1.现象
结论见 《kubernetes ingress-nginx 启用 upstream 长连接,需要注意,否则容易 502》。nginx 的访问日志间歇性出现 502 响应,查看 nginx 的 error.log,发现是 upstream 返回了 reset:
2019/06/13 04:57:54 [error] 3429#3429: *21983075 upstream prematurely closed connection while reading response header from upstream, client: 10.19.167.120, server: XXXX.com, request: "POST XXXX HTTP/1.0", upstream: "http://11.0.29.4:8080/XXXXXX", host: "XXXX.com" 2019/06/13 04:58:34 [error] 3063#3063: *21989359 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 10.19.138.139, server: XXXX.com, request: "POST /api/v1/XXXX HTTP/1.1", upstream: "http://11.0.145.9:8080/api/v1/XXXX", host: "XXXX.com"
2.调查
在 nginx 上抓包,nginx 向 upstream 发送请求后,upstream 直接返回 reset,nginx 回应 502,触发 reset 的请求的发送时间比上次晚了 1 分钟以上:

检查其它正常响应的连接,发现服务端会在连接闲置 1 分20 秒的时候,主动断开连接:

奇怪的是 nginx 设置的 keepalive_timeout 为 60 秒,为什么不是 nginx 主动断开连接?
3.验证第一个假设:服务端 idle 先超时会引发 reset
猜测 upstream 对应的服务端也设置了超时时间,并且比 nginx 先超时,因此出现了服务端率先断开连接情况。如果服务端断开连接时,nginx 正好向 upstream 发送了请求,就可能出现 reset 的情况。
部署一个服务端容器,服务端的 idle 超时设置为 10 秒,小于 nginx 中配置的 keepalive_timeout (60秒)。用 httpperf 模拟 100 个会话,每个会话以每间隔 9 秒发送 100 个请求的方式累计发送 300 个请求,会话创建速率是每秒 10 个。
httperf --server webshell.example.test --port 80 --wsess 100,300,9 --burst-len 100 --rate 10
./httperf --server webshell.example.test --port 80 --wsess 1,256,9 --burst-len 128 --rate 1
遗憾的是 httperf 太老旧支持的量太少,没能复现出来。假设的场景本身也很难复现,必须恰好在连接因为超时关闭时发送请求,比较难复现。
另外找到三篇文章都在讨论这个问题:
1.104: Connection reset by peer while reading response header from upstream
3.Analyze ‘Connection reset’ error in nginx upstream with keep-alive enabled
4.发现新情况
有用户反应能够稳定复现 502,且是在压测期间发现的,这就奇怪了。idle 超时导致的 502 应该很难出现,能稳定复现 502 肯定是有其它原因。
在继续调查的过程中,首先想到的是「长连接中的最大请求数」,服务端会不会设置了单个连接中能够处理的请求数上限,并且该上限小于 nginx 中的配置?
公司的业务系统主要是 tomcat 服务,因此优先调查 tomcat 的配置,发现了下面的参数:

tomcat 默认每个连接中最多 100 个请求,而 nginx 中配置的 keepalive_requests 超过了 100,这会不会是问题根源?需要测试验证一下。
同时发现 tomcat 默认的 idle 超时时间是 60s,和前面提出的超时假设能够相呼应,tomcat 7 和 tomcat 8 的使用的是相同的默认配置。Tomcat Config。


5.验证第二个假设:服务端率先断开连接导致502
部署一个 tomcat 服务,idle 超时时间为 60s,maxKeepAliveRequests 为 100,nginx 的 idle 超时为 60s,keepalive_requests 为 2000,用下面的命令压测:
./wrk -t 4 -c 10000 -d 90s http://ka-test-tomcat.example.test/ping
10000 并发压测 90s 时,出现 502 响应:
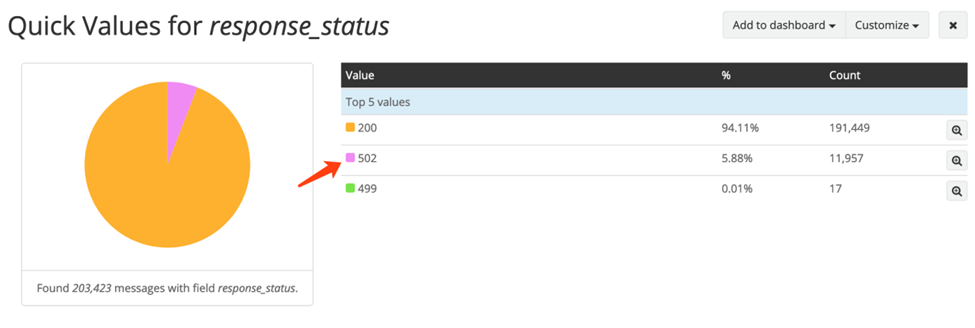
然而从报文发现:服务端直接 reset 的连接数是 24 个,数量远远低于 502 响应的数量。
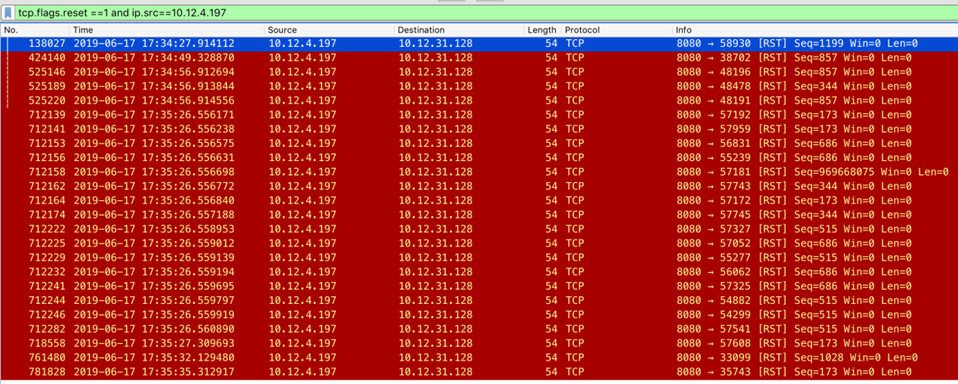
怀疑还有其它原因,检查 nginx 发现大量下面的日志:
2019/06/17 09:35:46 [crit] 28805#28805: *9114394 connect() to 10.12.4.197:8080 failed (99: Cannot assign requested address) while connecting to upstream, client: 10.10.173.203, server: ka-test-tomcat.example.test, request: "GET /ping HTTP/1.1", upstream: "http://10.12.4.197:8080/ping", host: "ka-test-tomcat.example.test" 2019/06/17 09:35:46 [crit] 28806#28806: *9114649 connect() to 10.12.4.197:8080 failed (99: Cannot assign requested address) while connecting to upstream, client: 10.10.173.203, server: ka-test-tomcat.example.test, request: "GET /ping HTTP/1.1", upstream: "http://10.12.4.197:8080/ping", host: "ka-test-tomcat.example.test" 2019/06/17 09:35:46 [crit] 28804#28804: *9114172 connect() to 10.12.4.197:8080 failed (99: Cannot assign requested address) while connecting to upstream, client: 10.10.173.203, server: ka-test-tomcat.example.test, request: "GET /ping HTTP/1.1", upstream: "http://10.12.4.197:8080/ping", host: "ka-test-tomcat.example.test"
统计了一下,crit 日志数和 502 响应的数量级相同,断定本次压测中产生大部分 502 是 nginx 上的端口不足导致的,又发现了一种导致 502 原因:nginx 的端口耗尽 。
尝试降低并发数量,排除端口耗尽的情况:
./wrk -t 4 -c 500 -d 300s http://ka-test-tomcat.example.test/ping
结果比较悲催,无论如何也没有 502,检查报文发现有少量服务端回应的 RST 报文,是在发起了 FIN 连接后再次回应的。而在多次压测过程中,又的确出现过两次总计100多条的 104: Connection reset by peer日志,但就是复现不出来,不知道是它们在什么情况下产生的……
6.新的发现
有点陷入僵局,回头审视反应能够稳定复现 502 的用户的系统,最后一个请求与上一个请求的间隔时间是 2 秒。

这个 2 秒的时间差一开始带来了困扰,也正是这个 2 秒的时间差,让我怀疑之前的超时断开假设不成立,调头去查 maxKeepAliveRequests 的问题。
进入用户的系统后,发现后端服务是用 Gunicorn 启动的 python 服务,查阅 Gunicorn的配置,发现它默认的 keepalive 时间是 2秒,正好和报文中的情况对应。

也就是说,能够稳定复现的 502 也是因为服务端先触发 idle 超时,之所以能够稳定触发,因为后端服务的配置的超时时间只有 2秒,而请求端又恰好制造出静默两秒后发送下一个请求的场景。
超时断开应该比超过 maxKeepAliveRequests 断开更容易引发 502,因为超过 maxKeepAliveRequests 时,会在最后一个请求结束后立即发送 FIN 断开连接,不容易与 nginx 正在转发的请求「撞车」,而超时断开可能在任意时刻发生,可能正好是 nginx 收到新的请求的时候,转发新请求时与服务端关闭连接的操作「撞车」。
7.初步结论
根据日志和原理进行推测,提出两个可能有效的方案:
1.nginx 的 keep-alive 的 idle 超时要小于 upstream 的 idle 超时;
2.nginx 的 keepalive_request 要小于 upstream 的相关设置。
以上两个配置可以保证连接断开都是 nginx 发起的,从而可以避免向一个已经关闭的连接发送请求。
8.转载
https://www.lijiaocn.com/%E9%97%AE%E9%A2%98/2019/06/13/nginx-104-reset.html#本篇目录