在kubernetes中,有HPA在需要的时候创建更多的pod实例。但万一所有的节点都满了,放不下更多pod了,怎么办?显然这个问题并不局限于Autoscaler创建新pod实例的场景。即便是手动创建pod,也可能碰到因为资源被已有pod使用殆尽,以至于没有节点能接收新pod的清况。
在这种情况下,需要删除一些已有的pod, 或者纵向缩容它们,抑或向集群中添加更多节点。如果Kubernetes集群运行在自建基础架构上,那得添加一台物理机,并将其加入集群。但如果集群运行于云端基础架构之上,添加新的节点通常就是点击几下鼠标,或者向云端做API调用。这可以自动化的,对吧?
Kubernetes支持在需要时立即自动从云服务提供者请求更多节点。该特性由Cluster Autoscaler执行。
1.Cluster Autoscaler介绍
Cluster Autoscales负责在由于节点资源不足,而无法调度某pod到己有节点时,自动部署新节点。它也会在节点长时间使用率低下的情况下下线节点。
从云端基础架构请求新节点
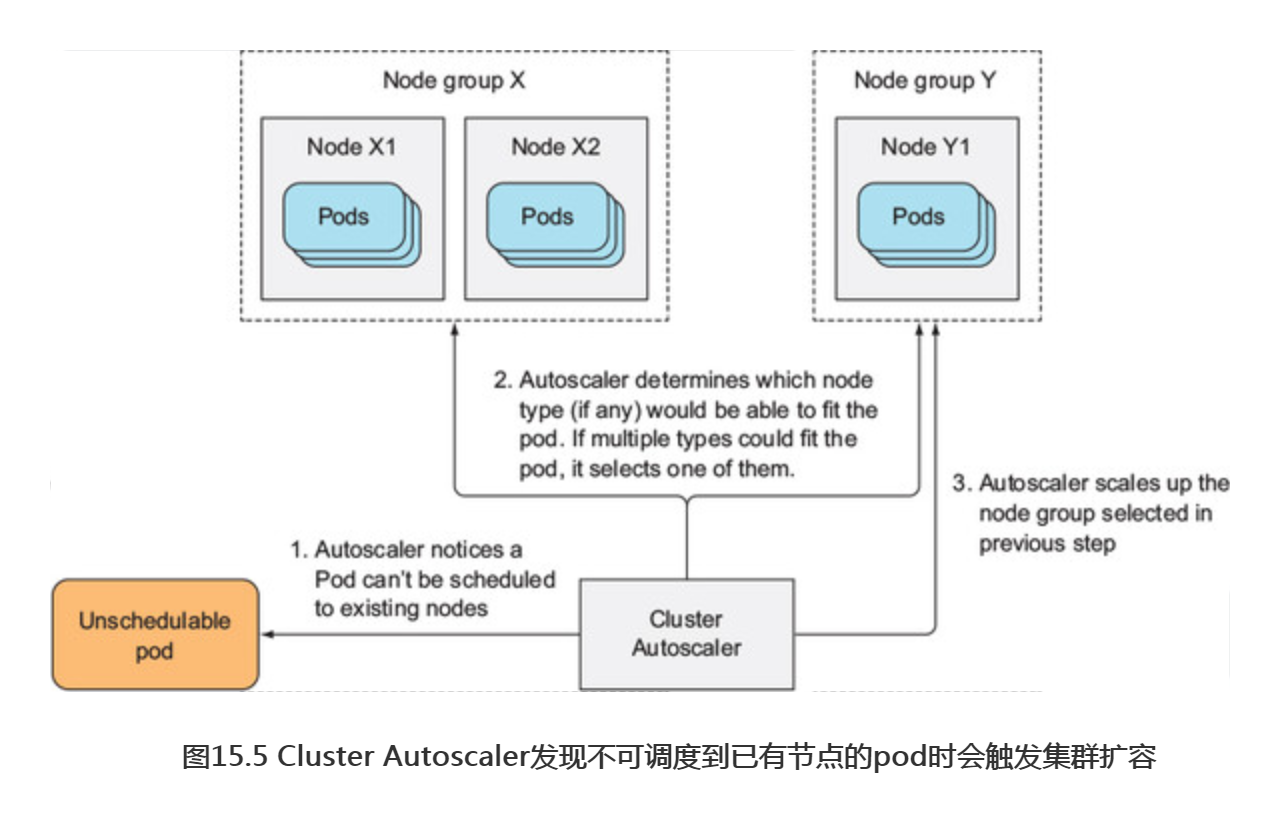
如果在一个pod被创建之后,Scheduler无法将其调度到任何一个己有节点,一个新节点就会被创建。ClusterAutoscaler会注意此类pod,并请求云服务提供者启动一个新节点。但在这么做之前,它会检查新节点有没有可能容纳这个(些)pod,毕竟如果新节点本来就不可能容纳它们,就没必要启动这么一个节点了。
云服务提供者通常把相同规格(或者有相同特性)的节点聚合成组。因此ClusterAutoscaler不能单纯地说“给我多一个节点”,它还需要指明节点类型。
ClusterAutoscaler通过检查可用的节点分组来确定是否有至少一种节点类型能容纳未被调度的pod。如果只存在唯一一此种节点分组,ClusterAutoscaler就可以增加节点分组的大小,让云服务提供商给分组中增加一个节点。但如果存在多个满足条件的节点分组,ClusterAutoscaler就必须挑一个最合适的。这里“最合适”的精确含义显然必须是可配置的。在最坏的情况下,它会随机挑选一个。图15.5简单描述了ClusterAutoscaler面对一个不可调度pod时是如何反应的。
新节点启动后,其上运行的Kubelet会联系API服务器,创建一个Node资源以注册该节点。从这一刻起,该节点即成为Kubernetes集群的一部分,可以调度pod于其上了。
简单吧?那么缩容呢?
归还节点
当节点利用率不足时,Cluster Autoscaler也需要能够减少节点的数目。Cluster Autoscaler通过监控所有节点上请求的CPU与内存来实现这一点。如果某个节点上所有pod请求的CPU、内存都不到50%,该节点即被认定为不再需要。
这并不是决定是否要归还某一节点的唯一因素。Cluster Autoscaler也会检查是否有系统pod(仅仅)运行在该节点上(这并不包括每个节点上都运行的服务,比如DaemonSet所部署的服务)。如果节点上有系统pod在运行,该节点就不会被归还。对非托管pod,以及有本地存储的pod也是如此,否则就会造成这些pod提供的服务中断。换句话说,只有当Cluster Autoscaler知道节点上运行的pod能够重新调度到其他节点,该节点才会被归还。
当一个节点被选中下线,它首先会被标记为不可调度,随后运行其上的pod将被疏散至其他节点。因为所有这些pod都属于ReplicaSet或者其他控制器,它们的替代pod会被创建并调度到其他剩下的节点(这就是为何正被下线的节点要先标记为不可调度的原因)。
手动标记节点为不可调度、排空节点
节点也可以手动被标记为不可调度并排空。不涉及细节,这些工作可用以下kubectl命令完成:
-
- kubectl cordon <node>标记节点为不可调度(但对其上的pod不做任何事)。
- kubectl drain <node>标记节点为不可调度,随后疏散其上所有pod。
两种情形下,在你用kubectl uncordon <node>解除节点的不可调度状态之前,不会有新pod被调度到该节点。
2.启用Cluster Autoscaler
集群自动伸缩在以下云服务提供商可用:
-
- Google Kubernetes Engine(GKE)
- Google Compute Engine(GCE)
- Amazon Web Services(AWS)
- Microsoft Azure
启动Cluster Autoscaler的方式取决于Kubernetes集群运行在哪。如果你的kubia集群运行在GKE上,可以这样启用Cluster Autoscaler :
$ gcloud container clusters update kubia --enable-autoscaling
--min-nodes=3 --max-nodes=5
如果集群运行在GCE上,需要在运行kubi-ub.sh前设置以下环境变量:
-
- KUBE ENABLE CLUSTER AUTOSCALER=true
- KUBE AUTOSCALER MIN NODES=3
- KUBE AUTOSCALER MAX NODES=5
可以参考https://github.com/kubemetes/auto-scaler/tree/master/cluster-autoscaler上的ClusterAutoscaler GitHub版本库,来了解在其他平台上如何启用它。
注意:Cluster Autoscaler将它的状态发布到kube-system命名空间的cluster-autoscale-status ConfigMap上。
至于很多云开启的方式去查找云平台的官方文档。
3.限制集群缩容时的服务干扰
如果一个节点发生非预期故障,不可能阻止其上的pod变为不可用;但如果一个节点被Cluster Autoscaler或者人类操作员主动下线,可以用一个新特性来确保下线操作不会干扰到这个节点上pod所提供的服务。
一些服务要求至少保持一定数量的pod持续运行,对基于quorum的集群应用而言尤其如此。为此,Kubernetes可以指定下线等操作时需要保持的最少pod数量,通过创建一个podDisruptionBudget资源的方式来利用这一特性。
尽管这个资源的名称听起来挺复杂的,实际上它是最简单的Kubernetes资源之一。它只包含一个pod标签选择器和一个数字,指定最少需要维持运行的pod数量,从Kubernetes1.7开始,还有最大可以接收的不可用pod数量。看看PodDisruptionBudget(PDB)资源长什么样,但不会通过YAML文件来创建它。将用kubectl create podDisruptionBudget命令创建它,然后再查看一下YAML文件。
如果想确保kubia pod总有3个实例在运行(它们有app=kubia这个标签),像这样创建PodDisruptionBudget资源:
$ kubectl create pdb kubia-pdb --selector=app=kubia --min-available=3 poddisruptionbudget "kubia-pdb" created
现在获取这个PDB的YAML文件,如下代码:
#代码15.10 一个podDisruptioonBudget定义 $ kubectl get pdb kubia-pdb -o yaml apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: kubia-pdb spec: minAvailable:3 #应该有多少个pod始终可用 selector: matchLabels: #用来确定该预算应该覆盖哪些pod的标签选择器 app: kubia status: ....
也可以用一个百分比而非绝对数值来写minAvailable字段。比方说,可以指定60%带app=kubia标签的pod应当时刻保持运行。
注意:从Kubernetes1.7开始,podDismptionBudget资源也支持maxUnavailable。如果当很多pod不可用而想要阻止pod被剔除时,就可以用maxUnavailable字段而不是minAvailable。
关于这个资源,没有更多要讲的了。只要它存在,Cluster Autoscaler与kubectl drain命令都会遵守它;如果疏散一个带有app=kubia标签的pod会导致它们的总数小于3,那这个操作就永远不会被执行。
比方说,如果总共有4个pod,minAvailable像例子中一样被设为3,pod疏散过程就会挨个进行,待ReplicaSet控制器把被疏散的pod换成新的,才继续下一个。