目录
1 Transformer-based的多变量时序表示学习 (KDD 2021)
3 基于异构图神经网络的非完整数据分类 (WWW 2021 Best paper runner up)
1 Transformer-based的多变量时序表示学习 (KDD 2021)
Motivation
Pre-trained models can be potentially used for downstream tasks such as regression and classification, forecasting and missing value imputation.
Meanwhile, the availability of labeled multivariate time series data in particular is far more limited: extensive data labeling is often prohibitively expensive or impractical, as it may require much time and effort, special infrastructure or domain expertise.
Therefore, it is worth exploring using only a limited amount of labeled data or leveraging the existing plethora of unlabeled data for time series data modeling.
Contribution
In this work, we investigate, for the first time, the use of a transformer encoder for unsupervised representation learning of multivariate time series, as well as for the tasks of time series regression and classification.
Experimental results indicated that transformer models can convincingly outperform all current state-of-the-art modeling approaches, even when only having access to a very limited amount of training data samples (on the order of hundreds of samples), an unprecedented success for deep learning models.
Importantly, we also demonstrate that our models, using at most hundreds of thousands of parameters, can be practically trained even on CPUs; training them on GPUs allows them to be trained as fast as even the fastest and most accurate non-deep learning based approaches.
Model
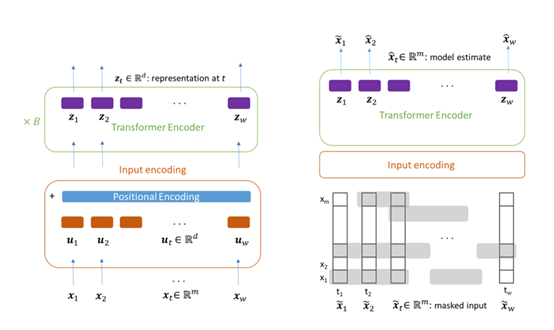
My thoughts
本文将Trsansformer模型成功应用到了多变量时间序列数据建模,并通过设计的特别的数据编码处理模块,使得本文模型能够对缺乏标签的多变量时序数据能够学习到一组很好的表示,从而有利于下游的回归、分类和填补任务。
本文最大的亮点在于其模型的预训练能力,降低模型对标签数据的依赖。但是本文对其学习的表示的可解释性方面为多做说明,这一点需要保留应用的谨慎性。
GitHub: https://github.com/gzerveas/mvts_transformer (目前37 Star)
2 单变量时序的迁移学习分类模型 (ICML 2021)
Motivation
Learning to classify time series with limited data is a practical yet challenging problem. Current methods are primarily based on hand-designed feature extraction rules or domain-specific data augmentation.
Contribution
Motivated by the advances in deep speech processing models and the fact that voice data are univariate temporal signals, in this paper we propose Voice2Series (V2S), a novel end-to-end approach that reprograms acoustic models for time series classification, through input transformation learning and output label mapping.
Leveraging the representation learning power of a large-scale pre-trained speech processing model, on 30 different time series tasks we show that V2S either outperforms or is tied with state-of-the-art methods on 20 tasks, and improves their average accuracy by 1.84%.
Model

My thoughts
本文应该是首次把大规模的预训练模型应用到了时间序列数据的分类任务上,并且在30种单变量时间序列数据集上取得了很好的效果,但是其类别数量在实验时需要控制在10种以内。此外,由于语音数据集是单变量形式,本文模型也只能应用到单变量上面。但是,本文在可视化分析上做的比较完善,相关可视化分析思路可以借鉴和参考。
GitHub: https://github.com/huckiyang/Voice2Series-Reprogramming (目前28 Star)
3 基于异构图神经网络的非完整数据分类 (WWW 2021 Best paper runner up)
Motivation
Heterogeneous information networks (HINs), also called heterogeneous graphs, are composed of multiple types of nodes and edges, and contain comprehensive information and rich semantics.
Graph neural networks (GNNs) based heterogeneous models can not be trained with some nodes with no attributes.
Previous studies take some handcrafted methods to solve this problem, which separate the attribute completion from the graph learning process and, in turn, result in poor performance.
Contribution
In this paper, we hold that missing attributes can be acquired by a learnable manner, and propose an end-to-end framework for Heterogeneous Graph Neural Network via Attribute Completion (HGNN-AC), including pre-learning of topological embedding and attribute completion with attention mechanism.
HGNN-AC first uses existing HIN-Embedding methods to obtain node topological embedding.
Then it uses the topological relationship between nodes as guidance to complete attributes for no-attribute nodes by weighted aggregation of the attributes from these attributed nodes.
Model
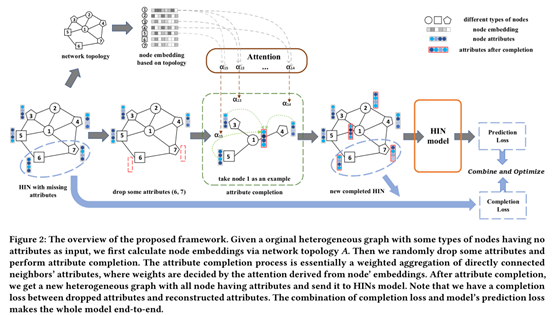
My thoughts
本文应该是首次把图神经网络和缺失数据填补结合在一起,建立了一种端到端的分类模型,相比已有的两阶段方法,能够取得明显的分类表现。
本文略有不足的是,在填补方面没有进行深入的分析和探讨即本文模型性能提升的原因相比已有的最新填补方法是填的更好,还是其他方面什么原因呢?
GitHub:https://github.com/search?q=Heterogeneous+Graph+Neural+Network+via+Attribute+Completion (目前11 Star)
4 基于图神经网络的多变量时序填补模型 (arXiv 2021)
Motivation
Dealing with missing values and incomplete multivariate time series is a labor-intensive and time-consuming inevitable task when handling data coming from real-world applications.
Standard methods fall short in capturing the nonlinear timeand space dependencies existing within networks of interconnected sensors and do not take full advantage of the available – and often strong – relational information.
Notably, most of state-of-the-art imputation methods based on deep learning do not explicitly model relational aspects and, in any case, do not exploit processing frameworks able to adequately represent structured spatio-temporal data.
Contribution
In this work, we present the first assessment of graph neural networks in the context of multivariate time series imputation. In particular, we introduce a novel graph neural network architecture, named GRIL , which aims at reconstructing missing data in the different channels of a multivariate time series by learning spatial-temporal representations through message passing.
Model

My thoughts
本文最大的亮点在于第一次把图神经网络应用到了多变量时间序列数据的建模,但是对于如何建立把不同图节点之间的依赖关系,本文没有去详细讨论。
另外,在于实验环节只进行了填补性能上的衡量分析,并没有针对图神经网络的特性做出一些有说服力的可视化实验和分析。
GitHub:暂无。目前应该属于NIPS投稿的阶段。
5 MinRocket:一种快速的时间序列分类模型 (KDD 2021)
Motivation
Until recently, the most accurate methods for time series classification were limited by high computational complexity.
While there have been considerable advances in recent years, computational complexity and a lack of scalability remain persistent problems.
Contribution
We reformulate Rocket into a new method, MiniRocket. MiniRocket is up to 75 times faster than Rocket on larger datasets, and almost deterministic (and optionally, fully deterministic), while maintaining essentially the same accuracy. Using this method, it is possible to train and test a classifier on all of 109 datasets from the UCR archive to state-of-the-art accuracy in under 10 minutes.
GitHub: https://github.com/angus924/minirocket (目前87 Star)