转自:
https://blog.csdn.net/shuhaojie/article/details/74205393
https://blog.csdn.net/shuhaojie/article/details/75123953
本博客是个人在学习Spark过程中的一些总结,方便个人日后查阅,同时里面出现的一些关键字也可以作为后来一些读者学习的材料。若有问题,欢迎评论,一定知无不言。
1.Tuple:Tuple就是用来把几个数据放在一起的比较方便的方式,注意是“几个数据”,因此没有Tuple1这一说。
-
val scores=Array(Tuple2(1,100),Tuple2(2,90),Tuple2(3,100),Tuple2(2,90),Tuple2(3,100))
-
val content=sc.parallelize(scores)
-
val data=content.countByKey()
data: scala.collection.Map[Int,Long] = Map(1 -> 1, 3 -> 2, 2 -> 2)2.saveAsText:文件输出的方法,可以将文件输出到HDFS,也可以输出到本地
sc.textFile(“text1.txt”).flatMap(_.split(“”)).map(word=>(word,1)).reduceByKey(_+_,1).saveAsTextFile(text2.txt) I ask her why not go(not,1)(ask,1)(I,1)(why,1)(go?,1)(her,1)3.job:为了响应Spark的action,包含很多task的并行计算,可以认为是Spark RDD 里面的action,每个action的计算会生成一个job。用户提交的Job会提交给DAGScheduler,job会被分解成Stage和Task。每个Job是一个计算序列的最终结果,而这个序列中能够产生中间结果的计算就是一个stage。为了理解这一概念,我们举例说明。
1)将一个包含人名和地址的文件加载到RDD1中
2)将一个包含人名和电话的文件加载到RDD2中
3)通过name来Join RDD1和RDD2,生成RDD3
4)在RDD3上做Map,给每个人生成一个HTML展示卡作为RDD4
5)将RDD4保存到文件
6)在RDD1上做Map,从每个地址中提取邮编,结果生成RDD5
7)在RDD5上做聚合,计算出每个邮编地区中生活的人数,结果生成RDD6
8) Collect RDD6,并且将这些统计结果输出到stdout
2)将一个包含人名和电话的文件加载到RDD2中
3)通过name来Join RDD1和RDD2,生成RDD3
4)在RDD3上做Map,给每个人生成一个HTML展示卡作为RDD4
5)将RDD4保存到文件
6)在RDD1上做Map,从每个地址中提取邮编,结果生成RDD5
7)在RDD5上做聚合,计算出每个邮编地区中生活的人数,结果生成RDD6
8) Collect RDD6,并且将这些统计结果输出到stdout
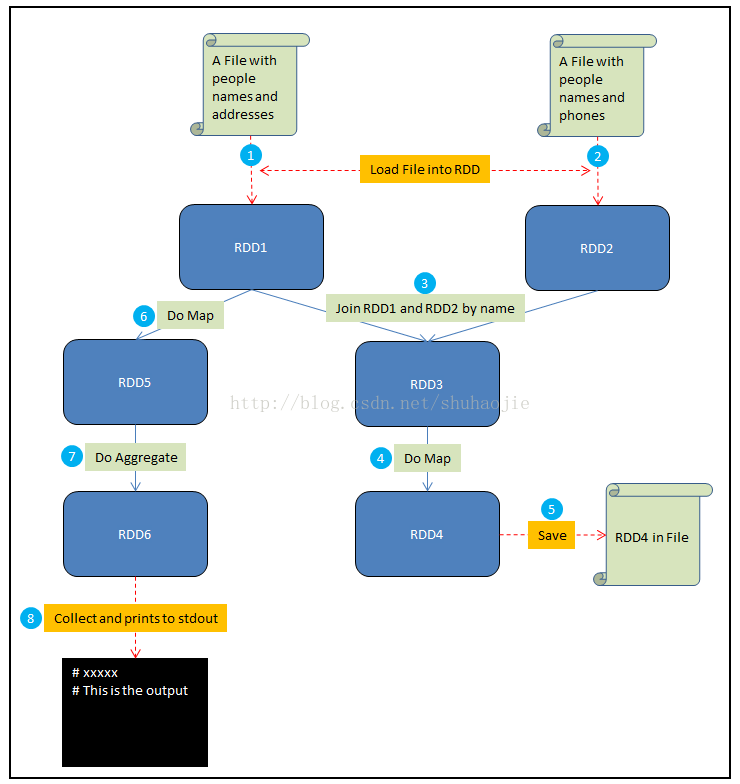
步骤(1、2、3、4、6、7)被Spark组织成stages,每个job则是一些stage序列的结果。对于一些简单的场景,一个job可以只有一个stage。但是对于数据重分区的需求(比如第三步中的join),或者任何破坏数据局域性的事件,通常会导致更多的stage。
4.job和stage的区别:通常action对应job,transformation对应stage。怎么样才算是一个stage呢?划分stage的依据是数据是否需要进行重组。action是一种操作级别,会生成 job,用通俗的话讲就是把RDD变成了非RDD(数据聚合的过程),RDD是只读的,换句话说我们想要打印(println)必须要经过action级别的操作。transformation也是一种操作级别,会生成stage,用通俗的话讲就是把一种形式的RDD变成另外一种形式的RDD,经过transformation级别的操作数据会进行重组。
常见的stage有:
map,filter,flatMap,mapPartitions,mapPartitionsWithIndex,sample,union,intersectiondistinct,groupByKey,reduceByKey,aggregateByKey,sortByKey,join,cogroup,cartesian
pipe,coalesce,repartition,repartitionAndSortWithinPartitions
reduce,collect,count,first,take,takeSample,takeOrdered,saveAsTextFile,saveAsSequenceFile,saveAsObjectFile,countByKey,foreach5.task:被送到executor上的工作单元,task 是执行job 的逻辑单元 ,task和job的区别在于:job是关于整个输入数据和面向整个集群(还没有分机器)的概念,task一般是处理输入数据的子集,并且和集群中的具体一台机器相联系。在task 会在每个executor 中的cpu core 中执行。每个Stage里面Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的。RDD在计算的时候,每个分区都会起一个task,所以rdd的分区数目决定了总的的task数目。申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的task。比如的RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个两2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。如果资源不变,你的RDD只有2个分区,那么同一时刻只有2个task运行,其余18个核空转,造成资源浪费。这就是在spark调优中,增大RDD分区数目,增大任务并行度的做法。Spark上分为2类task:shuffleMapTask和resultTask。
6.Driver:在Driver中,RDD首先交给DAGSchedule进行Stage的划分,然后底层的调度器TaskScheduler就与Executor进行交互,Driver和下图中4个Worker节点的Executor发指令,让它们在各自的线程池中运行Job,运行时Driver能获得Executor发指令,让它们在各自的线程池中运行Job,运行时Driver能获得Executor的具体运行资源,这样Driver与Executor之间进行通信,通过网络的方式,Driver把划分好的Task传送给Executor,Task就是我们的Spark程序的业务逻辑代码。
7.下划线_:Scala语言中下划线最常用的作用是在集合中使用
val newArry= (1 to 10).map(_*2)2 4 6 8 108.reduce:它是这样一个过程:每次迭代,将上一次的迭代结果与下一个元素一同执行一个二元的func函数。可以用这样一个形象化的式子来说明:
-
reduce(func, [1,2,3] ) = func( func(1, 2), 3)
-
var list=List(1,2,3,4,5,6,7)
-
list.reduce(_-_)
9.闭包:闭包是一个函数,返回值依赖于声明在函数外部的一个或多个变量。闭包通常来讲可以简单的认为是可以访问一个函数里面局部变量的另外一个函数。
-
/*1.more是一个自由变量,其值及类型是在运行的时候得以确定的
-
2.x是类型确定的,其值是在函数调用的时候被赋值的
-
def add(more:Int) = (x:Int) => x+ more
-
val add1 = add(1)
-
println(add1(100)) 运行结果:101
10.split:将一个字符串分割为子字符串,然后将结果作为字符串数组返回。
-
var words="123456123" words.split("12") res0: Array[String] = Array("", 3456, 3)
-
var words="123456123" words.split("123") res0: Array[String] = Array("", 456)
-
var words="123456123" words.split("") res0: Array[String] = Array(1, 2, 3, 4, 5, 6, 1, 2, 3)
-
var words="123456123" words.split("10") res0: Array[String] = Array(123456123)
11.filter:使用filter方法,你可以筛选出集合中你需要的元素,形成一个新的集合。
-
val x = List.range(1, 10)
-
val evens = x.filterNot(_ % 2 == 0)
12.collect:将RDD转成Scala数组,并返回。
13.Integer.parseInt:将整数的字符串,转化为整数
-
val b="123"
-
val a=Integer.parseInt(b)
-
println(a)//打印结果123
14.flatMap,Map和foreach:(1)Map:对rdd之中的元素进行逐一进行函数操作映射为另外一个rdd,map函数会对每一条输入进行指定的操作,然后为每一条输入返回一个对象
(2)flatMap函数则是两个操作的集合——正是“先映射后扁平化”,分为两阶段: 操作1:同map函数一样:对每一条输入进行指定的操作,然后为每一条输入返回一个对象。操作2:最后将所有对象合并为一个对象(3)foreach无返回值(准确说返回void)
(2)flatMap函数则是两个操作的集合——正是“先映射后扁平化”,分为两阶段: 操作1:同map函数一样:对每一条输入进行指定的操作,然后为每一条输入返回一个对象。操作2:最后将所有对象合并为一个对象(3)foreach无返回值(准确说返回void)
15.RDD:Resilient Distributed Datasets,弹性分布式数据集。举例说明:如果你有一箱香蕉,让三个人拿回家吃完,这时候要把箱子打开,倒出来香蕉,分别拿三个小箱子重新装起来,然后,各自抱回家去啃。Spark和很多其他分布式计算系统都借用了这种思想来实现并行:把一个超大的数据集,切分成N个小堆,找M个执行器(M < N),各自拿一块或多块数据慢慢玩,玩出结果了再收集在一起,这就算执行完了。那么Spark做了一项工作就是:凡是能够被我算的,都是要符合我的要求的,所以spark无论处理什么数据先整成一个拥有多个分块的数据集再说,这个数据集就叫RDD。