
倒排索引的初衷

倒排索引,它也是索引。索引,初衷都是为了快速检索到你要的数据。
我相信你一定知道mysql的索引,如果对某一个字段加了索引,一般来说查询该字段速度是可以有显著的提升。
每种数据库都有自己要解决的问题(或者说擅长的领域),对应的就有自己的数据结构,而不同的使用场景和数据结构,需要用不同的索引,才能起到最大化加快查询的目的。
对 Mysql 来说,是 B+ 树,对 Elasticsearch/Lucene 来说,是倒排索引。

倒排索引是什么
刚刚胖滚猪说到图书的例子,目录和索引页,其实就很形象的可以比喻为正排索引和倒排索引。为了进一步加深理解,再看看熟悉的搜索引擎。没有搜索引擎时,我们只能直接输入一个网址,然后获取网站内容,这时我们的行为是document -> words。此谓「正向索引」。后来,我们希望能够输入一个单词,找到含有这个单词,或者和这个单词有关系的文章,即word -> documents。于是我们把这种索引,叫「反向索引」,或者「倒排索引」。
好了,我们来总结一下:


倒排索引的实现
假如一篇文章当中,有这么一段话"胖滚猪编程让你收获快乐",我要通过"胖滚猪"这个词来搜索到这篇文章,那么应该如何实现呢。
我们是很容易想到,可以将这篇文章的词都拆开,拆分为"胖滚猪"、"编程"、"收获"、"快乐"。注意我们把没用的词,比如"让"去掉了。这个拆分短语的过程涉及到ES的分词,另外中文分词还是比较复杂的,不像英文分词一般用空格分隔就可以。等会我们再来说分词吧,现在你只要知道,我们是会按一定规则把文章单词拆分的。
那么拆开了,怎么去找呢?自然会维护一个单词和文档的对应关系,如图:


倒排索引的核心组成
1、单词词典:记录所有文档的单词,一般都比较大。还会记录单词到倒排列表的关联信息。
2、倒排列表:记录了单词对应的文档集合,由倒排索引项组成。倒排索引项包含如下信息:
- 文档ID,用于获取原始信息
- 单词频率TF,记录该单词在该文档中的出现次数,用于后续相关性算分
- 位置Position,记录单词在文档中分词的位置,用于语句搜索(phrase query)
- 偏移Offset,记录单词在文档的开始和结束位置,实现高亮显示

ES的倒排索引
下图是 Elasticsearch 中数据索引过程的流程。ES由 Analyzer 组件对文档执行一些操作并将具体子句拆分为 token/term,简单说就是分词,然后将这些术语作为倒排索引存储在磁盘中。
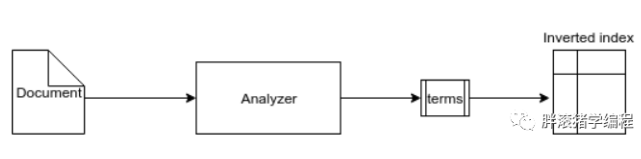
ES的JSON文档中的每一个字段,都有自己的倒排索引,当然你可以指定某些字段不做索引,优点是这样可以节省磁盘空间。但是不做索引的话字段无法被搜索到。
注意两个关键词:分词和倒排索引。倒排索引我相信你已经懂了!分词我们马上就来聊聊!
ES的分词
还是回到我们开头的那个查询例子,毕竟胖滚猪心心念念为什么会搜出两个文档!首先我们用_analyze来分析一下ES会如何对它进行分词及倒排索引:
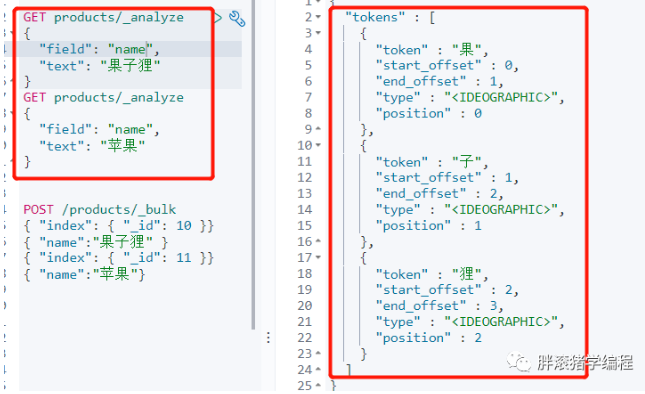
现在你是不是一目了然了呢!先不管_analyze是何方神圣,反正你看到结果了,ES将它分成了一个个字,这是ES中默认的中文分词。掌握分词要先懂两个名词:analysis与analyzer
** analysis:**
文本分析,是将全文本转换为一系列单词的过程,也叫分词。analysis是通过analyzer(分词器)来实现的,可以使用Elasticearch内置的分词器,也可以自己去定制一些分词器。
** analyzer(分词器): **
由三部分组成:
- Character Filter:将文本中html标签剔除掉。
- Tokenizer:按照规则进行分词,在英文中按照空格分词
- Token Filter:将切分的单词进行加工,小写,删除 stopwords(停顿词,a、an、the、is等),增加同义词
注意:除了在数据写入时将词条进行转换,查询的时候也需要使用相同的分析器对语句进行分析。即我们写入苹果的时候分词成了苹和果,查询苹果的时候同样也是分词成苹和果去查。

ES内置分词器
- Standard Analyzer - 默认分词器,按词切分,小写处理
- Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
- Stop Analyzer - 小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer - 按照空格切分,不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
- Patter Analyzer - 正则表达式,默认W+(非字符分割)
- Language - 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
看概念太虚了!一定要动手实操才有用!我们可以用_analyze进行分析,会输出分词后的结果,举两个例子吧!其他的你也要自己课后动手试试哦!
#默认分词器 按词切分 小写处理
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#可以发现停用词被去掉了
GET _analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
中文扩展分词器
现在来解决胖滚猪的问题,苹果明明一个词,不想让它分为两个呀!中文分词在所有搜索引擎中都是一个很大的难点,中文的句子应该是切分成一个个的词,但是一句中文,在不同的上下文,其实是不同的理解,例如: 这个苹果,不大好吃/这个苹果,不大,好吃。
有一些比较不错的中文分词插件:IK、THULAC等。我们可以试试用IK进行中文分词。
#安装插件
https://github.com/medcl/elasticsearch-analysis-ik/releases
在plugins目录下创建analysis-ik目录 解压zip包到当前目录 重启ES
#查看插件
bin/elasticsearch-plugin list
#查看安装的插件
GET http://localhost:9200/_cat/plugins?v
** IK分词器:支持自定义词库、支持热更新分词字典 **
- ik_max_word: 会将文本做最细粒度的拆分,比如会将“这个苹果不大好吃”拆分为"这个,苹果,不大好,不大,好吃"等,会穷尽各种可能的组合;
- ik_smart: 会做最粗粒度的拆分,比如会将“这个苹果不大好吃”拆分为"这个,苹果,不大,好吃"
curl -X GET "localhost:9200/_analyze?pretty" -H 'Content-Type: application/json' -d'
{
"analyzer" : "ik_max_word",
"text" : "这个苹果不大好吃"
}
'

** 如何使用分词器 **
列举了很多的分词器,那么在实际中该如何使用呢?看看下面这个代码演示就懂啦!
# 创建索引时候指定某个字段的分词器
PUT iktest
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
# 插入一条文档
PUT iktest/_doc/1
{
"content":"这个苹果不大好吃"
}
# 测试分词效果
GET /iktest/_analyze
{
"field": "content",
"text": "这个苹果不大好吃"
}
注:本文来源于公众号[胖滚猪学编程],其中卡通形象来源于微信表情包"胖滚家族",且已获作者的许可。

本文来源于公众号【胖滚猪学编程】一个集颜值与才华于一身的女程序媛。以漫画形式让编程so easy and interesting。