一、关键变量发掘技术(key attribute discovery techniques)
关键变量发掘技术,其实,就是从数据集中的所有数据变量中找到那些影响分类模型最大的那些关键变量。
1.两种变量是必须需要剔除的。
相关变量(redundant):如果一个变量和另一个变量高度相关,这个时候,此变量就无法给系统提供更多的信息,因此需要去掉。
不相关变量(irrelevant):如果一个变量根本就无法给系统模型提供任何信的信息,那么这个变量就是不相关变量,因此需要剔除。


二、如何解决不相关变量
• 利用统计检定可解决输入属性与目标属性不相关(Irrelevancy)的问题
• 类别性:由于目标属性是类别型属性,所以当输入属性是类别型属性时,可用
• 卡方检定来验证输入属性与目标属性间的关联性
• 数值型:当输入属性是数值型属性时和目标属性都是分类型,可用
• ANOVA检定来验证输入属性与目标属性间的关联性
注:通过训练集,仔细观察训练集,看每一个属性和目标分类属性之间的关系重要性。是否太相关,是否一点不相关。也就是说输入属性到底对目标分类属性有多重要,越重要,越要选这个输入变量,若不重要就要果断去掉该属性。
1. 若目标属性为类别性属性,输入属性也是类别性属性时,就需要用卡法检验来校验是否真的相关。
2.输入属性是数值型的,目标属性为分类型,需要用方差检验ANOVA。
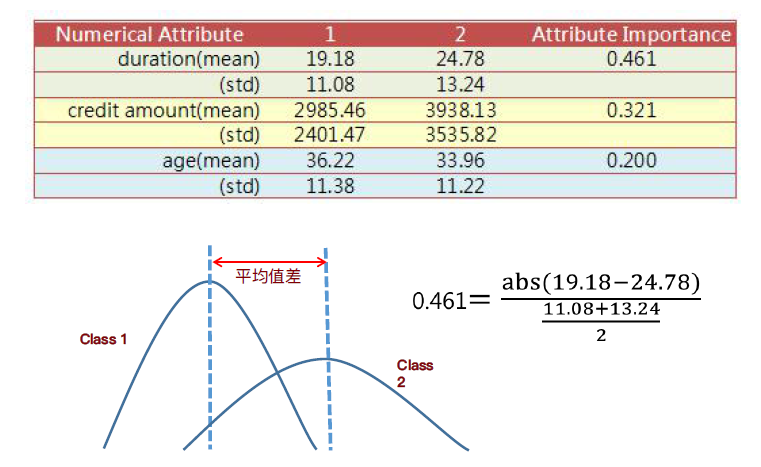
3.李御玺老师提出的属性重要性的概念(Attribute Importance)
(1)先求两个族群的均值,再求两个族群的标准差 Attribute Importance = abs(均值差)/标准差的算术平均值
均值差越大,属性重要性越大;标准差的算术平均值越小,属性重要性越大。
注:数值型的变量的Attribute Importance求值过程如下图
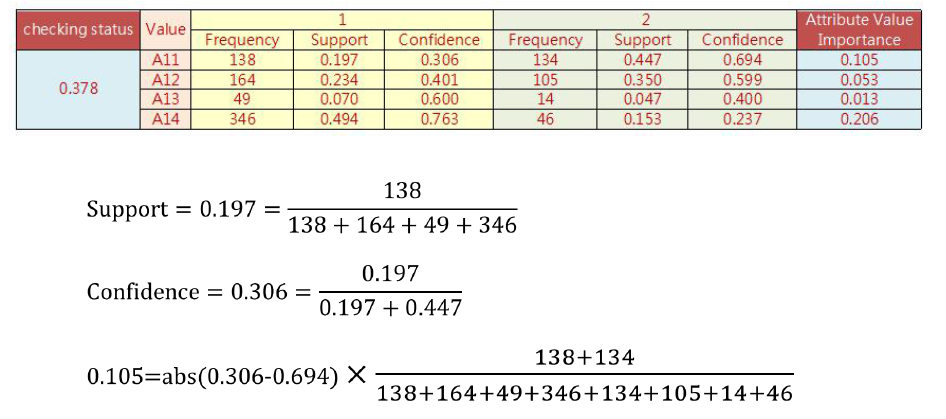
分类型变量的Attribute Importance的求值过程如下: