classifyNB(thisDoc, p0V, p1V, pAb)) testingNB()
运行结果为:
其余代码实现:http://www.52nlp.cn/%e5%ae%9e%e7%8e%b0-%e6%9c%b4%e7%b4%a0%e8%b4%9d%e5%8f%b6%e6%96%af%e6%a8%a1%e5%9e%8b%e7%ae%97%e6%b3%95%e7%a0%94%e7%a9%b6%e4%b8%8e%e5%ae%9e%e4%be%8b%e5%88%86%e6%9e%90