…高阶函数
map :: (a->b) ->[a] ->[b],将函数f依次应用于序列[a],得到新的序列[b]。
filter :: (a->bool)->[a]->[a],利用函数f过滤序列[a]。
这两个函数都可用list comprehension来实现,不过在某些情况下更简洁。利用这两个函数和CF组合可以生成各种需要的函数。
lambda
著名的lambda表达式(C++11中引入),也就是匿名函数,某些仅使用一次的函数不必命名,为了使代码更简洁,就有了lambda表达式。其格式为:
\ para1 para2->(return value)
\ (para1,para2) -> (return value)
由于Haskell有自动类型推断,所以不必明确表明返回类型。注意这里直接return value了,也就无法使用模式匹配之类的。
折叠
折叠是对list处理模式的再抽象。所有遍历list中元素并据此返回一个值的操作都可以交给fold实现。
foldl即为左折叠,从list左端开始。其参数分别是一个二元函数(参数分别是新值、累加值),一个初始值,一个待处理的list。
foldr为右折叠,由于模式匹配的时候一般不使用++,这时候就会用:配合foldr来完成任务。另外foldr适合处理无限长的list。
foldl1将参数中的初始值去掉,自动以list的head元素作为初始值;foldr1类似,取的是最后的元素。
scanl、scanr与fold系列类似,只是累加值的状态会被记录到下一次累加中(sum即scanl (+))。
$
$是函数调用符,与空格不同的是它的优先级最低,且为右结合,设计这个操作符的目的只是让某些函数写起来更简单。比如 sqrt (1+2+3),可以简单写成sqrt$1+2+3
函数组合
函数组合对应着数学中的复合函数。如果想要生成新的函数,使用函数组合操作符"."可能会很方便。"."具有右结合性,右边函数的返回值类型必须与左边函数的参数值类型相符。它的作用类似于管道操作符,将先进行的运算结果传给前面的函数。显然函数组合只适用于只有一个参数的函数之间。一般也是用于简洁化书写。
Haskell是偏于数学的高等抽象语言,因此以上这些特性内置在语言中,只是给coders提供了一些更优雅的书写方式,用前面学过的list comprehension都可以完成相同的功能,只是没有那么优雅了╮(╯-╰)╭
第七章 模块
前面六章主要介绍了函数,身为FP,函数显然是最重要的组成部分。但是作为一门编程语言,一些必备的特性也会出现在Haskell中,例如:库。
Haskell中的模块是由一组相关的函数,类型和类型类组成的。程序的架构就是由主模块调用其他模块(类似C),前面介绍的函数都是装载在prelude中的。
导入模块的语法类似java,import xxx(在ghci中是:m xxx,可以一次导入多个),如果只是导入一部分函数,可以在模块名后面在上(fun1,fun2..),如果要去除某一函数,可以在模块名后面加上hiding (funx),后者主要是为了避免命名冲突。
避免命名冲突还有一个方法,就是加上限定符(类似C++),使用import qualified module_name as name1,关键字 qualified表面后面的模块必须加上限定名,as则可以为限定符起别名。 下面介绍标准库的常用模块:
Data.List
显然这里是前文介绍的所有list操作函数所在的库。下面是一个简表:
函数原型 | 解释 |
intersperse :: a- > [a]- > [a] | 将第一个参数插入list相邻的元素之间 |
intercalate :: [a] -> [[a]] -> [a] | 将第一个List交叉插入第二个List中间 |
transpose :: [[a]] -> [[a]] | 反转一组List的List,类似转置矩阵 |
foldl' & foldl1' | 非惰性版的foldl和foldl1,大list的时候用 |
concat :: [[a]] -> [a] | 合并list中的元素,可用来追加字符串 |
concatMap :: (a -> [b]) -> [a] -> [b] | map一个list,然后concat |
and(or) :: [Bool] -> Bool | 对一组bool做与(或)运算 |
any(all) :: (a -> Bool) -> [a] -> Bool | 一组元素中满足条件的元素存在(都是) |
iterate :: (a -> a) -> a -> [a] | 用参数2递归调用参数1,产生无限的list |
splitAt :: Int -> [a] -> ([a], [a]) | 在指定下标处切割list,返回一个tuple |
takeWhile :: (a -> Bool) -> [a] -> [a] | 将满足条件的前面连续多个元素提取出来 |
dropWhile :: (a -> Bool) -> [a] -> [a] | 将前面不满足条件的连续多个元素舍弃 |
span(break) :: (a -> Bool) -> [a] -> ([a], [a]) | 类似takeWhile,不过将结果切割了,分别从false处、true处断开 |
sort :: Ord a => [a] -> [a] | 排序,以<顺序 |
group :: Eq a => [a] -> [[a]] | 将相邻并相等的元素分组,配合sort |
inits(tails) :: [a] -> [[a]] | 递归调用init(tail)直到什么都不剩 |
isInfixOf :: Eq a => [a] -> [a] -> Bool | 子序列判定,isPrefixOf、isSuffixOf用于判定首尾序列 |
elem、notElem | 判定是否子元素 |
partition :: (a -> Bool) -> [a] -> ([a], [a]) | 过滤元素并分组 |
find :: (a -> Bool) -> [a] -> Maybe a | 返回第一个满足条件的元素 |
elemIndex :: Eq a => a -> [a] -> Maybe Int | 返回第一个相等元素的索引 |
elemIndices :: Eq a => a -> [a] -> [Int] | 返回所有满足条件元素的索引集 |
findIndex :: (a -> Bool) -> [a] -> Maybe Int | 返回第一个满足条件元素的索引 |
findIndices :: (a -> Bool) -> [a] -> [Int] | 返回所有满足条件元素的索引集 |
zip,zipWith系列(<=7) | 将list对应元素组合成tuple的list |
lines :: String -> [String] | 将字符串按行分割 |
unlines :: [String] -> String | line的反函数 |
words(unwords) | 合并单词集或相反 |
nub :: Eq a => [a] -> [a] | 去除所有重复元素,组成新的list |
delete :: Eq a => a -> [a] -> [a] | 删除第一个与之相等的元素 |
union(intersection) :: Eq a => [a] -> [a] -> [a] | 返回两个list的并(交)集,以第一个为主顺序 |
insert :: Ord a => a -> [a] -> [a] | 保持顺序的插入元素 |
以上函数中,参数为int的都有更通用的版,在前面加上genernic就可得到通用版(如genericLength);
而用(==)判定相等的函数,可以改成用谓词作判定依据,只需要在其后加上By,如sortBy,groupBy等。
这里引入了Data.Function中的on函数:on :: (b -> b -> c) -> (a -> b) -> a -> a -> c
f `on` g = \x y -> f (g x) (g y),这个函数可以使By系列的函数使用起来更加简洁。判断相等性常用 (==) `on` xxx,判定大小则常用 compare `on` xxx.
Maybe类型是在可能返回nothing时使用,这样返回时如果存在就用Just xxx的格式,否则返回Nothing
Data.Char
这个模块主要包含了一些字符处理函数。类似于C中的<ctype.h>
函数原型 | 解释 |
isControl :: Char -> Bool | 判断控制字符 |
isSpace | 判断空格字符(space、tab、\n) |
isLower | 判断小写字符 |
isUpper | 判断大写字符 |
isAlpha(isLetter) | 判断字母 |
isAlphaNum | 判断字符或数字 |
isPrint | 判断可打印字符 |
isDigit(isNumber) | 判断数字 |
isOctDigit | 判断八进制数字 |
isHexDigit | 判断十六进制数字 |
isMark | 判断Unicode注音(for Frenchman) |
isPunctuation | 判断标点符号 |
isSymbol | 判断货币符号 |
isSeperater | 判断Unicode空格或分隔符 |
isAscii | 判断unicode字符表前128位 |
isLatin1 | 判断unicode字符表前256位 |
isAsciiUpper | 判断大写ascii字符 |
isAsciiLower | 判断小写ascii字符 |
generalCategory :: Char -> GeneralCategory | 判断所在分类 |
toUpper :: Char -> Char | 小写转换成大写,其余不变 |
toLower | 与上面相反 |
toTitle | 将一个字符转换成title-case |
digitToInt(ord) | 字符转换成int值 |
intToDigit(char) | int转换成字符 |
注意这里的函数比C中的字符处理函数要多得多,除了考虑unicode因素外,这里将各种进制的数看做完全不同的东西。也就是说,并不依据计算机内存模型。
Data.Map
这里的map类似C++中的关联容器std::map.一个list里面全是pair(两位的tuple)。内部构造是由红黑树完成的,键值必须可排序。
函数原型 | 解释 |
fromList :: Ord k => [(k, a)] -> Map k a | 将一个关联列表转换成一个map |
insert :: Ord k => k -> a -> Map k a -> Map k a | 插入一对键值 |
empty :: Map k a | 返回一个空map |
null :: Map k a -> Bool | 测试一个map是否非空 |
size :: Map k a -> Int | 返回map大小 |
singleton :: k -> a -> Map k a | 由参数构建一个pair( |
lookup :: Ord k => k -> Map k a -> Maybe a | 查找键,找到后返回对应的值 |
member :: Ord k => k -> Map k a -> Bool | 查找键是否存在 |
map、filter | 类似list中的函数,只针对value(与key无关) |
keys、elems | 返回由key或者value组成的list |
toList :: Map k a -> [(k, a)] | 由map生成对应的list |
fromListWith :: Ord k => (a -> a -> a) -> [(k, a)] -> Map k a | 类似于multimap,可以由一个key对应多个键值,参数1选择key值相同的键如何处理 |
insertWith :: Ord k => (a -> a -> a) -> k -> a -> Map k a -> Map k a | insert的复数版,如果存在相同key,由参数1决定如何处理value |
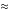 std::make_pair)
std::make_pair)Data.Map里面还有不少函数,常见的操作已经都列举在上面了。
Data.Set
与STL::set类似的数据结构,键值唯一。
函数原型 | 解释 |
fromList :: Ord a => [a] -> Set a | 与map中的类似,将list转化为set |
difference :: Ord a => Set a -> Set a -> Set a | 返回第一个有第二个没有的元素集 |
union :: Ord a => Set a -> Set a -> Set a | 取并集 |
null,size,member,empty,singleton,insert,delete | 与map的接口功能类似 |
isSubsetOf :: Ord a => Set a -> Set a -> Bool | 判断是否子集 |
isProperSubsetOf :: Ord a => Set a -> Set a -> Bool | 判断是否真子集 |
map和filter | 也类似于map |
这里还讨论了Data.List.nub的执行效率问题,nub要求List元素具有Eq类型类,而要使用集合来去除重复元素,必须是Ord类型类。后者的执行速度比前者,前者在大list时不如setNub(但是setNub不稳定)。
自定义模块
自定义模块的模块名与文件名必须一致(这点类似matlab中的.m文件)。格式是:
module Xxx
(fun1,fun2..)
where fun1 :: a->b->c
fun1=…
fun2::…
注意模块名首字母大写。如果要采用分层的方法,则新建一个文件夹,为模块名(如Data),然后建文件(如List),导入时把整个文件夹放在引用它的文件的同一目录下。注意声明的时候前面要加上限定符(如module Data.List)。
虽然module看起来很类似C中间的Struct,但是还是有本质的不同,最明显的就是它只封装了一系列的函数,而C中间则只能存放变量。另外就是Haskell并不支持面向对象。