交代一下背景:
一天半夜,服务器突然报警session异常增加且达到上限,整个服务器都处于夯住的状态,前段应用也无法连入,看起来是整个数据库全局的问题,重启了客户端后,才慢慢的恢复,然后进行了问题的分析。
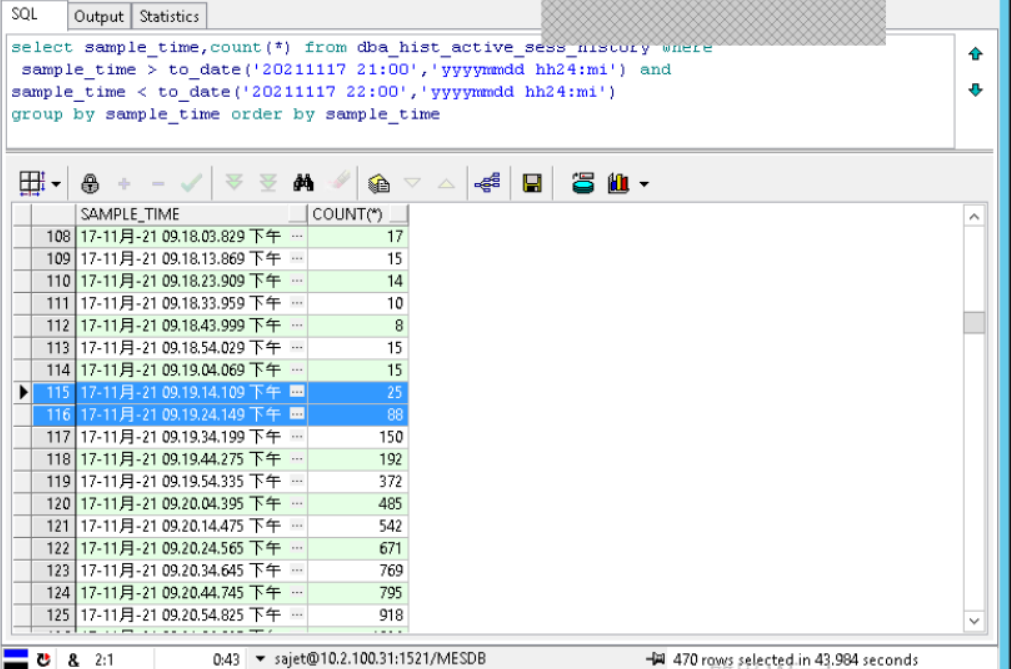
1.查看问题时间段,active session的数量,可以看出从晚上9点19开始session异常增加,到9点33慢慢下降
select sample_time,count(*) from dba_hist_active_sess_history where sample_time > to_date('20211117 21:00','yyyymmdd hh24:mi') and sample_time < to_date('20211117 22:00','yyyymmdd hh24:mi')
group by sample_time order by sample_time

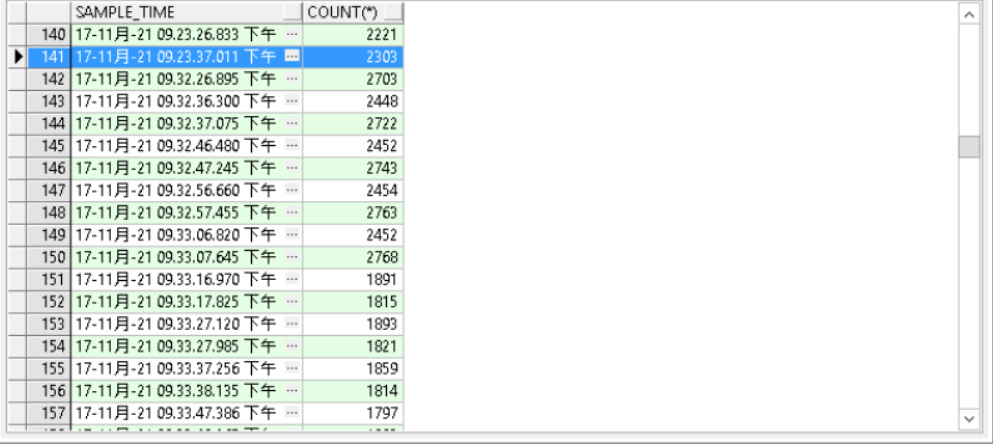
2. 查看故障时间段引起等待最多的session,发现是sid为3123和3010引起了较多的等待。
select blocking_session,count(*) from v$active_session_history
where sample_time > to_date('20211125 21:00','yyyymmdd hh24:mi') and sample_time < to_date('20211126 22:00','yyyymmdd hh24:mi')
group by blocking_session order by 2 desc ;

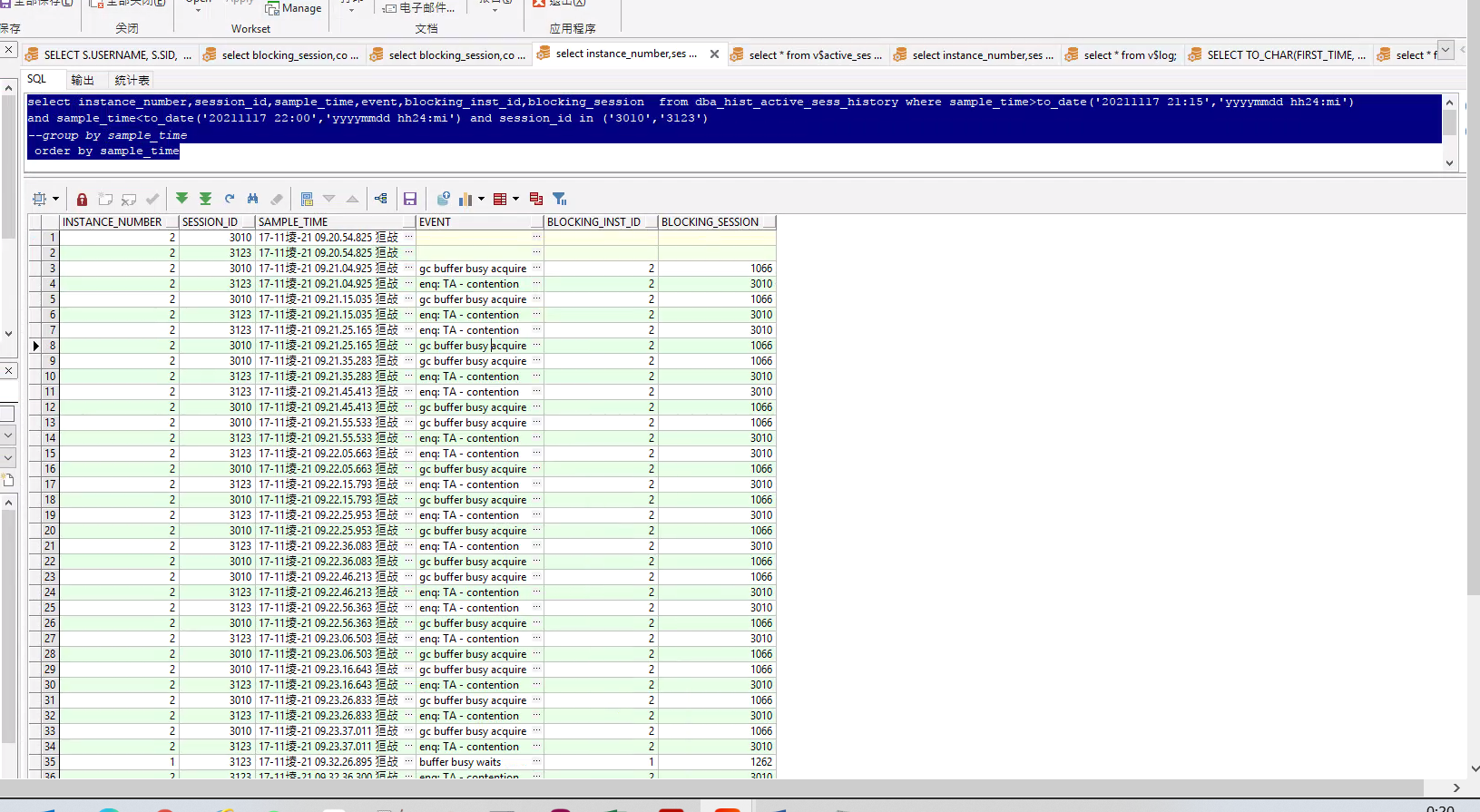
3.查看阻塞3123和3010的session的是哪个session
select instance_number,session_id,sample_time,event,blocking_inst_id,blocking_session from dba_hist_active_sess_history where sample_time > to_date('20211117 21:00','yyyymmdd hh24:mi') and sample_time < to_date('20211117 22:00','yyyymmdd hh24:mi')
and session_id in ('3123','3010')
4.查看sid为1066的进程均为等待2737进程
select session_id,sql_id,blocking_inst_id,blocking_session,event from dba_hist_active_sess_history where session_id='1066' and sample_time > to_date('20211117 21:00','yyyymmdd hh24:mi') and sample_time < to_date('20211117 22:00','yyyymmdd hh24:mi')

5.进程2737为lgwr进程,而且等待事件为log file switch checkpoint incomplete等待。
select * from gv$session where sid='2737'

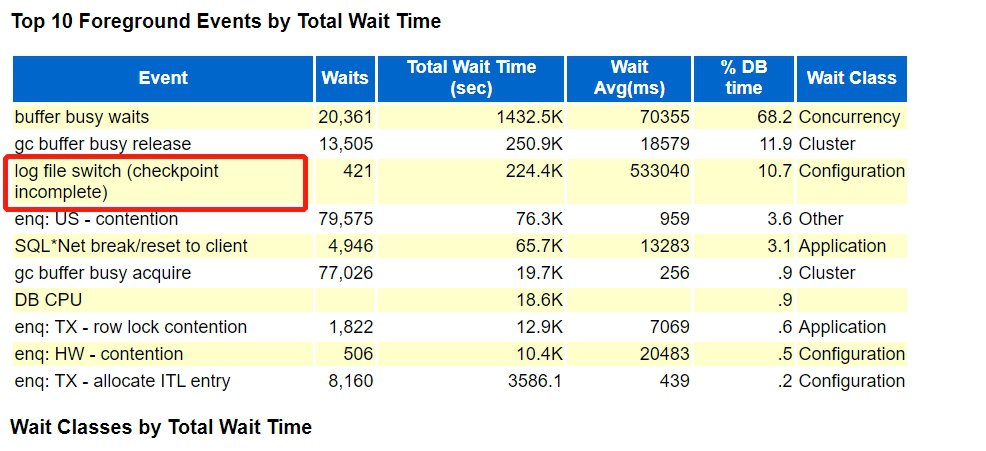
6.分析awr报告,可以看到异常时间段,log file switch checkpoint incomplete等待事件占比也较高,平均等待时间较长。当lgwr系统进程无法正常运作时候,会导致数据库正常的SQL语句,DML操作无法正常执行,进而引发buffer busy wait,gc buffer busy等一系列严重的等待。
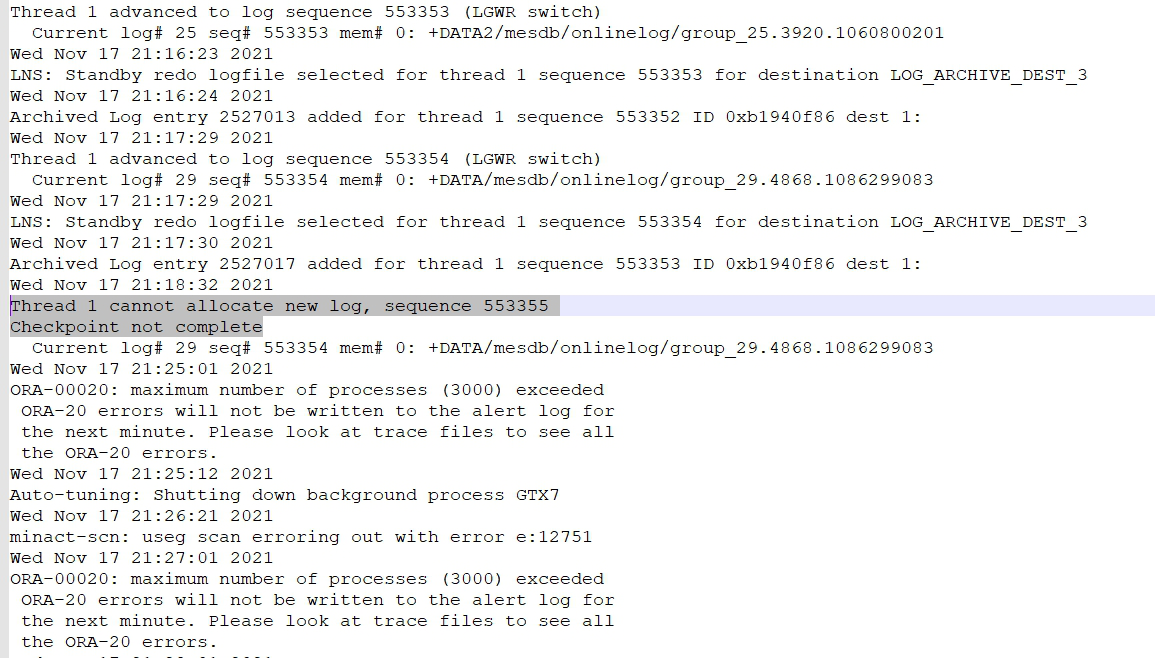
7. 检查alert log日志,在21.18分时候,抛出cannot allocate new log,21.25分开始抛出连接数达到最大值报错
8.针对log file switch checkpoint incomplete等待事件,根据官方文档资料,建议增加当前redo log file 大小。
9.调整redo log从500M到2G。