字符串的一些方法!
1.text.endswith(".jpg") 如果字符串是以给定子字符串结尾的,就返回值True。
2. text.upper(): 返回一个被转换为全大写字母的字符串的副本。
3.text.lower(): 返回一个被转换为全小写字母的字符串副本。
4.text.replace("tomorrow","Tuesday"): 返回一个字符串的副本,其中的某个子字符串全被替换为另一个子字符串。
5.text.strip(): 返回一个去除开始空格和结尾空格的字符串副本。
6. text.find("python"): 当找到给定子字符串时,返回子字符串的第一个字符索引值。
7.text.startswith("<HTML>") 如果字符串是以给定子字符串开头的,就返回True。
8.text[a,b] 取出字符串中以a索引值开始到b索引值结束但不包括b索引值所对应的字符的子字符串。
import urllib.request
page=urllib.request.urlopen("http://www.baidu.com")
text=page.read().decode("utf8")
print(text)
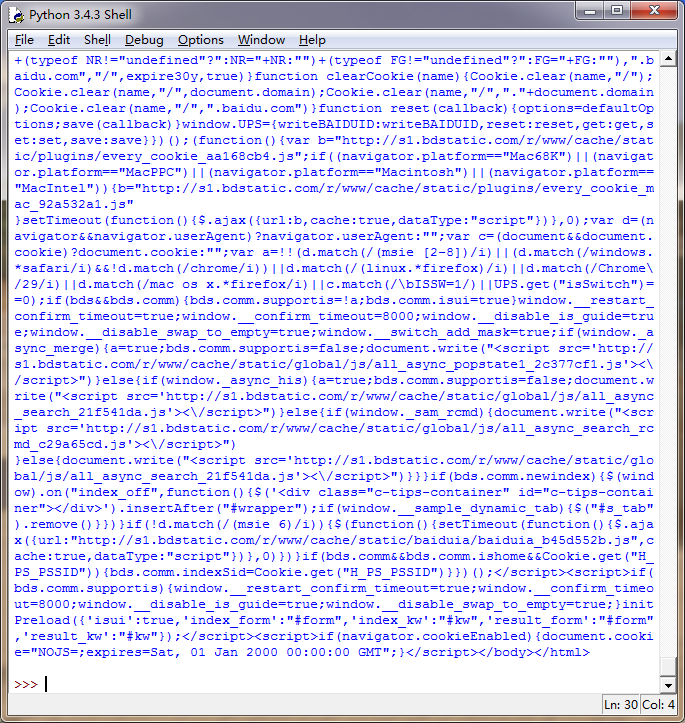
加入取出子字符串的方法之后
import urllib.request
page=urllib.request.urlopen("http://www.baidu.com")
text=page.read().decode("utf8")
price=text[234:238]
print(price)
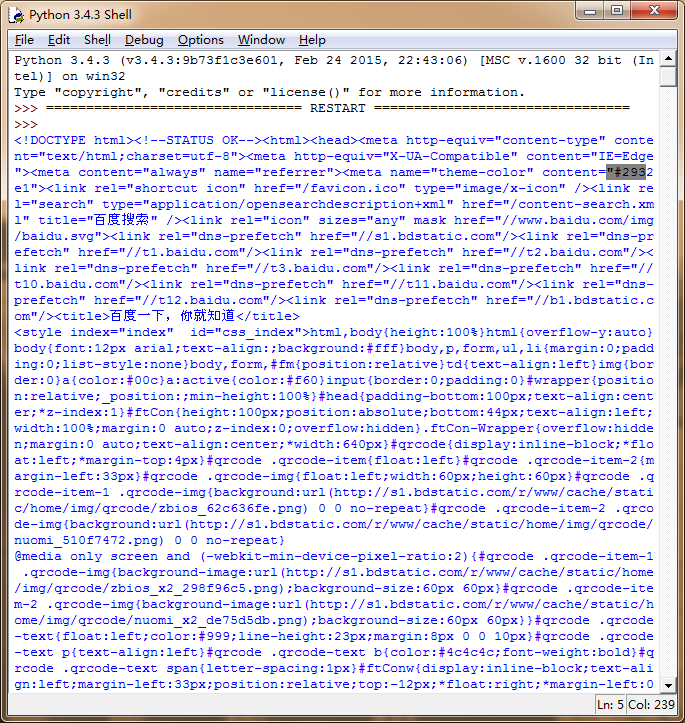
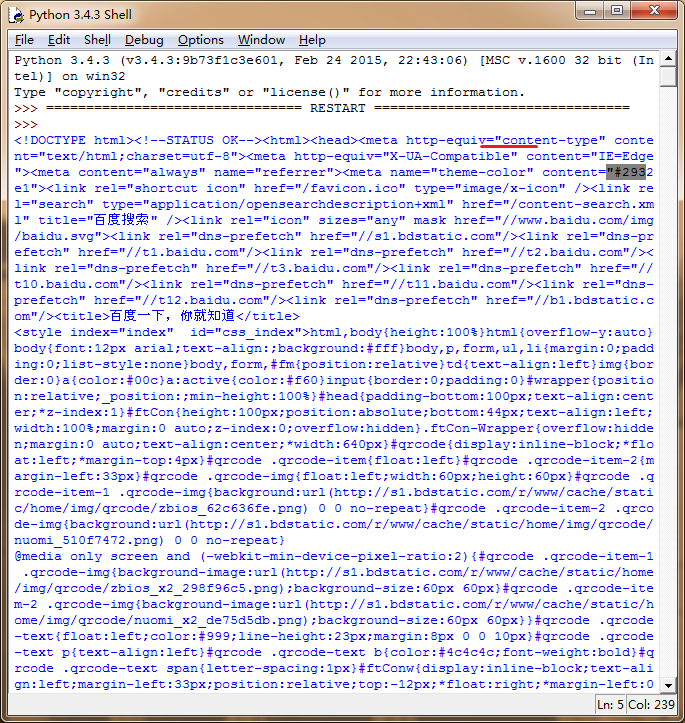
其中上图"#293的索引值分别为:234,235,236,237,238但是上述的代码所取出的结果为:
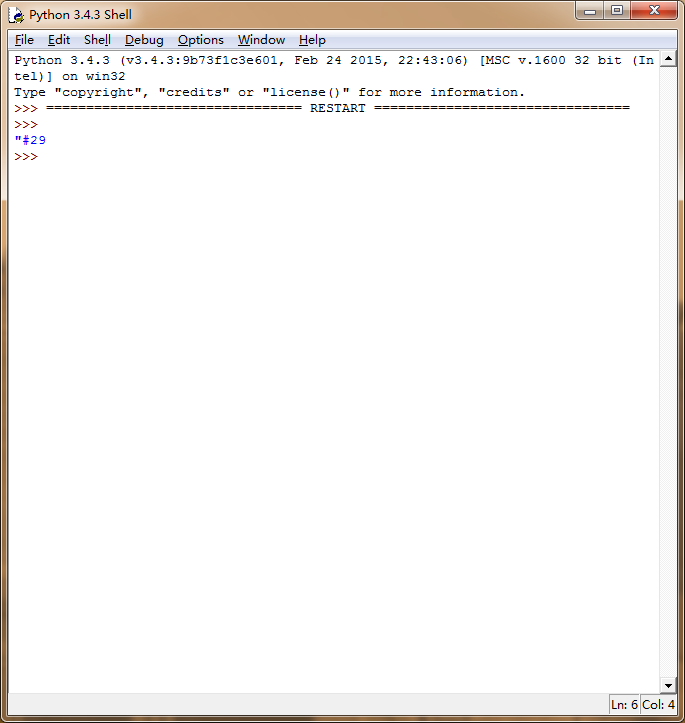
取出给定子字符串后的子字符串
import urllib.request
page=urllib.request.urlopen("http://www.baidu.com")
text=page.read().decode("utf8")
where=text.find('="')
start_of_price=where+2
end_of_price=start_of_price+4
price=text[start_of_price:end_of_price]
print(price)
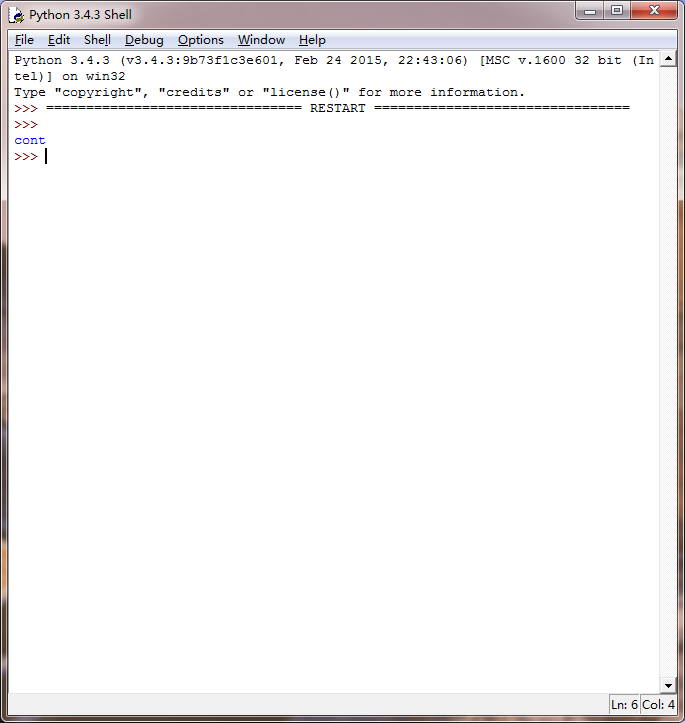
取出特定字符之后转换为float的类型与4.47进行比较,如果小于4.47就输出:Buy!
import urllib.request
price=99.99
while price>4.47:
page=urllib.request.urlopen("http://www.baidu.com")
text=page.read().decode("utf8")
where=text.find('="')
start_of_price=where+2
end_of_price=start_of_price+4
price=float(text[start_of_price:end_of_price])
print("Buy!")
Python的内置时间库
python库文档:time
time.clock() 用秒来表示的当前时间,使用浮点数格式。
time.daylight() 如果你当前不处在夏令时,就返回0.
time.gmtime() 给出UTC时间的当前日期和时刻(不受你所在时区的影响!)。
time.localtime() 给出当前本地时间(这会受到你所在时区的影响)。
time.sleep(secs) 在给定的秒数时间内休息,不做任何事。
time.time() 给出1970年1月1日算起到当前的秒数。
time.timezone() 给出你所在时区和UTC(伦敦)时区之间的相差的小时数。
import urllib.request
import time
price=99.99
while price>4.47:
time.sleep(900)
page=urllib.request.urlopen("http://www.baidu.com")
text=page.read().decode("utf8")
where=text.find('="')
start_of_price=where+2
end_of_price=start_of_price+4
price=float(text[start_of_price:end_of_price])
print("Huy!")
总结
s代表字符串。
s[4] 获得s字符串中的第5个字符。
s[6:12] 获得字符串s中的一个子字符串。(直到索引值为12的字符,但是不包括!)
s.find() 用于搜索字符串。
s.upper() 把字符串转化为全大写字母。
float() 把字符串转换成带有十进制小数的数字,也就是浮点数。
+ “加法” 操作符
> “大于” 操作符
urllib。request库用来和web沟通
time 库用于和日期/时间有关的工作!