自己发现了网上有好多很早就开始准备了考试了,然而自己现在才起步。自己的笔记感觉都是在抄书。可能因为什么都不懂吧。
1.2 存储器系统
存储器是用来存放程序和数据的部件,它是一个记忆装置,是计算机能够实现“存储程序控制”的基础。计算机系统中,规模较大的存储器往往分成若干级,称为存储器系统。
传统的存储器系统一般分为:高速缓冲存储器(Cache)、主存、辅存三级。
主存:可由CPU直接访问,存取速度快,但是容量较小,一般存放当前正在执行的程序和数据。
辅存:设置在主机外部,它的存储容量大,价格较低,但存取速度较慢,一般存放暂时不参与运行的程序和数据。
CPU不可以直接访问辅存,辅存中的程序和数据在需要时才传送到主存,因此辅存是主存的补充和后援。
当CPU速度很高时,为使访问存储器的速度能与CPU的速度相匹配,在主存和CPU间增设一级Cache.
Cache:存取速度比主存更快,但容量更小,用于存放当前最急需处理的程序和数据,以便快速地向CPU提供指令和数据。
因此,计算机采用多级存储器体系,确保能够获得尽可能高的存取速率,同时保持较低的成本。
多层级的存储体系之所以能用低投入换来较高的存取速率,得益于局部性原理。
局部性原理是指程序在执行时呈现出局部性规律,即在一较短的时间内,程序的执行仅限于某个部分。所访问的存储空间也仅局限于某个区域。
程序局部性包括时间局部性和空间局部性,
时间局部性是指程序中的某条指令一旦执行,不久以后该指令可能再次执行。产生时间局部性典型原因:程序中存在大量的循环操作。
空间局部性是指一旦程序访问了某个存储单位,不久以后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址可能集中在一定的范围内,其典型情况是程序顺序执行。
存储器中数据常用的存取方式有:顺序存储、直接存取、随机存取和相联存取四种。
(1)顺序存取:存储器的数据以记录的形式进行组织。对数据的访问必须按特定的线性顺序进行。磁带存储器采用顺序存取的方式。
(2)直接存取:与顺序存取相似,直接存取也使用一个共享的读写装置对所有的数据进行访问。但是,每个数据块都拥有唯一的地址标识,读写装置可以直接移动到目的数据块所在位置进行访问。存取时间也是可变的。磁盘存储器采用直接存取的方式。
(3)随机存取:存储器的每一个可寻址单元都具有自己唯一的地址和读写装置,系统可以在相同的时间内对任意一个存储单元的数据进行访问,与先前的访问序列无关。
主存储器采用随机存取的方式。
(4)相联存取:相联存取也是一种随机存取的形式,但是选择某一单元进行读写是取决于其内容而不是其地址。与普通的随机存取方式一样,每个单元都有自己的读写装置,读写时间也是一个常数。
使用相联存取方式,可以对所有的存储单元的特定位进行比较,选择符合条件的单元进行访问。为了提高地址映射的速度,Cache采取相联存取的方式。
1.2.1 主存储器
主存用来存放计算机运行期间所需要的程序和数据,CPU可直接随机地进行读/写。主存具有一定的容量,存取速度较高。
由于CPU要频繁地访问主存,所以主存的性能在很大程度上影响了整个计算机系统的性能。
根据工艺和技术不同,主存可分为随机存储器和只读存储器。
1.随机存取存储器(Random Access Memory,RAM)
既可以写入也可以读出,但断电后信息无法保存,因此只能用于暂存数据。
RAM 又可分为DRAM (Dynamic RAM,动态RAM)和SRAM(Static RAM,静态RAM )两种。
DRAM 和SRAM的优缺点:
DRAM的信息会随时间逐渐消失,因此需要定时对其进行刷新维持信息不丢失;
SRAM在不断电的情况下,信息能够一直保持而不会丢失。
DRAM的密度大于SRAM且更加便宜,但SRAM速度快,电路简单(不需要刷新电路),
然而容量小,价格高。
2.只读存储器(Read Only Memory ,ROM)
可以看作RAM的一种特殊形式,其特点是:存储器的内容只能随机读出而不能写入。
这类存储器常用来存放那些不需要改变的信息。由于信息一旦写入存储器就固定不变了,即使断电,写入的内容也不会丢失,所以又称为固定存储器。
ROM一般用于存放系统程序BIOS(Basic Input Output System,基本输入输出系统)。
3.内存编址方法在计算机系统中,存储器中每个单元的位数是相同且固定的,称为存储器编址单位。
不同的计算机,存储器编址的方式不同,主要有字编址和字节编址。
内存一般以字节(8位)为单位,或者以字为单位(字的长度可大可小,例如16位或者32位等,
一般试题中,会给出字的大小)。
例子(看这道例题跟网上好多解释不太一样):
内存地址从AC000H到C7FFFH, 则总共有()K个地址单元,如果该内存地址按字(16bit)编码,由28片
存储器芯片构成。已知构成此内存的芯片每片有16K个存储单元,则该芯片每个存储单元存储()位。
A=10 B=11 C=12 D=13 E=14 F=15
C7FFFH-AC000H+1H=
C7FFF
- AC000
------------------- 1>.7-12,需要向高位:C处借1。16+7=23;23-C------> 23-12=11; 11---->B
2>.高位C就变成了B 。B-A=1
3>.所以结果为:1BFFF
4>.
1BFFF
+
1
-----------------
1>.B+1=C
2>.结果就是1C000 H
C7FFFH-AC000H+1H=1C000H,
把1C000H转换为10进制数得到114688,再化为K,即有114688/1024=112K个地址单元。
已知内存地址按字(16bit)编址,则共有112K×16位。内存由28片存储器芯片构成,每片有16K个存储单元,则该芯片每个存储单元存储(112K×16)/(28×16K)=4位。
假设有一个十六进数 2AF5 直接计算就是: 5×16º+F×16¹+A×16²+2×16³=10997
1C000=0*16(0)+0*16(1)+0*16(2)+C*16(3)+1*16(4)=C*16(3)+16(4)=12*16(3)+16(4)=12*4096+65536=49152+65536=114688
1.2.2辅助存储器
1.磁带存储器
是一种顺序存取的设备,其特点:存取时间较长,但存储容量大,便于携带,价格便宜。磁带应用场景越来越少,目前主要用于资料的归档保存。
2.硬盘存储器
在硬盘中,信息分布呈:记录面、圆柱面、磁道和扇区。
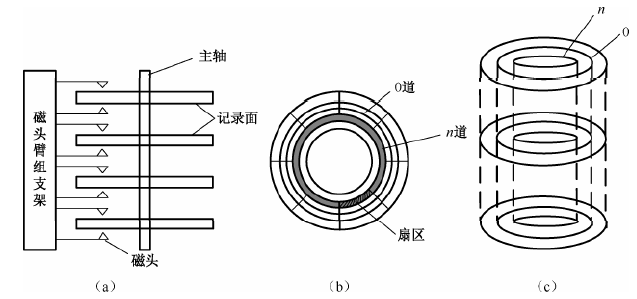
一台硬盘驱动器中有多个磁盘片,每个盘片有两个记录面,每个记录面对应一个磁头。所以记录面号就是磁头号,如图(a)。
所有磁头安装在一个公用的传动设备或者支架上,磁头一致地沿盘面径向移动,单个磁头不能单独移动。
在记录面上,一条条磁道形成一组同心圆,最外圈的磁道为0号,往内则磁道号逐步增加,如图(b)所示。
在一个盘组中,各记录面上相同编号(位置)的各磁道构成一个柱面,如图(c)所示。
若每个磁盘片有m个磁道,则该磁盘共有m个柱面。引入柱面的概念是为了提高硬盘的存储速度。
当主机要存入一个较大的文件时,若一条磁道存不完,就需要存放在几条磁道上。此时,应首先将一个文件尽可能地存放在同一柱面中。如果仍存放不完,再存入相邻的柱面内。
通常将一条磁道划分为若干个段,每个段称为一个扇区或扇段,每个扇区存放一个定长的信息块(例如,512个字节),如图(b)所示。
一条磁道划分多少扇区,每个扇区可存放多少字节,一般由操作系统决定。磁道上的扇区编号从1开始,磁头或柱面编号是从0开始的。
在磁盘上进行信息的读写时,首先需要定位到目标磁道,这个过程称之为寻道,寻道所消耗的时间称为寻道时间,定位到目标磁道后,需要定位到目标扇区,此过程通过旋转盘片完成,平均旋转半圈可到目标位置。
磁盘访问时间(存取时间)=寻道时间+旋转延迟时间
1.2.3 Cache 存储器
Cache的功能是提高CPU数据输入输出的速率,突破所谓的“冯-诺依曼瓶颈”,即CPU与存储系统间数据传送宽带限制。
高速存储器能以极高的速率进行数据访问,但其价格高,计算机内存完全由这种高速存储器组成,就会大大增加计算机的成本。
通常在CPU和内存之间设置小容量的Cache。Cache容量小但速度快,内存速度较低但容量大,通过优化调度算法,系统性能会大大改善,使存储系统容量与内存相当而访问速度近似Cache。
Cache通常采用相联存储器(ContentAddressable Memory ,CAM)。CAM是一种基于数据内容进行访问的存储设备。
CAM读写数据的操作原理:
当对其写入数据时,CAM 会自动选择一个未用的空单元进行存储;
当读出数据时,是直接给出该数据或者该数据的一部分内容(,而不是给出其存储单元的地址),CAM对所有存储单元中的数据同时进行比较,并标记符合条件的所有数据以供读取。
由于比较是同时、并行进行的,所以,这种基于数据内容进行读写的机制,其速度比基于地址进行读写的方式要快很多。
1.Cache基本原理
使用Cache改善系统性能的依据是程序的局部性原理。根据程序的局部性原理,最近的、未来要用的指令和数据大多局限于正在用的指令和数据,说是存放在与这些指令和数据位置上邻近的单元中。
可以把目前常用或者将要用到的信息预先放在Cache中。当CPU需要读取数据时,首先在Cache中查找是否有所需内容。有:直接从Cache中读取;没有:从内存中读取该数据,然后同时送往CPU和Cache。如果CPU需要访问的内容大多都能在Cache中找到(称为:访问命中),则可以大大提高系统性能。
如果以h代表对Cache的访问命中率("1-h"称为失效率,或者称为未命中率),t1表示Cache的周期时间,t2表示内存的周期时间,以读操作为例,使用"Cache+主存储器"的系统的平均周期为t3.则:
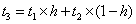
系统的平均存储周期与命中率有很密切的关系,命中率的提高即使很小也能导致性能上的较大改善。
例如:设某计算机主存的读/写时间为100ns,有一个指令和数据合一的Cache,已知该Cache的读/写时间为10ns,取指令的命中率为98%,取数的命中率为95%.在执行某类程序时,约有1/5指令需要存/取一个操作数。假设指令流水线在任何时候都不阻塞,则设置Cache后,每条指令的平均访存时间约为:
(2%×100ns+98%×10ns)+1/5×(5%×100ns+95%×10ns)=14.7ns
百度文库
https://wenku.baidu.com/view/423f7e5376232f60ddccda38376baf1ffc4fe308.html
平均存取速度=Cache存取速度×Cache命中率+主存存取速度×失效率 得出:
(98%×10 ns+2%×100 ns)+1/5×(95%×10 ns+5%×100 ns)=14.7 ns≈15 ns(这里要注意题中条件的各单位与最后计算结果的单位要一致)
(对1/5这块不太能读懂,我理解能力可能比较差吧。。。)
2.映射机制
当CPU发出访存请求后,存储器地址先被送到Cache控制器以确定所需数据是否已在Cache中,若命中则直接对Cache进行访问。 这个过程称为:Cache的地址映射(映像)。
在Cache的地址映射中,主存和Cache将均分成容量相同的块(页)。
常见的映射方法有:直接映射、全相联映射和组相联映射。
(1)直接映像
直接映像方式以随机存取存储器作为Cache存储器,硬件电路较简单。在进行映像时,主存地址被分成三个部分,
从高到低依次为:区号、页号以及页内地址。
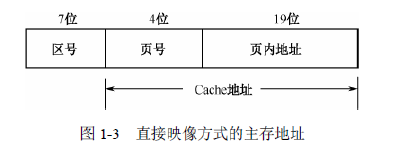
本例中,内存容量为1GB,Cache 容量为8MB,页面的大小为512KB。
直接映射中,先分区,再分页。
一个区的大小就是Cache容量的大小,
1GB的内存容量一共可以分为:1GB/8MB=129个区,区号7位。
每个区分:8MB/512KB=16个页,因为:2∧4=16,所以页号为4位。(开始自己这边不太清楚)
https://wenku.baidu.com/view/82852b9608a1284ac85043a1.html

在直接映像方式中,每个主存页只能复制到某一固定的Cache页中。
直接映像方式的映像规律是:主存中每个区的第0页,只能进入到Cache的第0页。
当前Cache中0号页已被占据,现要将1区第0页(即内存的16页)调入Cache,此时就会发生冲突。
直接映像的块冲突率非常高。
在Cache中,为每一页设立一个Cache标记,该标记用于识别当前的Cache块
来自于哪个内存页。
直接映像中,每个区的N号页,都必须进入到Cache的N号页,
所以只需要记录区号即可。根据(4)图中的标记位长度是7位。
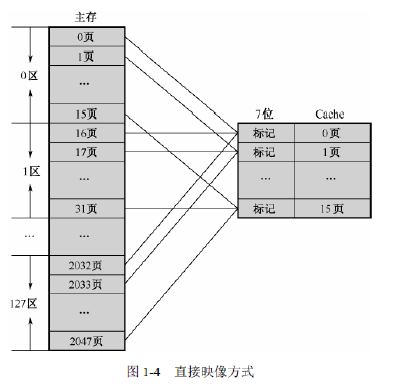
直接映像方式的优点是比较容易实现,缺点是不够灵活,有可能使Cache的存储空间得不到充分利用。
(2)全相联映像
全相联映像使用相联存储器组成的Cache存储器。
在全相联映像方式中,主存的每一页可以映像到Cache的任一页。
如果淘汰Cache中每一页的内容,则可调入任一主存页的内容。
因而较直接映像方式灵活。
在全相联映像方式中,主存地址分为两个部分,
分别为地址部分(主存页标记)和数据部分(页内地址)。
数据部分用于存放数据,而地址部分则存放该数据的存储器地址。
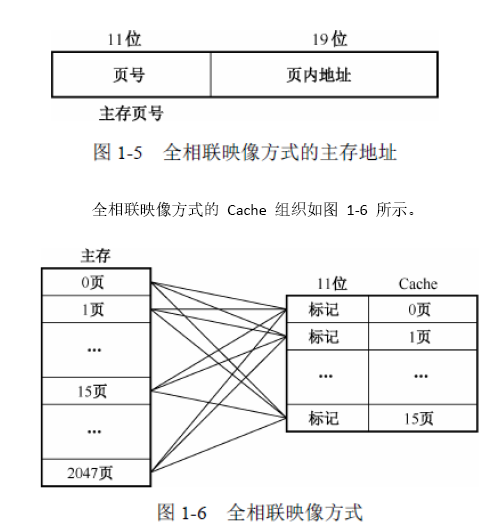
给定的例子中,程序访存时,高11位给出主存页号,低19位给出页内地址。
因为每个Cache页可映像到2048个主存页中的任一页,
每页的Cache标记也需要11位,表明它现在所映像的主存页号。
Cache标记信息位数增加,比较逻辑成本随之增加。
在全相联映像方式中,主存地址不能直接提取Cache页号,
而是
需要将主存页标记与Cache各页的标记逐个比较,直到找到标记符合的页(访问Cache命中),
或者全部比较完后仍无符合的标记(访问Cache失败)。
因此这种映像方式速度很慢,失掉了高速缓存的作用,这是全相联映像方式的最大缺点。
如果让主存页标记与各Cache标记同时比较,则成本又太高。
全相联映像方式因比较器电路难于设计和实现,只适用于小容量Cache。
(3)组相联映像
组相联映像(页组映像)介于直接映像和全相联映像之间,是这两种映像的一种折中方案。
全相联映像方式以页为单位,可自由映像,没有固定的对应关系。
直接映像方式中,主存分组,主存组内的各页与Cache的页之间采取的是固定的映像关系,
但各组均可映像到Cache中。
在组相联映像方式中,主存与Cache都分组,
主存中一个组内的页数与Cache的分组数相同。
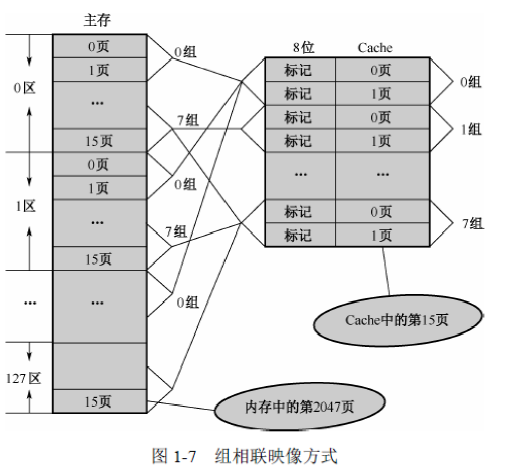
上例中:主存分128个区,每个区8个组,每个组2个页。组相联映像方式的主存地址组织:
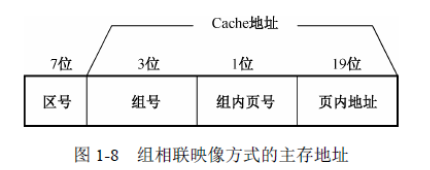
组相联映像的规则是:主存中的组与Cache的组形成直接映像关系,每个组内的页是全相联映像关系。
书中举例:主存1区0页,他在0组中,所以只能进入Cache中的0组中,可任意放置到Cache的0组0页,或是0组1页,无强制要求。
在组相联映像中,Cache中每一页的标记位长度为8位,因为此时除了要记录区号,还得记录租号,即区号7位加组号1位等于8位。
如果Cache中每组只有一页,则组相联映像方式就变成了直接映像方式,
如果Cache每组页数为16页(即Cache只分一组),则就是全相联映像。
因此,在具体设计组相联映像时,可以根据设计目标选取某一折中值。
在组相联映像中,由于Cache中每组有若干可供选择的页,
因而它在映像定位方面较直接映像方式灵活;每组页数有限,因此付出的代价不是很大,可以根据设计目标选择组内页数。
希赛教育专家提示:为保障性能,内存与Cache之间的映射往往采用硬件完成,所以Cache对于程序员而言是透明的,程序员编程时,完全不用考虑Cache。
3.替换算法
当Cache产生了一次访问未命中之后,相应的数据应同时读入CPU和Cache。
但是当Cache已存满数据后,新数据必须替换(淘汰)Cache中的某些旧数据最常用的替换算法有以下三种:
(1)随机算法,这是最简单的替换算法。随机法完全不管Cache块过去、现在及将来的使用情况,简单地根据一个随机数,选择一块替换掉。
(2)先进先出(First In and First Out,FIFO)算法,按调入Cache的先后决定淘汰的顺序。
这种方法要求为每块做一记录,记下他们进入Cache的先后次序。这种方法容易实现,而且系统开销小。其缺点是可能会把一些需要经常使用的程序块(如循环程序)替换掉。
(3)近期最少使用(Least Recently Used,LRU)算法。LRU算法是把CPU近期最少使用的块作为被替换的块。
这种替换方法需要随时记录Cache中各块的使用情况,以便确定哪个块是近期最少使用的块。
LRU算法相对合理,但实现起来比较复杂,系统开销较大。
通常需要对每一块设置一个称为“年龄计数器”的硬件或软件计数器,用以记录其被使用的情况。
4.写操作
因为需要保证缓存在Cache中的数据与内存中的内容一致,相对读操作而言,Cache的写操作比较复杂。
(1)写直达(write through),要写Cache时,数据同时写回内存,有时也称为写通。
某一块需要替换时,不必把这一块写回到主存中去,新调入的块可以立即把这一块覆盖掉。
这种方式:实现简单,可随时保持主存数据的正确性,但可能增加多次不必要的主存写入,降低存取速度。
(2)写回(write back),CPU修改Cache的某一块后,相应的数据并不立即写入内存单元,而是当该块从cache中被淘汰时,才把数据写回到内存中。
在采用这种更新策略的cache块表中,一般有一个标志位,当一块中的任何一个单元被修改时,标志位被置为“1”,
在需要替换掉这块时,如果标志位为“1”,则必须先把这一块写回到主存中去之后,才能调入新的块;
如果标志位为“0”,则这一块不必写回主存,只要用新调入的块覆盖掉这一块即可。
这种方法的优点是:操作速度快,缺点是:因主存中的字块未随时修改而有可能出错。
(3)标记法。对Cache中的每一个数据设置一个有效位。当数据进入Cache后,有效位置“1”;而当CPU要对该数据进行修改时,数据只需要写入内存并同时将该有效位置“0”。当要从Cache中读取数据时需要测试其有效位,若为“1”则直接从Cache中取数,否则,从内存中取数。
1.3流水线
流水线技术把一个任务分解为若干顺序执行的子任务,不同的子任务由不同的执行机构负责执行,
这些机构可以同时并行工作,在任一时刻,任一任务只占用其中一个执行机构,这样就可以实现多个任务的重叠执行,以提高工作效率。
1.3.1 流水线周期
流水线应用过程中,会将需要处理的工作分为N个阶段,最耗时的那一段所消耗的时间为流水线周期。
如:使用流水线技术执行100条指令,每条指令取值2ms,分析4ms,执行1ms,则流水线周期为4ms。
1.3.2计算流水线执行时间
将1个任务的执行过程可分成N个阶段,假设每个阶段完成时间为t,则完成该任务所需的时间即为Nt。
若以传统方式,则完成k个任务所需要的时间是kNt。
使用流水线技术执行,花费的时间就是:Nt+(k-1)t。第一个任务需要完整的时间,其他都通过并行。
流水线执行时间=第一条指令的执行时间+(n-1)*流水线周期
(n表示需要处理的任务数量)
考试注意事项:流水线的执行时间计算,其实进一步可分为理论情况与实践情况两种不同的处理方式。
例:某计算机系统,一条指令的执行需要经历取值(2ms)、分析(4ms)、执行(1ms)三个阶段,
现要执行100条指令,利用流水线技术需要多长时间?
理论上,1条指令的执行时间为:2ms+4ms+1ms=7ms。
所以:理论流水线执行时间=7ms+(100-1)*4=403ms。
实际上,真正做流水线处理时,考虑到处理的复杂性,会将指令的每个执行阶段的时间都统一为流水线周期,
即1条指令的执行时间为:4ms+4ms+4ms=12ms.
所以实际流水线执行时间=12ms+(100-1)*4ms=408ms。
希赛专家提示:考试时80%以上的概率采用理论公式计算,考试时需要通过理论公式计算,如果计算的结果无正确选项,才考虑采用实际公式计算。
1.3.3流水线的吞吐率
流水线的吞吐率(Though Put rate ,TP)是指在单位时间内流水线所完成的任务数量或输出的结果数量。
有些文献也称为:平均吞吐率、实际吞吐率。
计算流水线吞吐率的最基本公式:

1.3.4流水线的加速比
在流水线中,因为在同一时刻,有多个任务在重叠地执行,虽然完成一个任务的时间与单独执行该任务相近(甚至由于分段的缘故,可能更多一些),但是从整体上看完成多个任务所需的时间则大大减少。
完成同样一批任务,不使用流水线所用的时间与使用流水线所用的时间之比称为流水线的加速比(speedup ratio)。如果不使用流水线,
即顺序执行所用的时间为T0,使用流水线的执行时间为Tk,
则计算流水线加速比对的基本公式如下:
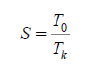
如果流水线各个流水段的执行时间都相等(设为Dt),则一条k段流水线完成n个连续任务所需要的时间为(k+n-1)Dt。
如果不使用流水线,即顺序执行这n个任务,则所需要的时间为nkDt。
因此,各个流水段执行时间均相等的一条k段流水线完成n个连续任务时的实际加速比为: