分享一下最近学习到的豆瓣搜索页爬虫。
链接为:https://search.douban.com/movie/subject_search?search_text={search_text}&cat=1002 ,其中{search_text}为url编码后的搜索关键字。
请求后查看源码,可以发现,搜索结果的内容并没有出现在源码里面。

那么,第一时间反应就是,应该就是ajax一部请求后再渲染到页面上去的。可是,当打开chrome的检查模式时,发现并没有发生异步请求。(xhr类型的文件就是异步请求后返回的结果)

既然不是ajax请求,数据会不会藏在js文件里面呢,打开js,然后选择某部电影的名称去搜索,结果啥也没有。搜索了很多部电影,还是一样的结果。
后来发现,请求页面的源代码里面的window.__DATA__,每次请求都不一样,而且看样子像是经过了base64编码后的字符串,果断设置断点。
果然,搜索结果并没有渲染出来,原来数据就藏在了请求链接的源代码里面。那么先试了一下最简单粗暴的方法,直接对这个字符串进行base64解码。一看结果,果然,没这么简单。
好了,既然不能直接解码,那么就找一下解码的方法。点击单步运行继续调试。发现,当执行完bundle.js文件的时候,页面被渲染出来了,有理由怀疑,这里将window.__DATA__的数据进行解码了。直接在那个文件里面搜__DATA__。
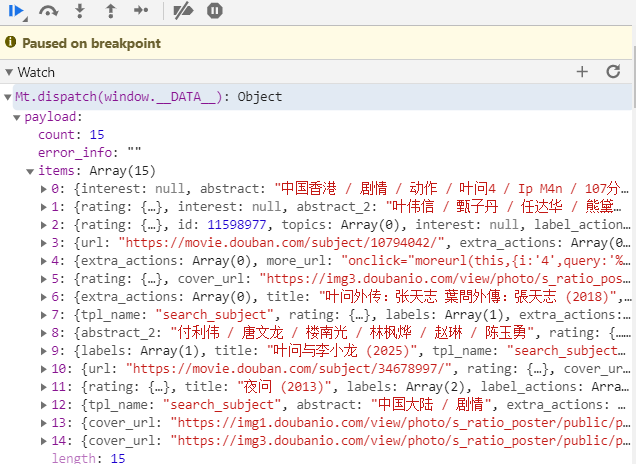
在5千多行的地方找到了这个数据,观察了一下这个js文件,像是用了Packer进行js混淆了,先在这里设个断点。运行后,在右侧watch地方将Mt.dispatch(window.__DATA__)输入进去观察一下。发现数据出来了。
好了,既然发现了数据是在这里解码出来了,那么找到解码的方法,再进行模拟不就行了吗。定位一下Mt.dispatch()方法的位置。
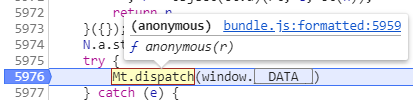
原来就在它的头顶。

那么,重新设置断点,将断点设置在try里面的return那句上。

这个r不正是__DATA__的数据吗。好,接着单步运行。

点击之后发现r的值变了,这里通过右侧的call stack前一个调用的函数。
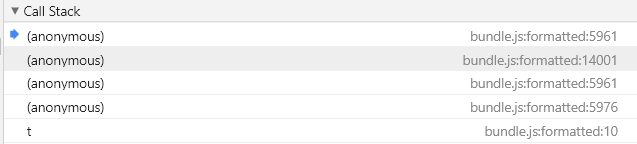
可以发现调用的函数如下。
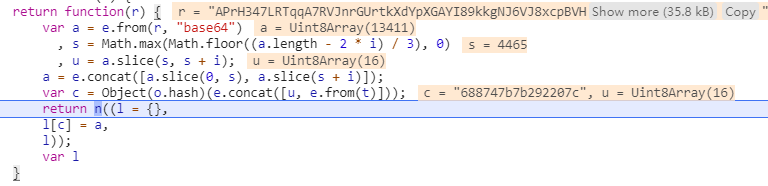
数据经过一系列处理后,再返回一个键为‘688747b7b292207c’的json数据,那么先定位每一个处理数据的函数,看看是怎么实现的。很悲催,当定位到第一个处理方法的时候,发现该方法的实现,在另一个js文件。
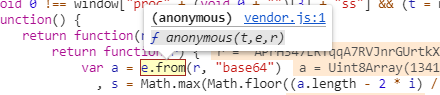
这个js文件也是经过了js混淆,很难看出里面函数的调用逻辑,而且这次返回的结果还不是最终需要的数据。先不管那么多,单步调式到数据出来再说了。
最后发现,数据接着处理了好几次,才会出现最终需要的数据。完全傻眼了,去百度吧,但是找了好久,都没看到解决的方法,再快要放弃的时候,终于找到了大佬。原文链接是:https://mp.weixin.qq.com/s/2mpu_oY2-M0wcLvf1eU7Sw
这位大佬将每一个处理的函数都扣了出来,牛逼。按照他的步骤,最后成功获取到了需要的数据(推文里面的是图书搜索,将链接换成电影搜索的一样可行)。

最后再总结一下,这个js逆向真的很费时间,个人还是觉得用selenium或者pyppeteer开发会比较简单。