话不多说,直接进入正题,这次采集的对象是B站吃播up主,山药村二牛,本人一直挺喜欢他的视频,所以想采集一下他的视频信息,然后分析数据,看下他视频的情况。
首先是爬虫部分,采集的逻辑是从视频页将每个视频的信息和地址采集下来,再请求地址采集视频的弹幕。
进入视频页,https://space.bilibili.com/382534165/video,将中间的id换掉就是其他up主了。查看源码并没有视频的信息,所以可能是用异步加载的方式加载数据的,那么用谷歌浏览器的检查模式,很容易发现视频的数据都在下面那个请求的响应体中,返回的是json数据。
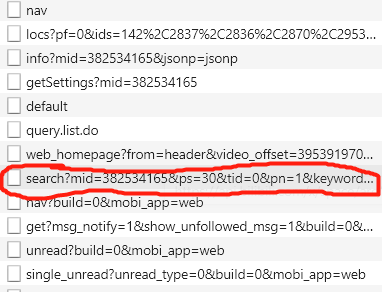

视频的信息都在里面了,所以可以直接请求这个接口就可以获取到信息了,而该接口的请求参数也比较容易分析。
https://api.bilibili.com/x/space/arc/search?mid=382534165&ps=30&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp
mid是up主的id,ps返回的视频数量,tid在后面的请求都不变,所以可以直接赋为0,pn是页数,后面的参数也直接复制即可。
下面就是爬取弹幕了,弹幕的话本人并没有在检查模式里面找到,然后通过百度,弹幕数据都在这一个接口中。很明显cid就是用于标识视频的,那么获取到cid就可以了。后来我才发现,这里最多只能获取1000条弹幕。
http://comment.bilibili.com/{cid}.xml
然后在视频信息里面并没有cid的信息,所以先从从视频播放页里面找。可以看到下面这一个接口返回的数据就有cid。
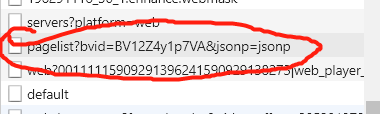

然后看该接口的请求参数,只需要bvid就可以了,而bvid在视频信息里面就可以提取到,那么分析到此结束了,开始爬虫。
这里我使用scrapy框架,首先编写items,主要分为两个视频的和弹幕的,视频有title标题,aid,bvid,comment-评论数,created_time-发布时间,length-视频长度,play-播放量,cid。
title = scrapy.Field() aid = scrapy.Field() bvid = scrapy.Field() comment = scrapy.Field() created_time = scrapy.Field() length = scrapy.Field() play = scrapy.Field() cid = scrapy.Field()
弹幕就只有cid,和content-内容。
cid = scrapy.Field() content = scrapy.Field()
下面是爬取的函数。
def start_requests(self):
base_url = 'https://api.bilibili.com/x/space/arc/search?mid=382534165&ps=30&tid=0&pn={}&keyword=&order=pubdate&jsonp=jsonp'
headers = self.settings.get('DEFAULT_REQUEST_HEADERS')
for pn in range(1, 10):
url = base_url.format(pn)
yield scrapy.Request(url=url, headers=headers, callback=self.parse_video_info)
def parse_video_info(self, response):
detail = json.loads(response.text)
headers = self.settings.get('DEFAULT_REQUEST_HEADERS')
for info in detail.get('data').get('list').get('vlist'):
item = BilibiliErniuItem()
item['title'] = info.get('title')
item['aid'] = info.get('aid')
item['bvid'] = info.get('bvid')
item['comment'] = info.get('comment')
item['created_time'] = info.get('created')
item['length'] = info.get('length')
item['play'] = info.get('play')
cid_url = 'https://api.bilibili.com/x/player/pagelist?bvid={}&jsonp=jsonp'.format(item['bvid'])
yield scrapy.Request(url=cid_url, headers=headers, meta={'item': item}, callback=self.get_bullet_chat_url)
def get_bullet_chat_url(self, response):
detail = json.loads(response.text)
headers = self.settings.get('DEFAULT_REQUEST_HEADERS')
item = response.meta['item']
cid = detail.get('data')[0].get('cid')
item['cid'] = cid
bullet_chat_url = 'http://comment.bilibili.com/{}.xml'.format(cid)
yield scrapy.Request(url=bullet_chat_url, headers=headers, meta={'cid': cid}, callback=self.parse_bullet_chat)
yield item
def parse_bullet_chat(self, response):
sel = scrapy.Selector(response)
item = ErniuBulletChatItem()
item['cid'] = response.meta['cid']
item['content'] = sel.xpath('//d//text()').extract()
yield item
然后在pipelines实现数据的保存,这里直接保存为csv文件即可,注意的是保存时数据的分隔符用了'|',避免使用',',否则会影响pandas读入。
def __init__(self):
self.dirs = 'E:\dataset\bilibili_erniu\video.csv'
if not os.path.exists(self.dirs):
with open(self.dirs, 'w', encoding='utf-8')as fp:
fp.write('title|aid|bvid|comment|created_time|length|play|cid
')
self.buttet_chat_dir = 'E:\dataset\bilibili_erniu\buttet_chat'
if not os.path.exists(self.buttet_chat_dir):
os.makedirs(self.buttet_chat_dir)
def process_item(self, item, spider):
if isinstance(item, BilibiliErniuItem):
with open(self.dirs, 'a', encoding='utf-8') as fp:
fp.write(item['title'] + '|' + str(item['aid']) + '|' + item['bvid'] + '|' + str(item['comment']) + '|' + str(item['created_time']) + '|' + item['length'] + '|'
+ str(item['play']) + '|' + str(item['cid']) + '
')
return item
else:
filename = str(item['cid']) + '.csv'
if not os.path.exists(self.buttet_chat_dir + '\' + filename):
with open(self.buttet_chat_dir + '\' + filename, 'w', encoding='utf-8')as fp:
fp.write('content' + '
')
for content in item['content']:
fp.write(content + '
')
return item
最后在setting加上请求头,以及启用piplines即可。
以上就是爬虫部分,下面是数据分析。
首先是读入数据,查看数据。

数据读入正常,那么查看是否有缺失值。
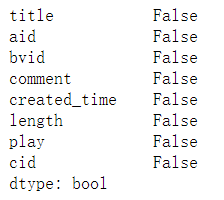
没有,那么来处理一下数据,首先是将created_time转换为日期的格式。
from datetime import datetime
def change_time(t):
return datetime.fromtimestamp(t).strftime('%Y-%m-%d %H:%M')
def split_date(t):
return t.split(' ')[0]
def split_hour_min(t):
return t.split(' ')[1]
videos['time'] = videos.created_time.apply(change_time) # 时间戳转为年月日时分
videos['date'] = videos.time.apply(split_date) # 分出日期
videos['hour_min'] = videos.time.apply(split_hour_min) # 分出时间
videos['year'], videos['month'], videos['day'] = videos.date.str.split('-').str # 年月日分开
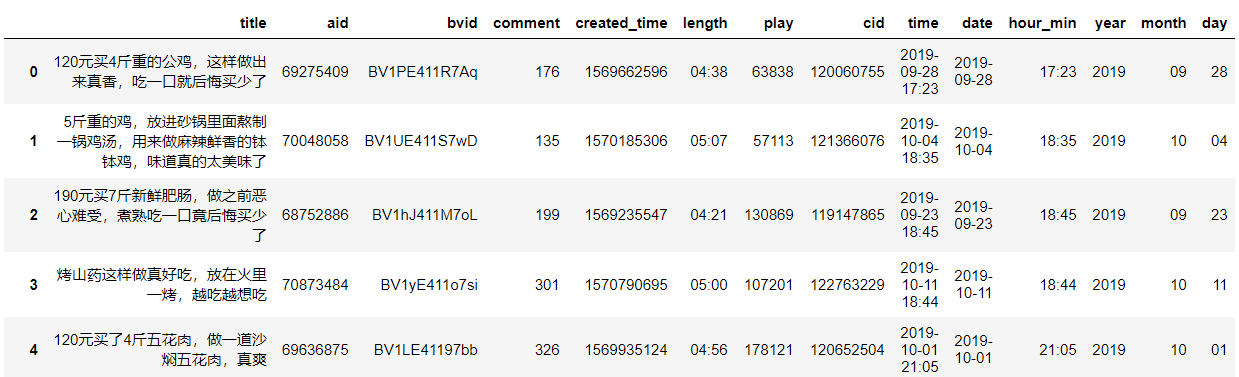
处理完成,接下来将年月日的数据从字符串转换为整型,方便后面的数据可视化。并对这三列进行排序。
videos.year = videos.year.astype('int')
videos.month = videos.month.astype('int')
videos.day = videos.day.astype('int')
videos.sort_values(['year', 'month', 'day'], inplace=True)
下面先取出了年和月的数据。方便可视化时添加时间轴。
years = set(videos.year)
months = []
for year in years:
months.append(set(videos[videos['year'].isin([year])].month))
使用pyecharts库进行可视化,这里展示的数据是播放量和评论数随时间变化的柱状图。
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
timeline_2020 = Timeline()
for m in months[2]:
bar = (
Bar()
.add_xaxis(list(videos[videos.year.isin([2020])][videos.month.isin([m])].day))
.add_yaxis("播放量", list(videos[videos.year.isin([2020])][videos.month.isin([m])].play), yaxis_index=0,)
.add_yaxis("评论数", list(videos[videos.year.isin([2020])][videos.month.isin([m])].comment), yaxis_index=1)
.extend_axis(
yaxis=opts.AxisOpts(
name="评论数",
type_="value",
position="right",
axislabel_opts=opts.LabelOpts(formatter="{value}"),
)
)
.set_global_opts(title_opts=opts.TitleOpts("山药村二牛{}年{}月视频播放量和评论数".format(2020, m)))
)
timeline_2020.add(bar, '{}月'.format(m))

这里仅展示了2020年的,但是这样并不能看出二牛视频的播放量波动情况。所以再使用折线图展示。
from pyecharts.charts import Line
line = (
Line()
.set_global_opts(
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
title_opts=opts.TitleOpts("山药村二牛视频播放量和评论数折线图"),
datazoom_opts=[opts.DataZoomOpts()],
)
.add_xaxis(xaxis_data=list(videos_new.time))
.add_yaxis(
series_name="播放量",
y_axis=list(videos_new.play),
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
yaxis_index=0,
)
.add_yaxis(
series_name="评论数",
y_axis=list(videos_new.comment),
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
yaxis_index=1,
)
.extend_axis(
yaxis=opts.AxisOpts(
name="评论数",
type_="value",
position="right",
axislabel_opts=opts.LabelOpts(formatter="{value}"),
)
)
)
 从该图可以看出,二牛视频的播放量和评论数波动不大,中间的最高点我去找了一下那个视频,原来是华农送竹鼠那期,怪不得那么多播放量。
从该图可以看出,二牛视频的播放量和评论数波动不大,中间的最高点我去找了一下那个视频,原来是华农送竹鼠那期,怪不得那么多播放量。
接下来对视频长度和播放量使用了散点图可视化。
from pyecharts.charts import Scatter
c = (
Scatter()
.add_xaxis(list(videos_new.length))
.add_yaxis("播放量", list(videos_new.play))
.set_global_opts(
title_opts=opts.TitleOpts(title="山药村二牛视频时长-播放量散点图"),
visualmap_opts=opts.VisualMapOpts(type_="size", max_=1000000, min_=27000),
)
)
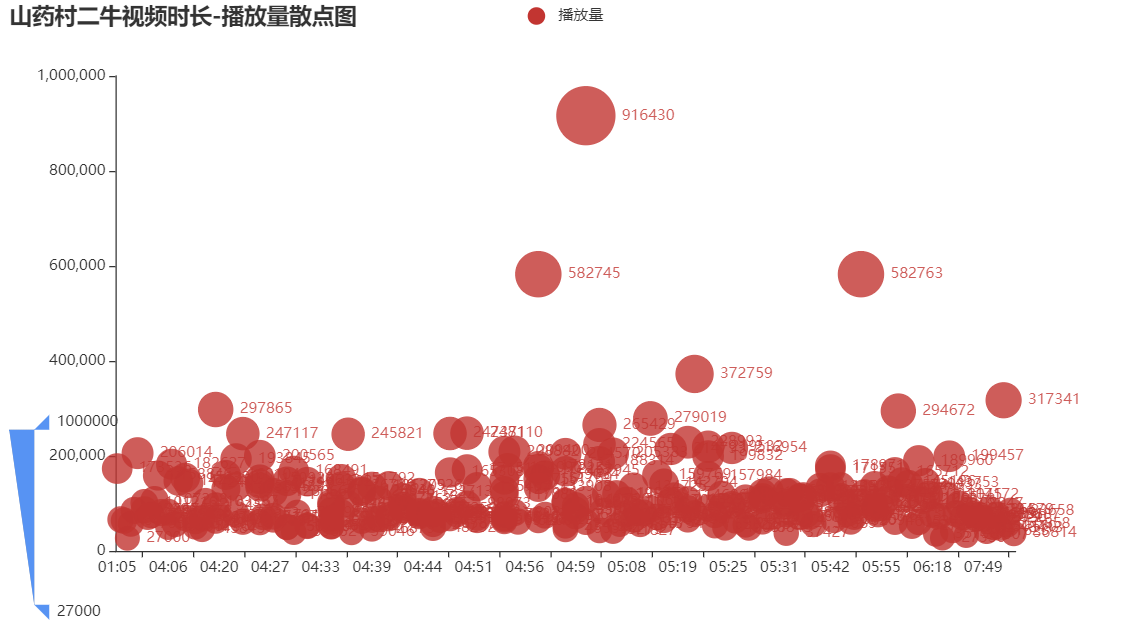
从这个图看出二牛的视频播放量和时长无关,播放量大概集中在5万左右。
接下来将标题做成词云图,看看二牛最喜欢用什么标题。
import jieba
import re
from pyecharts.charts import WordCloud
from collections import Counter
title_cut = []
def tokenizer(title):
return jieba.lcut(title)
for t in videos_new.title:
t = re.sub(r"[0-9,,。?!?!【】]+", "", t)
title_cut += tokenizer(t)
title_count = []
for key, value in Counter(title_cut).items():
title_count.append((key, value))
w = (
WordCloud()
.add(series_name="标题词云", data_pair=title_count, word_size_range=[10, 100])
.set_global_opts(
title_opts=opts.TitleOpts(
title="标题词云", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
)
这里我使用的是jieba库进行分词,用正则简单处理了一下文本,并没有加入停用词。

从词云图看出,二牛一般都会用’吃‘什么,’做‘什么作为标题,’好吃‘,’过瘾‘,’真爽‘等字眼也出现得不少。
最后,用上了一直没用的弹幕做成词云图,因为弹幕最多只有1000条,所以就不做折线图这些的可视化了。
buttet_chat = []
path = 'E:\dataset\bilibili_erniu\buttet_chat'
dirs = os.listdir(path)
for file in dirs:
with open(os.path.join(path, file), 'r', encoding='utf-8')as fp:
content = fp.readlines()
buttet_chat += content[1:-1]
buttet_chat_cut = []
for b in buttet_chat:
b = b.strip()
b = re.sub(r"[0-9,,。?!?!【】]+", "", b)
buttet_chat_cut += tokenizer(b)
buttet_chat_count = []
for key, value in Counter(buttet_chat_cut).items():
buttet_chat_count.append((key, value))
w = (
WordCloud()
.add(series_name="弹幕词云", data_pair=buttet_chat_count, word_size_range=[10, 100])
.set_global_opts(
title_opts=opts.TitleOpts(
title="弹幕词云", title_textstyle_opts=opts.TextStyleOpts(font_size=23)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
)

从词云图可以看出,大家一般喜欢发的弹幕的是’我‘,’许愿‘等,从小点的词可以看出也是有很多许愿的内容,例如:’四级‘,’面试‘,’不挂科‘,’脱单‘等。因为二牛在吃饭的时候有一个很有趣的点头,所以大家都喜欢在他点头的时候发弹幕,祈祷愿望成真。
好了,这一次的练手就到此结束了。